
This Week in Neo4j – Start Your Graph

Senior Developer Marketing Manager
4 min read

This first real Twin4j of 2022 again covers a wide range of topics we think will be interesting to you. Are you wondering what’s the most fun way to get your data in Neo4j? If you ask Samuel Longley, he will tell you ETL is the way to go and has started a blog series to prove his point.
If you are a Data Scientist on the other hand and want to boost your data retrieval from Neo4j, Tomaz Bratanic shows you how to do that.
We are currently conducting our 2021 Neo4j Developer Survey. Please take a few minutes and fill it in! We will raffle away a few Neo4j goodie bags among all participants!
Enjoy this week’s edition of Twin4j.
Andreas & Alexander
Featured Community Member: Rhys Evans
Rhys Evans – This Week’s Featured Community Member
Rhys helps make sense of a “spaghetti monster of services” which use different languages, deploy pipelines, monitoring tools, and more, by modeling it as a graph stored in Neo4j and accessed through GraphQL. With that in place, everyone involved knows how things fit together, and new services can be created for org-wide uses like fulfilling GDPR obligations.
More than that, his engaging 61 Boring Birds blog series is a delightful read – a welcome reminder to get outside, look beyond our screens, and take a fresh breath at a socially responsible distance.
Thanks for the inspiration, Rhys! I do wonder what these bird are flitting around the Swedish coast.
Optimize Fetching Data from Neo4j with Apache Arrow
Tomaz Bratanic shows us in this blog post how to optimize data fetching from Neo4j with Apache Arrow. While Neo4j has a Graph Data Science library that supports multiple graph algorithms and machine learning workflows, sometimes you want to export data from Neo4j and run it through your favorite machine learning frameworks like PyTorch or TensorFlow. The goal of the Neo4j Arrow project is to expose data available in Neo4j via high-performance Arrow Flight APIs.
Social Recommendations – Slack, Neo4j, and NeoDash
David Stevens wondered if he could combine Slack data and present something useful in NeoDash. In this blog post, he analyzes a small social network graph to identify common groups between people. NeoDash is an excellent tool to quickly create PoC’s or prototyping dashboards with no real coding required – just the same Cypher query knowledge used to import the data.
Read the Article
Doctor.ai, an AI-Powered Virtual Voice Assistant for Healthcare
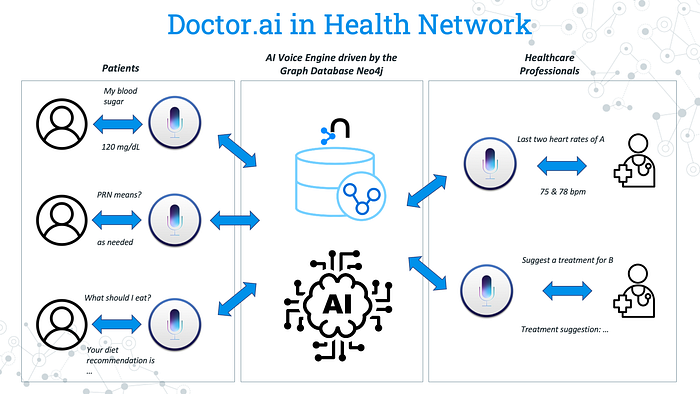
Sixing Huang has put together Neo4j, AWS, and the eICU dataset to build a small virtual voice assistant called Doctor.ai. Although it can fulfill only a limited set of inquiries in its current form, it is not hard to see its enormous potentials in healthcare – it can be used in the ICU, psychiatric clinics, and dentists. By changing the underlying data, it can even be made into a general purpose Q&A chatbot for other industries.
Apache Hop, a Quick Introduction

For Samuel Longley, using ETL is the most fun way to load data into Neo4j. You can break up your work into discrete pieces of work, more easily develop, build, and test your routines, connect to different sources and targets, scale up, and put your work into production. To guide people through this process, he recently started writing a series of posts to explain how to get started with Apache Hop and load data to Neo4j. Apache Hop is free and open-source software (“FOSS”) and recently graduated from the Apache incubator program and is now a top-level project at the Apache Software Foundation.
Neo4j Live – Code Wars: Database Decisions for Application Development

In this video, Jennifer Reif explains how to go from relational to NoSQL to graph. She explores various types of data, the way it is stored, and how best to go about retrieving it.
Tweet of the Week
Our favorite tweet this week was by Chuck Baggett:
Horror sci-fi: Your digital twin gets better engagement than you and then finds a way to put you in the computer while it enters reality and your loved ones think something great has happened to you and think what seems to be your digital twin sucks so they delete it.
The end. https://t.co/ijFveU7cBN
— @ChuckBaggett Chuck Baggett- No god no government (@ChuckBaggett) January 7, 2022
Don’t forget to RT if you liked it too!
Share Article



Explore
Related Articles

This Week in Neo4j: GraphRAG, GraphAcademy, Knowledge Graphs, Symfony and more

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more


