
This Week in Neo4j – Why Kettle?, Pokémons in a Graph, Influencers in the Graph Community

Developer Relations Engineer
3 min read

This week Igor Rozani taught us about the pokémon universe in a fun online meetup, Andrea Santurbano showed how easy it is to produce and consume Kafka data streams in Cypher, and Tomaz Bratanic explored the Depth First Search algorithm.
Elsewhere Jennifer Reif dived into the world of data import and asked why you’d use Kettle for data import, and I went extremely meta in analysing the Twitter network of the Graph Database community.
Featured Community Member: Mayank Gupta
Our featured community member this week is Mayank Gupta, a Certified Neo4j Developer and student at Netaji Subhash Engineering College in Kolkata, India.
Mayank Gupta – This Week’s Featured Community Member
After using Neo4j for one year, Mayank started creating Neo4j tutorial videos in Hindi, the national language of a 1.2 billion populated country. His Code House YouTube channel already has 500+ subscribers, and he recently a playlist dedicated to Neo4j.
With so many different languages in the world, it makes it difficult to make everything accessible to everyone. We are very grateful to have people like Mayank who help eliminate many of those obstacles.
Thank you, Mayank, for your contributions to your local community!
The Mega Evolution of Pokémons in a Graph
In this week’s Neo4j Online Meetup, Igor Rozani educated us about pokémons using graphs.
Igor shows us a web scraper he built to load the pokémon universe in Neo4j and then explores the data using Cypher queries. He also shares his experience learning about graph modelling and we discuss different data import approaches.
How to produce and consume data streams directly via Cypher with Streams Procedures
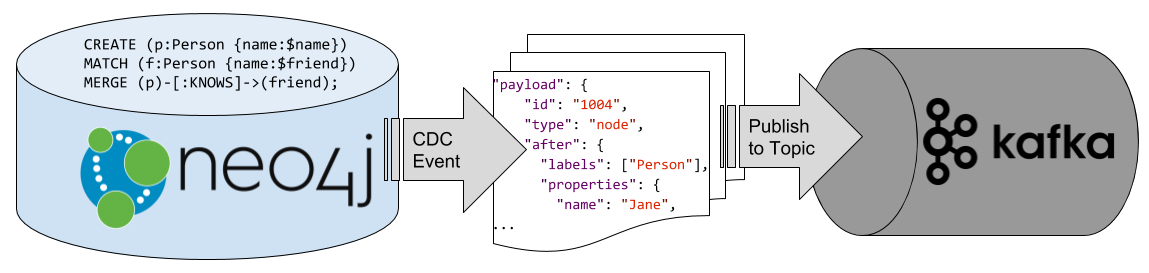
In the 3rd part of his Leveraging Neo4j Streams series, Andrea Santurbano shows how to bring Neo4j into your Apache Kafka flow using the streams procedures provided by the Neo4j Streams Library.
Using Apache Zeppelin notebooks, Andrea takes us through a worked example where we learn how to write Cypher queries to publish and consume Kafka events.
Finding influencers and communities in the Graph Community

I wrote a blog post showing how to use algorithms from the Neo4j Graph Algorithms Library to explore the Twitter graph of users in the Graph Database community.
We use two two types of algorithms:
- The Degree Centrality, Betweenness Centrality, and PageRank centrality algorithms to find users with different types of influence.
- The Louvain Modularity community detection algorithm to find sub communities of users, including GraphQL, the Semantic web, and Neo4j.
Depth First Search on the Tube, Relationships vs Properties, Intro to Neo4j Slides

- Tomaz Bratanic shows how to use the Depth First Search algorithm in the Neo4j Graph Algorithms Library to explore the London Tube Network.
- Stephan Pirnbaum shared the slides from his Introduction to Neo4j talk from the Neos Conference.
- I wrote a blog post showing how to create a node based on a subset of keys in a map.
- Dominic Kumar explores the performance differences between “Relationship as Types” vs “Relationship as Properties”.
Why Choose Kettle for Neo4j Data Import?

After completing her epic Marvel Series, Jennifer Reif is now exploring Neo4j data import tools, starting with Kettle, an open source ETL tool.
Jennifer gives some background on the project, its Neo4j integrations, and explains why you might choose this method of import over LOAD CSV, APOC, or Cypher.
Tweet of the Week
My favourite tweet this week was by Gunnar Morling:
Great talk on everything @apachekafka Connect by the inimitable @rmoff. Loving his zero-code demo of a data streaming pipeline from #MySQL (via #Debezium) to #Elasticsearch and #Neo4j. Really well done, including some unexpected yet successful live failure fix ? pic.twitter.com/GSVdeLk0HA
— Gunnar Morling ?? (@gunnarmorling) May 14, 2019
Don’t forget to RT if you liked it too.
That’s all for this week. Have a great weekend!
Cheers, Mark
Share Article



Explore
Related Articles

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more



