Game discovery: a recommendation algorithm for video games [Community Post]

Software Developer, IBM
5 min read
[As community content, this post reflects the views and opinions of the particular author and does not necessarily reflect the official stance of Neo4j.]
Movie recommendation systems usually ask you to rate what you like or dislike so it can bring you recommendations from other users with similar tastes. Modern applications like Netflix improve upon this approach by adding the movie characteristics in their algorithms. But recommendation systems does not work only for movies.
They are also very popular for books and music…but not so much for video games. Indeed there are a lot of game databases online, but they do not have the objective of recommending games, so their search and recommendation options are pretty limited.
Game Discovery is a web application that fills the gap for recommendation engines targeting video games. It uses only game characteristics, without the need to spend time rating games, allowing users to get quick results for simple or complex queries.
The secret that powers the system is the manner the data is structured, a graph database known as Neo4j. The recommendation algorithms running at Game Discovery heavily rely on the graph layout of the data and this was the reason why Neo4j was chosen over other types of database like relational or document databases.
Nodes and relationships
As stated by many specialists, the more data you have, the better the recommendations you can provide. I would complement by saying that having data in an easy format to manipulate also helps a lot.
The following query gives a hint of how data is structured at Game Discovery.
MATCH p=(game:Game)--(characteristic:ConceptEntry)
WHERE game.uid = 'game-mass_effect_2'
RETURN p
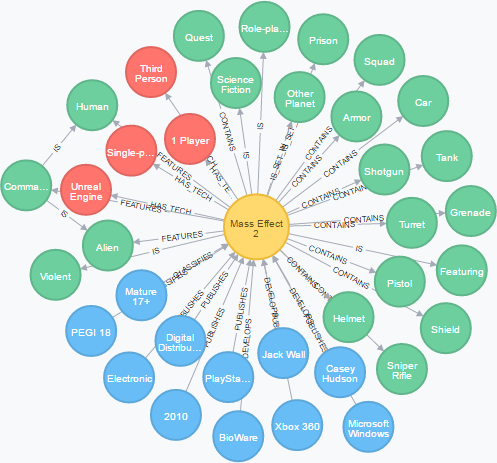
- Yellow: game nodes
- Red: gameplay related
- Green: plot related
- Blue: industry related
There are conceptually only two types of nodes, Game and Characteristic, and both have only basic attributes like unique id, name and description. Characteristic nodes can be everything that describes a game, such as: Company, ReleaseYear, Genre, Theme, etc.
All game nodes are connected to characteristic nodes and sometimes a characteristic node is connected to other characteristic nodes. Some examples are a developer that works for a company, a location that has sub-locations or a character having a fictional race.
The power that makes recommendations work comes from the relationships: they all have a single relevance attribute that indicates that some relationships are more important than others.
For example, two games are more similar because they feature the same characters or are part of the same series than two games that were published by the same company or have the same genre. Relationship directions do not really matter, so the graph is treated as an undirected graph.
Recommendation algorithms
It is possible to make complex queries in Neo4j using Cypher, but when talking about graph algorithms, there are libraries like Python NetworkX and R igraph that covers a lot more ground.
Because of this, Game Discovery runs its algorithms in memory using a simplified and modified version of the graph containing only the node ids and relationships. After an algorithm is executed, the rest of the data is loaded from Neo4j to be displayed to the user.
The main modification to the graph being processed in memory is that relationships between two nodes are grouped; their relevances are summed and also inverted, so the higher the relevance, the nearer to zero it will be. The reason for this is to allow the system to run shortest path algorithms, making the shortest path the one with the highest relevance between two nodes.
There are basically two recommendation algorithms running:
1. Search by characteristics
When the user searches for one or more game characteristics, the system uses single-source shortest paths for every characteristic searched to get the more relevant games connected to them, then it merges the results and we get the smaller ones as the more relevant items.
In the following example, the selected games are not only considered more relevant because they have more connections with the searched company (Electronic Arts), but also because the DEVELOPS relationship is considered to be more important than the PUBLISHES relationship.
MATCH p=(company:Company)-[:DEVELOPS]->(game:Game)<-[:PUBLISHES]-(company2:Company)
WHERE company.uid = 'company-electronic_arts'
RETURN p
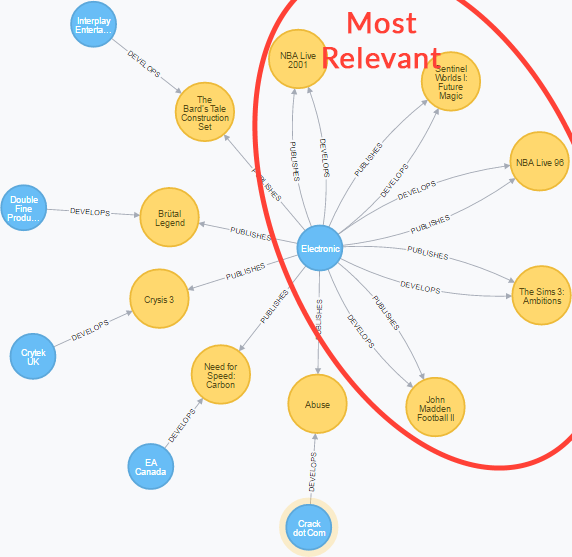
The most relevant paths.
Hierarchical queries are a strong advantages of using this path traversal approach. For example, when a user searches by game sets in Europe, it doesn’t just return nodes for games directly connected to Europe. It will also pull up games set in Italy, France, Germany or other European countries because these countries are connected to node Europe as a sub-location.
This can be seen in the following query:
MATCH p=(location:Location)-[*0..2]-(game:Game)
WHERE location.uid = 'location-europe'
WITH p, extract(n IN nodes(p)| n.uid) as uids
WHERE 'location-italy' IN uids
RETURN p

Hierarchical query exemplified by location
2. Search by game
When the user searches by a game, the system checks which neighbor games share most characteristics with the selected (i.e., searched-for) game. The higher relationship relevances then are taken into account. The ones with the highest score are the more relevant.
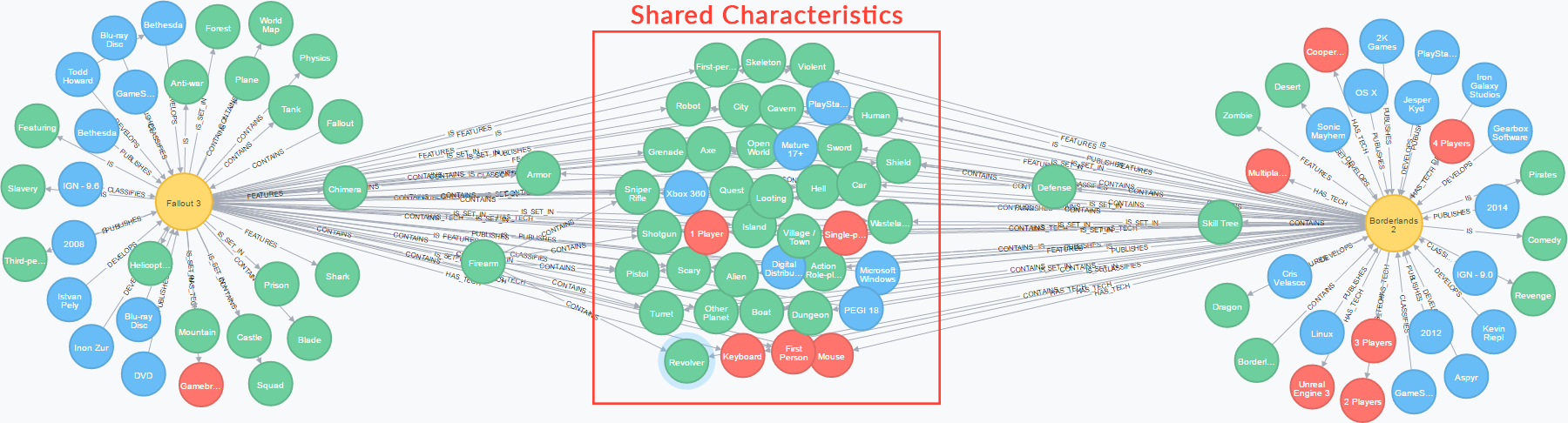
The following query demonstrates the shared connections between two games the system considers very similar (Borderlands 2 and Fallout 3):
MATCH p=(game:Game)--(characteristic:ConceptEntry)
WHERE game.uid = 'game-borderlands_2' OR game.uid = 'game-fallout_3'
RETURN p
Shared characteristics between video games
Conclusion
There is still room for improving the recommendation algorithms, like considering the number of hops or the sum of N first shortest paths between two nodes, but the current implementation has served to prove it works. The larger and more precise the data, the better the results it can provide.
Want in on awesome projects like this? Click below to get your free copy of the Learning Neo4j ebook and catch up to speed with the world’s leading graph database.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



