


Welcome to this week in Neo4j, where we round up what’s been happening in the world of graph database in the last seven days.
This week we look at how to create a Twitter clone using Neo4j, the Neo4j data science stack, learning Chinese and much more!
Featured Neo4j Community Member: Tomaz Bratanic
This week’s featured Neo4j community member is Tomaz Bratanic
Tomaz Bratanic – This week’s featured community member
Tomaz only recently came onto the Neo4j scene but has been quick to get going and blogs about Neo4j at an incredible rate.
Over the last few weeks these are some of Tomaz’s posts:
Tomaz also created the hospitals-neo4j project which brings together the above blog posts while analysing a hospital dataset.
Tomaz has also created a Neo4j Browser guide which you can try out by executing the following command in the query window of your Neo4j Browser:
:play https://guides.neo4j.com/contrib/hospital.html
On behalf of the Neo4j community, thanks Tomaz! I’m looking forward to see what else you come up with for APOC Awareness month.
Building a Twitter Clone with Neo4j
Max De Marzi has written a new series of posts showing how to build a Twitter clone with Neo4j.
- Part One in which Max explains his approach to Neo4j POCs and designs an initial graph data model.
- Part Two in which Max shows how to build a Twitter-esque HTTP API and create/retrieve users.
- Part Three in which Max adds functionality to follow other users and see who we’ve followed and who’s followed us.
- Part Four in which Max adds functionality to add tags and edit posts (a feature Twitter doesn’t actually have!)
Automated Static Malware Analysis using Neo4j
The MalwareGroup posted a really cool talk by Marion Marscalek and Raphael Vinot in which they show how to combine Neo4j and radare to analyse malware.
The Neo4j Data Science Stack, Open Data, and PageRank with APOC
There were lots of blog articles this week in the Neo4j community!
- Brock Tibert created a Docker image containing his favourite data science tools – Jupyter, RStudio Server, and Neo4j – and showed how to deploy it on Digital Ocean.
- Mike Morley and Dave Bennet presented real-world graph data modelling at the Calgary Neo4j meetup a few weeks ago and shared the code from their talk on GitHub. They combined data from the Alberta Energy Regulator and Edmonton Open Data Portal, loaded it all into Neo4j, before analysing the combined dataset with Cypher.
- InterMine – the open source data warehouse built specifically for the integration and analysis of complex biological data from the Micklem Lab at University of Cambridge – shared slides detailing their experiences using Neo4j.
- Ken Flerlage has been having fun playing around with the movie database to explore the six degrees of Kevin Bacon.
- Robin Bramley wrote up his talk from last week’s London meetup where he showed how to explore the UK road safety dataset using Neo4j.
- Jens Nerche continued analysing code bases with jQAssistant and this week shows how to find unwanted dependencies between Java packages.
-
Tom Porter walks through the
FOREACHhack for creating conditional statements with Cypher - Adam Cowley released the latest part of his WordPress Recommendations series where he looks at how to use PageRank with APOC Procedures.
On GitHub: Chinese Language Exploration, PHP OGM, d3.js
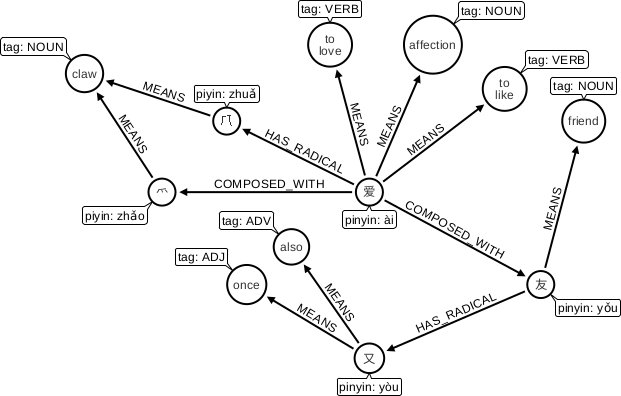
Modelling the Chinese language in Neo4j
On my GitHub travels, I came across the following projects which are worth a look:
- Diego Rodrigues created chinese_exp where he shows how to use data to explore and learn the Chinese language. Fernando Izquierdo also presented on the same topic at the London meetup a couple of months ago.
- Marco Falcier has has been building on top of Christophe Willemsen‘s Laravel Neo4j PHP OGM example project .
-
Christophe himself created neo4j-ogm-symfony-security, where he creates a quick PoC showing how to use a custom
UserProviderbacked by a Neo4j graph database. -
Bogdans Afonins created two example projects for Spring Data Neo4j 4.2. A simple retail example
in the SpringMVC-Neo4j-App and a social network one in spring-data-neo4j-4.2.0-example. - Dino Fancellu created neo4j-d3v4, a proof of concept project that gets data via the JavaScript driver and feeds it into a d3.js v4 force simulation.
From the Neo4j Knowledge Base
The Neo4j Knowledge Base is a collection of Frequently Asked Questions maintained by Neo4j’s Customer Success team.
If you’re doing some hands-on work with Neo4j, at some stage you’ll want to port the users/roles and constraints/indexes from your staging environment to production.
The following articles describe queries that will automatically generate Cypher statements to do this and save you having to rebuild them from scratch.
Next Week
So what’s happening next week in the world of graphs?
- On Saturday April 8th, 2017, Nigel Small will present A Pythonic Tour of Neo4j and the Cypher Query Language at PyData Amsterdam.
- On Thursday April 13th, 2017, Michael Hunger and I are going to run APOC Office Hours as part of April APOC Awareness month. If you have any APOC questions and/or are taking part in the competition, come along and ask us anything.
Tweets of the Week
My favorite tweet this week was by @tmanning who spent last weekend modelling Whitehouse personal financial disclosures documents in Neo4j as part of a Data4Democracy event.
How the White House executive staff linked? D4D team White-House-PDF processed 80/120 financial disclosures of the staff. #D4DHackathon pic.twitter.com/MJTonA7R6b
— Data for Democracy (@data4democracy) April 2, 2017
This graph shows the connections betweens people and organizations they worked for outside the federal government. @data4democracy @neo4j
— tmanning (@tmanning) April 2, 2017
That’s all for this week. Have a great weekend!
Cheers, Mark
Share Article



Explore
Related Articles

This Week in Neo4j: GraphRAG, GraphAcademy, Knowledge Graphs, Symfony and more

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more


