
This Week in Neo4j – 25th February 2017

Developer Relations Engineer
5 min read
Welcome to this week in Neo4j!
From now on instead of covering everything that happened in Neo4j at the end of the month in one mega-post we’re going to publish a more focused update once a week.
We hope you like it and if you have any ideas/feedback for future versions please send us an email – devrel@neo4j.com.
Featured Community Member: Andrew Bowman
If you ask a question with the neo4j tag on StackOverflow the chances are that you’ll get a reply from Andrew Bowman, a.k.a. InverseFalcon. Andrew has answered 79 questions in the last 30 days and is currently 14th on the list of top users on the neo4j tag. He’s also extremely active on the Neo4j Discord channel and if you’ve ever asked a question about APOC or Cypher you’re sure to have come across him.
We’d like to thank Andrew for his amazing contribution to the Neo4j community and for jumping in to help so many users.
New Neo4j Online Meetup
We had the return of the Neo4j Online Meetup on 15th February where Michael Hunger showed us all how to explore Buzzfeed’s TrumpWorld dataset.
Our next online meetup is on 2nd March at 17.00 UTC and will feature Jesús Barrasa talking about his experiences in the RDF and graph worlds. We hope you can join us.
If you’re keen to attend the online meetup but the time doesn’t work for you let us know at devrel@neo4j.com – if we have enough interest, we can schedule events at a time friendlier for other time zones.
Don’t forget to subscribe to the Neo4j YouTube channel to get notified about future videos.
Introducing the Neo4j Sandbox
If you’ve always wanted to play around with Neo4j but haven’t got around to downloading it, you can get up and running quickly with the Neo4j Sandbox.
In a few minutes you’ll have your own hosted Neo4j instance with built-in guides and sample datasets for popular use cases.
Neo4j in Forbes
Neo4j was featured in Forbes! NASA’s Chief Knowledge Architect David Meza explains how his team have used Neo4j to make it easier for NASA engineers to find the information they’re looking for by connecting related topics in the company’s Lessons Learned database.
David spoke at GraphConnect San Francisco 2016 where he describes NASA’s Knowledge Graph in more detail.
Use Spring, Elixir, or JetBrains IDEs?
- Jilles van Gurp released spring-depend, a tool for analyzing Spring dependencies using Neo4j.
- Florin Patrascu released v0.2.1 of Bolt.Sips, the Elixir driver for Neo4j. This release contains a couple of bug fixes – one to not retry requests if there’s been an internal driver error, the other to handle large streams of data.
- Dmitrijs Vrublevskis released v2.4.0 of the GraphDB JetBrains plugin. This release introduces support for Cypher code reformatting, validates function arity + types, and shows parameter information for functions and parameters.
Community Experiments
On the Developer Relations team, we like to experiment with various features for the Neo4j Browser and gather feedback on them. If the community loves any particular features, we’ll work with the product management team to share feedback and hopefully get them into the core product.
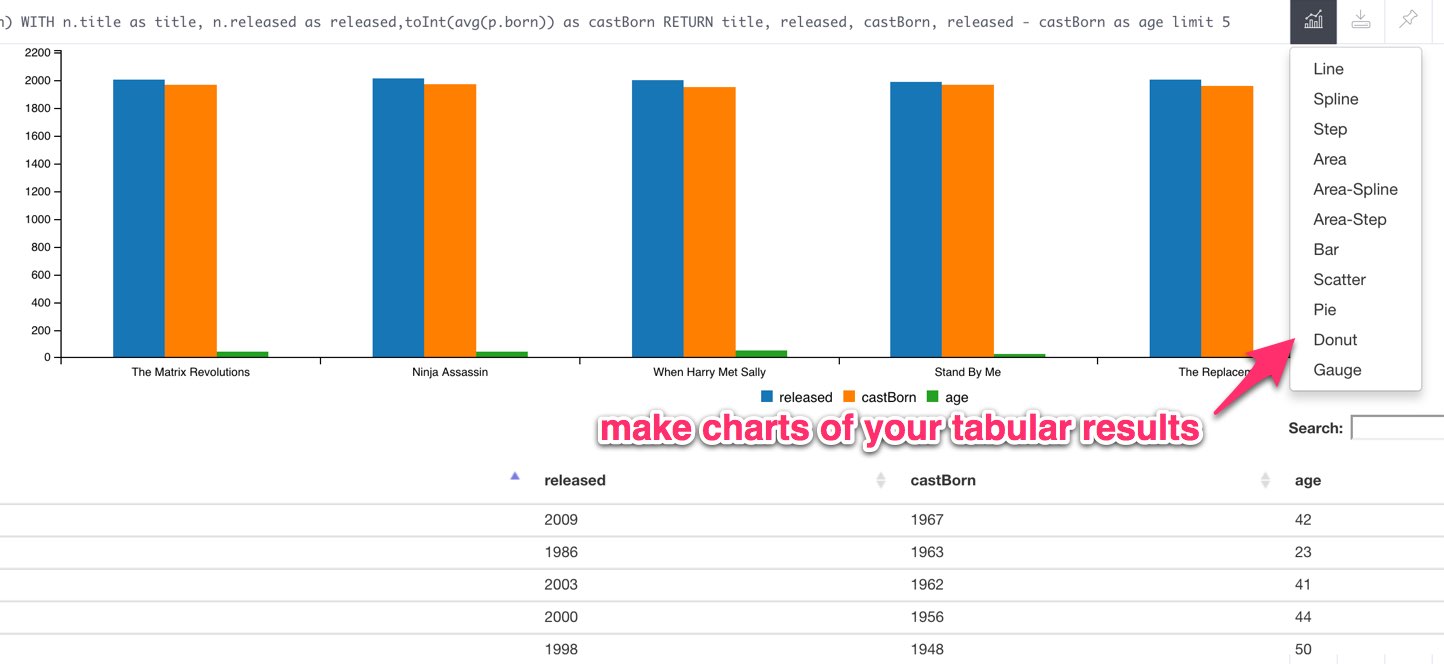
This week Michael Hunger created neo4j-spoon – a Chrome bookmarklet that adds support for charts and sorting/searching/paging tabular results in the Neo4j Browser. It’s useful if you want to quickly get a visual representation of some data to send to a colleague without having to crack open a Jupyter notebook.
Loading Data into Neo4j
We’ve found that people don’t truly get the power of the graph until they’ve loaded their own data in and written a few queries against it.
This week there have been a couple of blog posts showing both how to load CSV and JSON data.
- Kyle Russell Dunn published a collection of IPython notebooks for scraping and cleaning publically available U.S. government data.
- Michael Hunger created a Reddit meme graph from the meme section of the Reddit Top 2.5 million dataset. Michael shows how to do DIY NLP using only Cypher queries and comes up with a cool use of linked lists to explore the memes. If you like this take a look at the Pop Culture category on Neo4j GraphGists.
- Luke Gannon shows how to load Best Buy’s API into Neo4j using APOC’s Load JSON procedure. He also makes use of some other APOC procedures to deal with rate limits that thwarted his initial attempts to load the data. If you’ve got complex JSON documents that you want to load into Neo4j this is a good place to start.
Optimizing Neo4j Queries
The Neo4j field team spend a lot of their time helping users performance tune their queries, and this week two members of the field team have shared some of their tips:
- Alex Price presented a webinar on some of the lesser-known features of Cypher. If you want to learn how to profile and improve the performance of your queries, this is a good place to start.
- Max de Marzi again shows us the benefit of Neo4j’s extensibility when you need to squeeze out maximum performance in his latest post where he shows how to write a procedure which makes use of roaring bitmaps and the Kernel API to execute a heavily recursive query.
On the Podcast
Rik Van Bruggen hosts the popular Graphistania podcast in which he interviews Neo4j community members. There are over 80 episodes featuring people such as Dr. Jim Webber, Matt Wright and Felienne Hermans.
After a well-deserved new year’s break Rik is back with his first interview of 2017 with Gábor Szárnyas from the Budapest University of Technology and Economics.
Gabor spoke about incremental graph queries with openCypher in the Graph DevRoom at FOSDEM in early February, and they discuss his talk and more in the interview. You can find a video of Gabor’s talk if you’re interested in learning more.
If you’d like to appear on Rik’s podcast you can send him a direct message on Twitter – he’s always looking for new people to talk to.
Gotta kick our #neo4j #graphistania #graphdb podcast back into gear for 2017. Got an graphstory to tell and want to record it? PM me.
— Rik Van Bruggen (@rvanbruggen) February 7, 2017
Learning Neo4j
We’ll finish up this week’s post with a hat tip to a couple of intro to Neo4j tutorials we found on our travels.
- Baledung wrote up the excellent A Guide to Neo4j with Java which starts with the basics of graphs before moving on to more complicated examples using the Java and JDBC drivers. The code is all available on GitHub.
- Carlos Justiniano also created a tutorial where he introduces Neo4j using the JavaScript driver and TrumpWorld dataset. Carlos also presented at the New York JavaScript meetup and all the code and materials are on GitHub as well.
That’s all for this week. We hope you enjoyed it and if you have any feedback or suggestions let us know – devrel@neo4j.com.
Cheers,
Mark
Share Article



Explore
Related Articles

Neo4j Named a 2025 Gartner® Peer Insights™ Customers’ Choice for Cloud Database Management Systems


Text2Cypher Across Languages: Evaluating Foundational Models Beyond English


