
This Week in Neo4j – World Cup Graph and GraphQL API, Tuning Cypher Queries, Querying Spatial datapoints

Developer Relations Engineer
5 min read

Welcome to this week in Neo4j where we round up what’s been happening in the world of graph databases in the last 7 days.
This week we have the World Cup Graph and GraphQL API, an article explaining how to tune Cypher queries by understanding cardinality, querying Spatial data points, and the Intro to Graph Databases YouTube series is back!
Featured Community Member: Bea Hernández
This week’s featured community member is Bea Hernández, Data Scientist at DATMEAN.
Bea Hernández – This Week’s Featured Community Member
Bea is part of the Neo4j community is Madrid as well as being the organiser of R-Ladies Madrid and a member of the NASADatanauts.
Bea presented Neo4j gRaphs at a combined R-Ladies and Neo4j Madrid meetup in February in which she showed how to analyse and visualise Neo4j data in R.
This week DATMEAN were accepted into the Neo4j startup program so Bea will get to work on Neo4j even more.
Wohooo!! We have been accepted in the @neo4j startup program!! We have a HUGE project in front of us filled with graphs! ?? pic.twitter.com/JTwrFb9tbs
— Bea. (@Chucheria) June 19, 2018
All of us in the DevRel team are excited to hear about your experiences, perhaps at a future GraphConnect or Neo4j event.
On behalf of the Neo4j community, thanks for all your work Bea!
The World Cup Graph
We’re well into the 2nd round of matches at World Cup 2018 and Michael and I decided to revive the World Cup Graph that we first created 4 years ago. The dataset contains the matches, players, and tournaments for every World Cup from 1930 to the present day.
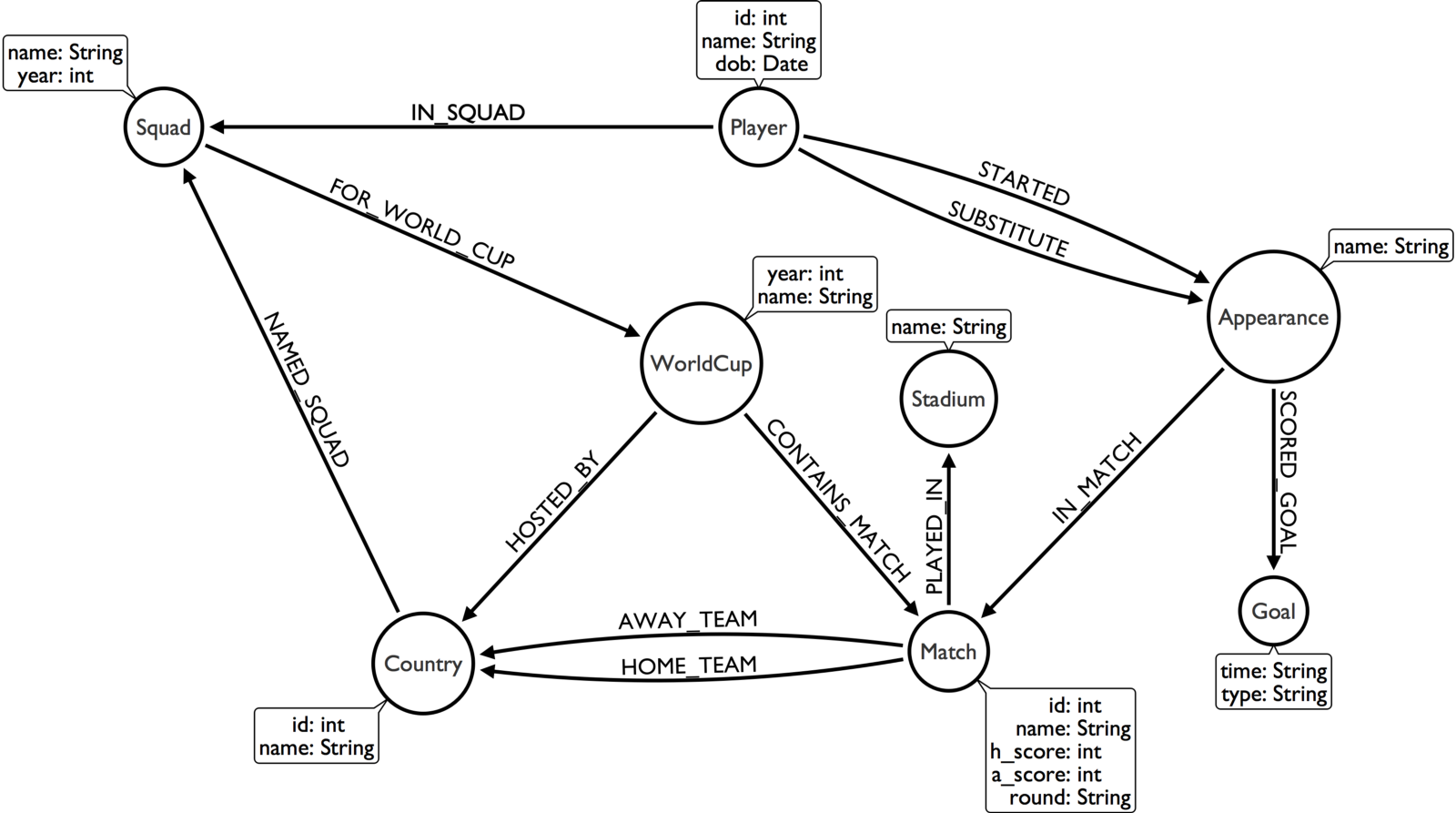
If you want to play around with the data we have a hosted version on a Neo4j Cloud instance at c27d992b.databases.neo4j.io. You can login with the username worldcup and password worldcup and then run :play worldcup-2018-queries for a guide that will show you some queries you can run against the dataset.
World Cup GraphQL API

To make the data accessible to people not yet fluent with the Cypher query language we also created a GraphQL API on top of the database. You can find that at worldcup-2018.now.sh.
This only took us a few hours thanks to the excellent GRANDstack Starter Kit. All the scaffolding had been done for us – all we had to do was fill in details about our database and create a GraphQL schema.
GRANDstack Hackathon
The World Cup GraphQL API and UI starter can be the foundation for your contribution to the GRANDstack Hackathon which still runs till June 30 and has some cool prizes.

Another set of GraphQL APIs that you can use, is running on top of our graphql community graph. My colleague Michael added these developer community APIs.

Each of these APIs is available as a separate branch of the grand-stack-starter project.
Michael describes the approach on the GRANDstack blog.
So make sure to submit your entry to the GRANDstack Hackathon by the end of the month and get a cool Brik Laptop Cover.
Intro to Graph Databases Episode #5 – Cypher, the Graph Query Language
Based on popular demand, Ryan this week resumed the Intro to Graph Databases YouTube series with a video explaining the Cypher query language.
Ryan starts by explaining how the developer surface of Neo4j has evolved over the years, from the embedded Java API, via the REST API, up to the present day of Bolt drivers and stored procedures and functions executed via Cypher.
You can find the full series of videos as part of a YouTube playlist.
Querying Spatial data points, The Strava Graph, Cypher snippets
- Last week we featured a blog post where Rik showed how to import the Open Beer Database along with Spatial data points, and in this week’s blog post he shows how to write queries against this new data type.
- For those runners out there I’ve written a couple of posts showing how to import your data from the Strava API into Neo4j and then query it via the newly released Py2neo.
- Krishnaraj Rajagopal shared some useful Cypher snippets – get label count and get label-relationship count.
- Sander Robijns wrote a blog post in which he explains the role that graph data modeling plays in a data modeler’s toolbox.
- On StackOverflow Fillard Millmore explained how to update nodes in an existing database based on data in CSV file.
Tuning Cypher queries by understanding cardinality

This week from the Neo4j Knowledge Base we have an entry by Andrew Bowman that explains how to tune Cypher queries by understanding cardinality.
Andrew starts with a high level overview of how Cypher execution works, and then takes us through a worked example from the in built movies dataset, showing various tricks to improve the performance of the query.
If you’ve ever wondered why your queries aren’t doing what you expected them to this is a great post to read.
Projects to play with: Knowledge Graph, Mortality Explorer, RDF → Graph

On my GitHub travels I came across a few interesting projects that you can take a look at if you get some time over the weekend.
- neo4j-knowledge-graph – an example of a simple, queryable knowledge graph implemented using Neo4j that can be used with Microsoft’s LUIS NLU or google’s Dialogflow.com NLU.
- mortality – a bit of a morbid dataset containing causes of deaths in the USA.
- rdf2neo – a tool to convert and load RDF into Neo4j.
Next Week
What’s happening next week in the world of graph databases?
| Date | Title | Group | Speaker |
|---|---|---|---|
|
June 27th 2018 |
Driving Insights Out of Connected Data to Transform Project Management |
Tweet of the Week
My favourite tweet this week was by Tunisian Gunner:
I can tell you that neo4j will change your life forever as you will really enjoy playing with your data in graph models. Well you can also get instatnt help on slack from fellow developers.!
— Tunisian Gunner (@HamzaGunnner) June 20, 2018
Don’t forget to RT if you liked it too.
That’s all for this week. Have a great weekend!
Cheers, Mark
Share Article



Explore
Related Articles

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more



