
This Week in Neo4j – Will it Graph, Python Database Backups, Knowledge Graphs, Kinesis, and Kanye West

Data Science Advocate
7 min read

Hello, everyone!
It’s August and many of us are thinking about taking a restful break from work for the month, or perhaps returning our kids to school. However, our community members are hard at work generating some
great things with Neo4j!
This week, we’re taking the opportunity to highlight Katerina Baousi, who gave an excellent talk at NODES 2021 on looking at Twitter trolls using Neo4j. We also have posts ranging from identifying graphy problems and using temporary graphs for unit testing to how to go from AWS Kinesis to Neo4j in Spark. There’s also an article showing how NASA is using knowledge graphs to manage people, skills, and projects. Lastly, you will not want to miss the fun of going through the Six Degrees of Kanye West!
Featured Community Member: Katerina Baousi
This week’s featured community member is Katerina Baousi.
Katerina Baousi – This Week’s Featured Community Member
Katerina is a solutions engineer at
Cambridge Intelligence. She has a great deal of skill in a broad variety of areas, including web
development and data visualization. Her work at Cambridge Intelligence is focused on the KronoGraph tool for exploring timeline analysis within graph data. She also gave an excellent talk at NODES 2021 on Timeseries Visualization of Social Networks with Neo4j.
Will It Graph? (Part 2)

In this episode of GraphStuff.FM, Neo4j’s own Lju Lazarevic and William Lyon present information on how to identify whether you have a “graphy” problem and how to know whether a graph database is the right fit for your problem. This is the second part of a series on the topic. Part 1 can be found here.
One key indicator they discuss is that having a lot of JOINs in a typical workflow is a big hint that you may have a graphy problem, since multi-hop traversals can be expensive. This is particularly beneficial when you don’t know how many connections you are interested in at query time (i.e. a variable-length graph traversal). Some examples that they provided include fraud detection and network and IT management.
A New Tool to Back Up a Neo4j Database with Python
Are you interested in downloading and uploading data into a Neo4j database where using dump files is not an option? Would you like to be able to store your data in different formats, thus allowing, say, easily changing which version of Neo4j you are using? Would you like an open source Python package that is capable of doing so, installable via pip? Then check out the code that Andres Hyer has written to do just that. You can use it on AuraDB, with Docker, via the command-line, or pretty much any way you want. Check it out!
NODES 2021 Extended: Semantic AI Platform; What is the Theta Base

We are now in full swing with the NODES 2021 extended talks, which build off the excitement from NODES 2021 with even more high-quality talks.
So we are taking the opportunity to highlight the talks of two users. The first is Siddharth Karumanchi, founding research scientist at QUIPI, who presented a talk entitled “Semantic AI Platform.” The goal of this work is to present the context for enterprise domain knowledge in a convenient way. He showed how to semantically enrich a knowledge graph to aid in text mining and natural language processing problems like entity extraction and disambiguation.
The second talk was presented by Elias Moosman, co-founder of Youiest, who discussed the Theta Base. In this talk, he shared how pulling together thought, data, and ownership can be used to create apps around measuring and influencing employee engagement. This looks at how intentions and values for an organization interact with both positive and negative correlation, managed with Neo4j.
How NASA is Using Knowledge Graphs to Find Talent

Continuing their tradition of actively using Neo4j, NASA has detailed their use of a talent mapping database to show the relationships between people,
skills, and projects in a knowledge graph.
Senior data scientist David Meza described this work to Venture Beat. The aim is to look at identifying things like skills, tasks, and technology within a work role and translate that to employees for things like connecting around training around NASA-specific competencies. It will hopefully give the
employees an opportunity to explore how to further their careers and better align people
across the organization.
(from:Kinesis)-[:VIA_SPARK]→(to:Neo4j)

Are you interested in streaming large amounts of real-time data into Neo4j? Davide Fantuzzi of LARUS has written a blog post on how to
use the Neo4j Spark connector to get an AWS Kinesis Data Stream into a Neo4j database. This post includes a complete demonstration of how to set up a proper IAM user, the Kinesis Data Stream, and the Kenesis Data Generator in preparation for data ingested into Neo4j. He then provides the reader with a Docker container that runs an Apache Zeppelin notebook, allowing you to tinker with Spark and Neo4j and then finally explore the graph in the Neo4j browser.
Six Degrees of Kanye West
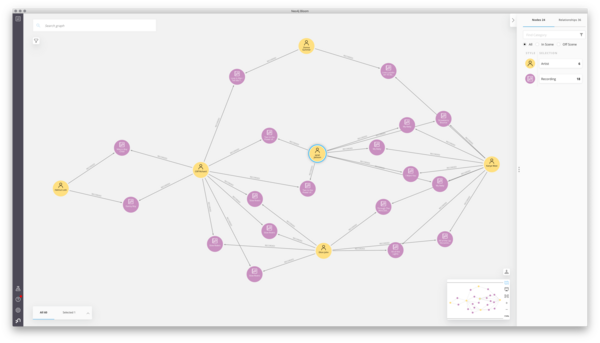
Have you ever wanted to be able to calculate the “Kanye Number” for a given artist? Admit
it… you have! Neo4j’s own Rik Van Bruggen has written a blog post showing you how (in part 3/3 of this series). Using the data available from Musicbrainz, he has created a
fun demo that demonstrates the power of graph databases with some basic Cypher queries to get you
started. There are plenty of worked Cypher examples, including calculating the Kanye Number or finding recordings with the most artists, and it concludes with a nice Bloom demonstration.
Tweet of the Week
My favorite tweet this week was by BoardGameGeek:
Fun to watch the BGG data get put into Neo4j! If you want to use an average that takes into consideration the number of ratings, use the bayes_average_rating (Bayesian Average). This could be quite interesting if the underlying properties of games could be added also. https://t.co/HMXvb5c3XJ
— BoardGameGeek (@BoardGameGeek) August 3, 2021
Don’t forget to RT if you liked it too!
Share Article



Explore
Related Articles

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more



