Upgrade your Graph Data Science library now (or miss out on cool new features)

Senior Director of Product Management, Graph Data Science
5 min read

Last week, we officially released the 1.3 version of our Graph Data Science (GDS) library. I can’t believe 1.0 was only a few months ago, or how many new features and functionalities we’ve added into the last three releases!
The GDS library now leverages Neo4j 4.0.1 and 4.1, and has added enterprise features like support for role-based access control and multi-database. The library also includes over 50 unsupervised algorithms, now with a preview of graph embeddings!

Algorithms in Neo4j: The bolded algorithms have been significantly improved as part of the GDS Library and the algorithms highlighted in purple are completely new.
If you used some of these algorithms in the prior Neo4j Graph Algorithms library (now deprecated), might be wondering, “Is there really any difference between the GDS library and the Graph Algorithms library?” The answer is a resounding yes – in many ways!
Most notable, the GDS library reflects principal API changes resulting in a more intuitive surface. We’ve also continued to improve usability with more suggestive error handling and better memory management.
The GDS Library also made breakthroughs in performance.
First, we optimized transforming the stored graph into the computational graph, which gives us an optimized data structure for analytics with minimal memory footprint for lightning-fast algorithms. Then, we steadily started graduating algorithms into the production quality tier, which indicates an algorithm has been fully parallelized and reimplemented for maximum performance – ensuring performance on enterprise-scale graphs.
The production-tier algorithms in the GDS Library are now between 10% and 85% percent faster than the deprecated library!
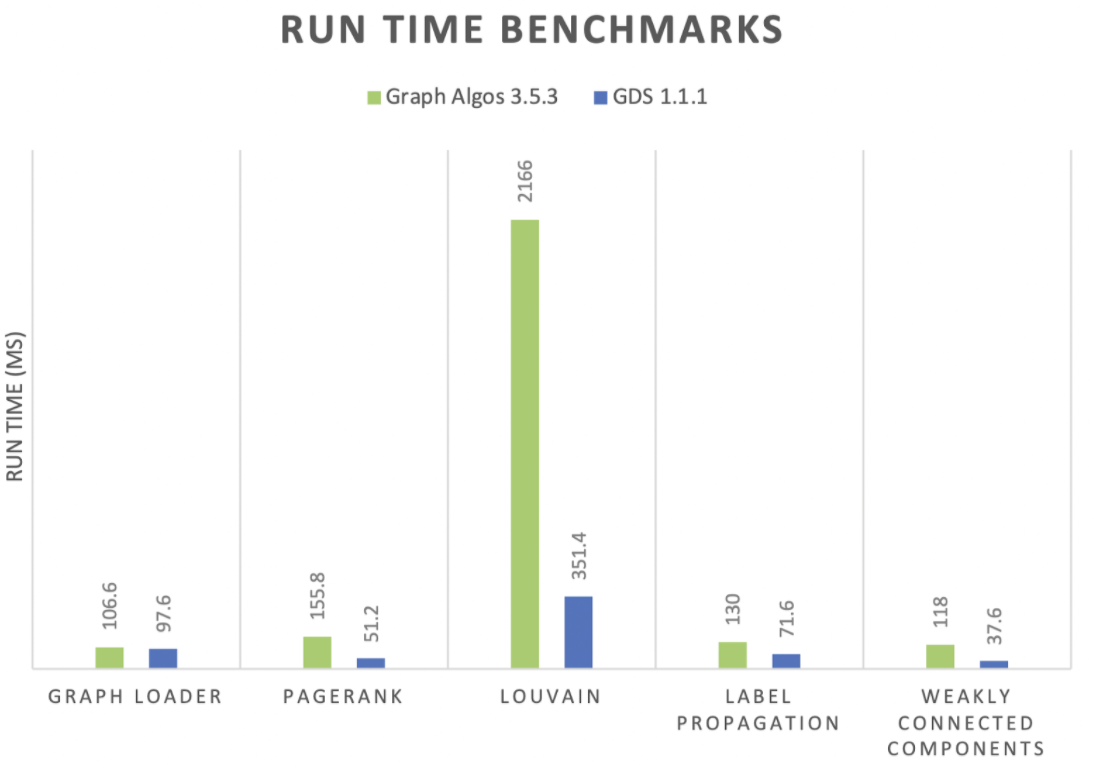
Comparing algorithm run-times from the GDS library and Graph Algorithms library. For an equitable comparison, we benchmarked on Neo4j 3.5.17
The initial Graph Algorithms library was an amazingly successful Neo4j Labs project that verified customer enthusiasm for algorithms. It also enabled us to rapidly test new features and implementation approaches. Community feedback not only helped us to identify and fix bugs ahead of a 1.0 release, but it also gave us a wealth of information on production requirements.
With the GDS framework, you get a production-ready platform for data science at an enterprise scale.
To support enterprise customers, we’ve focused on a few fundamental principles:
- Premium, 24/7 Support for GDS Enterprise Edition Customers
- Three Tiers of Algorithms
- Flexibility and Expressivity
- Data Science Focused Features
- Compatibility with the Neo4j Product Portfolio
If something goes wrong, we’re here to help! This uniquely includes support of the graph algorithms themselves.
The production quality tier includes algorithms – that we have optimized and tested against – for enormous production scale graphs. This includes the beta tier algorithms that are on their way to production quality, and the alpha tier implementations that are experimental, so you can get early access to cool new things (and give us feedback!).
Our in-memory graph and analytics workspace allows you to reshape your database on the fly. You can project new relationships or aggregate existing ones, as well as work with multiple node and relationship types. This enables you to load your data once into a mutable in-memory graph and create a recipe of calculations that layer your algorithms and queries together.
We’ve added usability improvements for data science workflows: including seeding, so you can reproduce consistent results, graph.export so you can save snapshots of your analytics workspace for versioning, and our new Pregel API so you can implement your own algorithms.
The GDS library 1.3 is compatible with Neo4j 4.1 and 4.0, and our 1.1 branch is maintained to work with Neo4j 3.5.X. We’ve also worked with the Neo4j Bloom team to leverage new Bloom features like rule-based styling, so you can show the results of your algorithms (color nodes based on community membership, or size them based on their centrality scores, or have the thickness relationships between similar nodes represent how alike they are).
I’m most excited to see what the Neo4j community does with some completely new capabilities. For example, in the GDS library 1.3, we’ve rolled out support for fine-grained access control, as well as introducing alpha (experimental) implementations of three different graph embeddings.

Unlike traditional algorithms that use pre-calculated formulas, embeddings learn the representation from your graph based on neural network models (deep learning) or linear algebra.
Another game changer in 1.3 is our Pregel API for implementing your own algorithms – so you can use the same high performance in-memory graph framework as our engineering team. We’ve added documentation to help you get started, and future tutorials will make it even easier.
If you haven’t tried GDS yet, check it out! And if you’re still using the old graph algorithms library, hopefully you’re ready to upgrade. We’ve updated the code in the O’Reilly Graph Algorithms book and created a migration guide to make it easy.
We strive to build a product informed by user needs, so if you have any feedback, feature requests, or questions, please comment on our community forum or open an issue on our GitHub.
Share Article



Explore
Related Articles

A workbench for teams to query, explore, and visualize graph data
Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3


