









Welcome to this week in Neo4j where we collect the most interesting things that have happened in the world of graph databases over the last 7 days.
If you’ve got something that you’d like to see featured in a future version let me know.
I’m @markhneedham on Twitter or send an email to devrel@neo4j.com.
Featured Community Member: Johannes Unterstein
In last week’s online meetup Mesosphere’s Johannes Unterstein showed us how to get a Neo4j causal cluster up and running on DC/OS.
This was the culmination of several weeks’ effort where Johannes started with the Neo4j Docker image, figured out how to get it to play nicely with the Mesos ecosystem and created a Mesosphere Universe package so that users can easily create Neo4j clusters via the Marathon scheduler.
On top of this Johannes has been a part of the Neo4j community since 2013 and has organized several meetups as well as writing a Play Framework integration for Spring Data Neo4j.
On behalf of the Neo4j community I’d like to thank Johannes for all his efforts and I’m looking forward to your talk at GraphConnect Europe on 11th May 2017!
Using Graph Visualization to Explore Corruption in Egypt and FIFA
There were a couple of interesting posts showing how to use graph visualizations to explore two different types of corruption.
Lana Chan wrote What Do Big Data Paris and the Panama Papers Have In Common?
In this post Lana shows how you can use the Tom Sawyer graph data visualization tool to explore the 2015 FIFA corruption scandal.
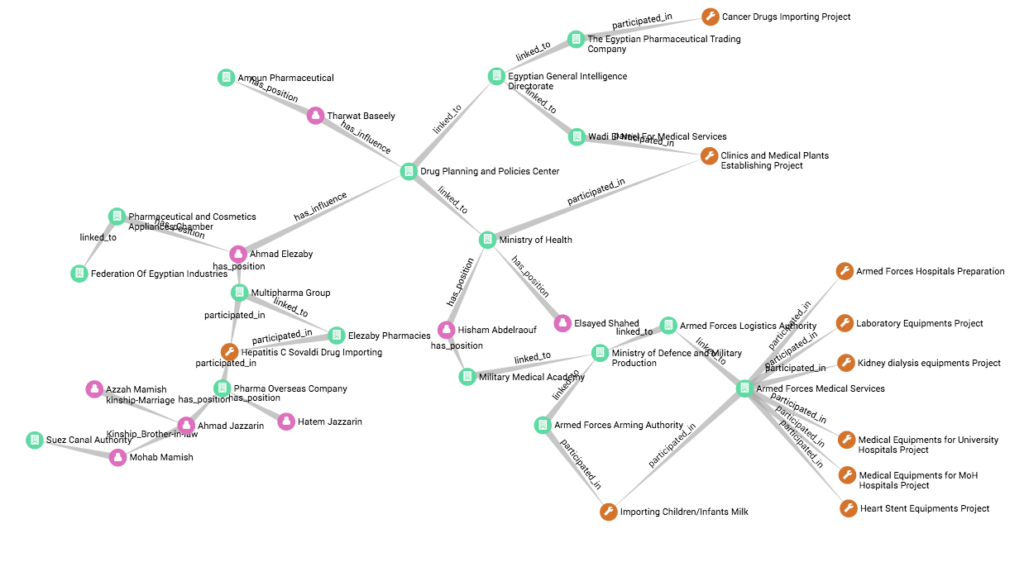
Visualizing the Egypt corruption network
Noonpost, an interactive Arabic media website, explain how they used Linkurious for large-scale investigations in a project on Egypt’s corruption networks.
In the post, they explain how they were able to explore connections between the army and its affiliates across various influence networks including the health, food, and tourism sectors using a combination of Cypher queries and graph visualizations.
There’s lots of good stuff in both of these posts if you’re interested in data journalism.
If you’d like to do data journalism work using Neo4j but don’t know how, sign up for the Neo4j Data Journalism Accelerator Program and you’ll get the opportunity to work with engineers from Neo4j’s Developer Relations team to get your analysis up and running.
Visual Graph Modeling and Importing
Michael Hunger created a video showing how to sketch graph models and load them into Neo4j using Alistair Jones‘ arrows tool.
You can also do something similar using the Graph Commons visualization library.
Will Lyon presented a webinar late last week where he showed how to model and import real-world datasets using Neo4j.
Will shows how to import data from Yelp using several different approaches:
- apoc.load.json – a procedure from the APOC library that can import JSON data directly.
- LOAD CSV – a Cypher command for importing CSV files. Works well up to ~10 million rows.
- neo4j-import – a tool for importing large initial datasets.
Will also talks about Neo4j’s user-defined procedures and functions, and if you’re interested in creating your own ones we’ve created a couple of new pages on the Neo4j developer site to help you get started:
Emil in Forbes, Hiking Recommendations, Malware Clustering, and DC/OS
-
Neo4j’s CEO Emil Eifrem features in a Forbes article – Growth Stories: The Magical Power Of A Name – in which he talks about the history of Neo4j and how he came up with the graph databases category.
This is a multi-part interview so stay tuned for more next week! -
Dirk Mahler released version 0.8 of the object graph mapping library for Java extended-objects.
It now supports the Bolt protocol which was introduced in Neo4j 3.0. -
Amanda Schaffer posted slides and code from last week’s talk at pyladies Seattle.
Amanda’s created a hiking recommendation engine which uses content-based filtering based on features (e.g., lakes, waterfalls) that hikes have in common.
There’s even a bit of web scraping of the WTA using Python’s beautifulsoup library. -
Our friends from Neueda released version 2.5.0 of the Graph Databases Plugin for the Jetbrains IDE family.
The new version adds node and relationship editing as well as listing indexes and constraints. -
Max de Marzi has a new blog post where he shows how to search for objects across multiple dimensions.
Max shows how to use the trusty RoaringBitmap to write a user-defined procedure that short circuits as soon as possible when searching across multiple facets. -
Shusei Tomonaga wrote about a malware clustering and network analysis tool called impfuzzy that can be used to visualize and look for similar pieces of malware using Neo4j.
The similarity score is calculated using the Louvain community detection and Fuzzy Hash algorithms. -
Pavel Yakovlev released version 0.1.1.2 of hasbolt, a Haskell driver for Neo4j.
This release has some minor fixes to keep the strictness and laziness gods happy!
On the Podcast
This week Rik interviewed Alistair Jones about the Causal Clustering feature released in Neo4j 3.1 back in December.
They go through the history of clustering in Neo4j from the use of Zookeeper in the 1.8 series up to the current day where we’ve implemented a version of Diego Ongaro‘s Raft consensus protocol.
If you want to learn more, there’s also a video of Alistair presenting on this topic.
Next Week
So what’s there to look forward to in the world of graphs next week?
- On Wednesday March 29th, 2017 Greg Walker, Robin Bramley and Adam Hill will present Using Neo4j to explore the Bitcoin Blockchain and open government data at the Neo4j London User Group.
- On Thursday March 30th, 2017 Ryan Boyd will present Building the Neo4j Sandbox cloud trial env: AWS ECS + Lambda + Docker + Auth0 ++ at the Neo4j Online meetup. We’ve also created an online meetup page where you can catchup on any episodes that you might have missed.
Tweet of the Week
My favorite tweet this week was by Jose Ramón Cajide who’s been analyzing Twitter networks using Neo4j in RStudio:
Visualizing my Twitter network using #Rstats and #Neo4j using @twitterapi #DataScience CC @esanchezrojo @txemaskapao @sorprendida pic.twitter.com/5pigMWa5P6
— Jose Ramón Cajide (@jrcajide) March 22, 2017
If you want to graph your own Twitter network you can try out the Neo4j Twitter Sandbox.
Don’t forget to tweet your graph using the #Neo4j hashtag if you give it a try.
Enjoy your weekend, it’s finally spring – hoorah!
Cheers, Mark
Share Article



Explore
Related Articles


This Week in Neo4j: Community Edition, Aura Agents, Context Graph, Spring Data and more

This Week in Neo4j: AI in Production, Memory, GraphRAG, Architecture and more

This Week in Neo4j: Aura Agents, Persistence, Graph Algorithms, GraphRAG and more

This Week in Neo4j: NODES AI, Context, Text2Cypher, Fraud Detection and more
