
GRANDstack: Graphs All the Way Down

Developer Relations Engineer
16 min read

Editor’s Note: This presentation was given by Will Lyon at NODES 2019 in October 2019.
Presentation Summary
GRANDstack is a full-stack framework for building applications with GraphQL, React, Apollo and the Neo4j Database. In this post, Neo4j Developer Relations Engineer Will Lyon will discuss why GraphQL specifically has been quickly gaining adoption. He’ll delve into why representing data as a graph is a win when building your API – for both API developers and consumers – and especially if you’re working with graph data in the data layer, such as with a graph database like Neo4j.
Moreover, he’ll cover some of the advantages of GraphQL over REST, as well as challenges with adopting GraphQL. He also dives into backend considerations for GraphQL and shows how to leverage the power of representing your API data as a graph, using GraphQL and graph databases on the backend.
In short, following this post, you’ll understand why GRANDstack is becoming increasingly efficient and effective by employing graphs all the way down.
Full Presentation: GRANDstack: Graphs All the Way Down
My name’s Will, and I work on the Neo4j Labs Team at Neo4j. My specific team doesn’t work on the core database in Neo4j Labs, but rather on tools, extensions and other features around the database, GRANDstack and GraphQL integration being two of our projects.
In this post, I’ll provide an overview of what GRANDstack is. Then, we’ll jump into building a NODES 2019 conference recommendations app.
What is GRANDstack?
GRANDstack is a full-stack framework for building applications. The individual components of GRANDstack are GraphQL, React, Apollo and the Neo4j database. GraphQL is our API layer, and React is a JavaScript UI library for creating user interfaces on web, mobile and now in VR. Apollo is a suite of tools that makes it easier to use GraphQL both on the client and the server. Lastly, the Neo4j database is a native graph database.
You might not be too familiar with GraphQL, which is an API query language. With GraphQL, we have a type system, we describe the data that’s available in our API, the client asks for only the relevant data for that request and the data comes back in the same shape as the query. In this way, we get exactly what the client asked for – nothing more. This is, essentially, efficient data fetching.

GraphQL makes an important observation: That your application data is a graph. Regardless of how you’re storing it on the backend – whether it be in a document database, a relational database or a graph database – it’s still presented as a graph. This is interesting and exciting for the Neo4j and graph database community, because it means there’s one-to-one mapping between the data model presented in the API layer to the database all the way in the backend.
The goal of our GRANDstack and GraphQL Neo4j integrations is to make it easy to expose a GraphQL API from Neo4j. We do this by allowing GraphQL type definitions to drive the database data model, auto-generating a GraphQL CRUD API from those type definitions and conducting an auto-generation of resolvers (the boilerplate data-fetching code our integration takes care of so you don’t have to manually write it).

This also works the other way around. If you have an existing Neo4j database, we can infer a GraphQL schema from that existing database and provide a full CRUD GraphQL API on top of Neo4j by hardly writing any code. This is what the heart of GRANDstack and GraphQL Neo4j is all about.
Note: In general, if you’re looking for resources on how to get started with GRANDstack, grandstack.io is the place to go, with documentation, tutorial videos, starter projects and a GRANDstack blog.
NODES Session Recommender Web Application
Earlier, as I was getting ready for the NODES conference, I realized we needed a NODES session recommender web application, and I thought it’d be fun to put this together.
What I wanted to do was make it easy to not only show you what sessions are available, but also make it easy to search for sessions you might be interested in.
But, one particular thing a graph database does really well is the idea of personalized recommendations. For example, what are similar conference talks that someone might enjoy, either based on content or user interaction?
This app can be found on nodes2019-app.grandstack.io. We’ll talk about the details later on this post.
Evolution of Web Development
As I was writing this post, I reflected back on the evolution of web development.
In the mid-90s, I was the assistant webmaster at Naples Elementary School. There, I maintained what would be the equivalent of a blog and wrote static HTML pages about field trips that we went on to cheese factories and places like that. This was my first exposure to the web; everything was still new at that point.

During this time, we had this idea of CGI, where we had directories, in which executable scripts would run on the server, fetch data from a database and give you dynamic content. This way, I could now embed database queries in template language along with my static HTML and whatnot.
All of this became, essentially, the LAMP stack, with Linux, Apache, MySQL and PHP. This was initially very popular because it became easy to fetch data from a database dynamically and render simple views.
Later on, we realized that embedding database queries in templating languages was ugly and hard to maintain, and we needed a better representation of this – an intermediate layer. This is when REST APIs and JSON became popular. jQuery became a way to fetch data from a REST API and render that on the front-end. Actually, the first job in which I was paid to do web development was using jQuery.
From there, we saw the need for web-scale databases, so we saw NoSQL and the MEAN stack emerge, including Mango, Express, Angular and Node.js. This made it easy to map documents in a document database to REST APIs. We also started to see front-end frameworks like Angular that made it easier for us to encapsulate logic and UI, and Meteor, which pushed the edge of what was possible with web development, giving us near real-time streaming content.
That brings us to the present day. On the front-end, we have React, which was open-sourced in 2013 by Facebook. Here, we realized the goal of moving from event listeners to declarative actions about the state.
Concepts like virtual DOM also allow for performance improvements. Instead of rendering our entire view, we now just need to render the minimum amount needed based on the change in state. Not only does this provide components to encapsulate logic and UI, but it also gives us performance optimizations.
Shortly after that, GraphQL was also open-sourced by Facebook. Again, this is all about efficient data fetching and providing a type system for our data, allowing us to describe and query our API as a graph.
At about the same time, we saw the rise of graph databases like Neo4j. As the move from other forms of NoSQL became problematic and data became more complex, the intuitive graph data model with graph databases was more appealing for developers. We started to see very different performance characteristics with graph databases, which were optimized for traversing a graph efficiently.
Combine all of this with some of the serverless and deployment options we have today. I’m thinking of things like ZEIT Now and Netlify, both of which make it easy to deploy front-end and backend code together with a simple command-line tool.
Ultimately, looking back at the evolution of web development, we’re very fortunate to be where we are now and have these technologies to work with.
And as I said earlier, an interesting observation here is if we look at the technologies that have been emerging, there’s a lot of graphiness going on. With GraphQL, we’re talking about exposing our API as a graph. In a graph database, we’re talking about actually storing data in our database using this graph data model.
This is why I’m so excited for GRANDstack: We’re working with graphs all the way down and leveraging performance optimizations and intuitiveness throughout the stack.
NODES Conference Graph
So how do we actually build this aforementioned conference app?

This is a great way to get our hands on actual graph data. Oftentimes, instead of looking at a tabular representation of the schedule for the day, it’s a lot nicer to look at a graph representation.
So this is the data model we’re using for this conference app. It provides a little view of Cypher and how to query it.
NODES Schedule GraphQL API
The next step for building this conference app is building our GraphQL API, because our front-end is going to query it.
What is GraphQL?
Before we go too deep into how to build the GraphQL API, I want to go a bit more into GraphQL. Let’s imagine that we have some data about movies, genres and actors. The first thing we do is define type definitions using the Schema Definition Language for GraphQL.

Once we’ve deployed and spun up our GraphQL API, we can use this powerful feature in GraphQL called introspection, which means that our GraphQL service is able to be queried. From here, the schema then becomes our API specification and documentation, and we can use tools like GraphiQL and GraphQL Playground to explore it, essentially making this a self-documenting, self-exploring API.
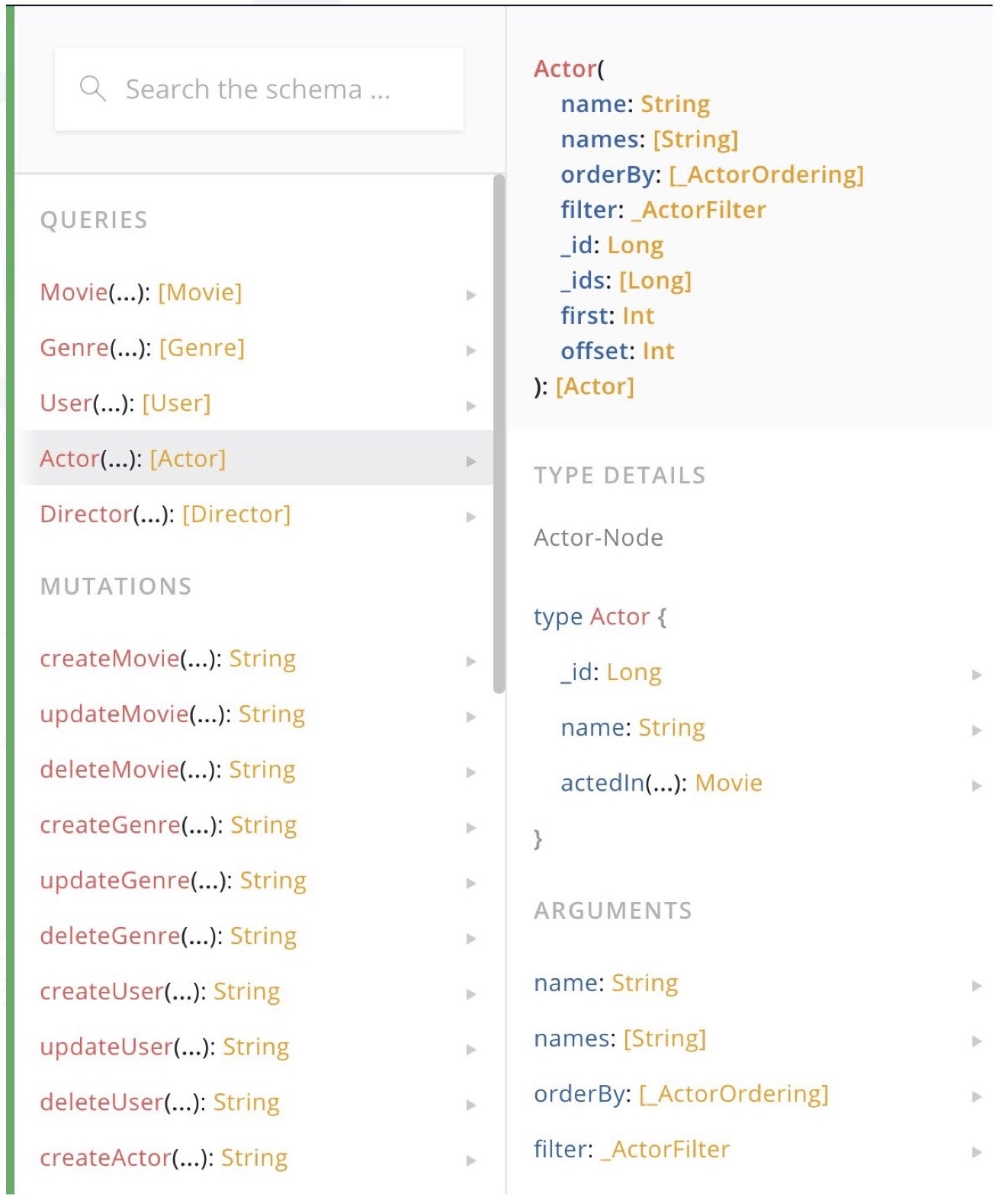
Below is a GraphQL query. The GraphQL query has a few components, one is the operation name and arguments. Here, we’re saying find movies with the title “A River Runs Through It.”

The bottom part of this query is the selection set, which specifies how we wanna traverse through that graph and what fields we want to return.
Note that our nested selections can also have arguments. Here, we’re only giving me the first two actors connected to “A River Runs Through It.” But, we’re traversing a couple hops down, so we go from “A River Runs Through It” to its directors, then from those directors to all the movies connected to those directors and lastly the title.
What we’re describing is a graph traversal. This is the data that comes back: We get our movie, it runs through the actors, the directors and all the movies connected to the directors, which in this case is just Robert Redford:

It’s important to understand that GraphQL is an API query language, not a database query language. In this case, we have limited expressivity, and don’t have the ability to do projections and aggregations. It’s also important to point out that GraphQL exposes your application data as a graph, but it’s not just for graph databases; we’re able to use essentially any data layer with GraphQL.
GraphQL Advantages
Some advantages of GraphQL include efficient data fetching, as we talked about earlier. This means we’re not going to be overfetching, which entails requesting more data from the backends than what we need and sending that over the wire. With GraphQL, we only get back the piece of the user object we’re interested in. If we’re only rendering a few fields in our view, that’s all we should fetch from the backend because it might be expensive to fetch some of those fields and it’s also less data sent over the wire.
Underfetching is another problem GraphQL solves. This is the idea of sending all the data needed to render a view in a single request. With REST, if I fetch a list of things – maybe a list of blog posts, for example – and I need the author for each one, I might have to make another request for each author to obtain more information. However, with GraphQL, we can get all the posts and author information in one request.
There’s also the concept of graphs all the way down, from the front-end framework to the API. This basically allows us to have more component-based data interactions. When we’re interacting with our API, we’re typically doing this in the context of relationships – not resources.
GraphQL Challenges
These advantages don’t come for free, of course. There’s always trade-offs.
One of the challenges of GraphQL is that well-understood practices from REST don’t really apply here, such as HTTP status codes, errors and caching. There are ways to handle them in GraphQL and the GraphQL community has really pushed forward a lot of this, but they might not be the ways you’re used to, especially when you first come from a REST world.
There’s also the challenge of having a client request arbitrarily complex queries and not having the performance considerations to control them. However, there’s also a solution to this: We can essentially restrict and define the queries or depth of a query that a client is able to request.
Then we have considerations like rate limiting and query costing, because the request that comes in might not necessarily be just requesting one resource. But again, there are solutions to these challenges.
Building a GraphQL Service
So how do we build a GraphQL service? Essentially, the high-level approach here is to take our type definitions and implement resolvers, which are the functions that define how to fetch data for a GraphQL request.

In standard cases, we might have to do authorization validation, query a database, validate and format that response and then send some data back. We might end up writing a lot of boilerplate in our resolvers, which is not so much fun.
The problems with what I’ll call the standard approach – where we write type definitions and implement resolvers with data-fetching code – is we end up with schema duplication, in which both our API and our database are maintaining a schema.
Also, we often have a mapping and translation layer from GraphQL to whatever our backend layer is, whether it’s another API, a document database or a relational database. There’s a lot of boilerplate when we write this.
Now if we look back at the image above, we’re getting a session from a database driver instance, executing a query, iterating through the results and reformatting that – definitely not ideal.
Then, we also have this n+1 query problem. We may have the same problem from the backend, where we have to fetch a list of things and then iterate back to the database after seeing that we’ve requested a connected field. Instead, we want to make as few requests to the database as possible.
GraphQL “Engines”
A class of tools called GraphQL engines has come out to address some of these issues. These are tools that auto-generate GraphQL schema and generate database queries from GraphQL requests.
Below are some examples. A lot of these are built on top of Postgres or, in the case of AWS AppSync, exposing AWS resources with GraphQL.

Neo4j GraphQL
Here I want to focus on Neo4j-GraphQL integrations.
The goals of these integrations are to take a GraphQL first development approach, where we’re generating Cypher from GraphQL, using the GraphQL schema to drive the database model and taking care of that boilerplate code. Then, we want to extend the functionality of GraphQL.
As we said, GraphQL is used for querying an API – not a database – so we’ll need to expose more custom logic to handle cases that are beyond simply CRUD.
GraphQL First Development
First up: GraphQL first development. When we talk about this, what we mean is that the GraphQL schema becomes the driver of our API – of how we implement front-end data-fetching code, the data model and data-fetching code for the database.

Because there is very close mapping from the GraphQL type definitions to the property graph model in Neo4j, this is relatively easy to do with a graph database.
Auto-Generating GraphQL CRUD API
Next, we take those type definitions and auto-generate a GraphQL CRUD API. We haven’t talked about this in too much detail, but basically, we generate query invitation types. These are the entry points for the API for both reads and write operations.

Then, we add a bunch of things for convenience, such as ordering, pagination, filtering and working with the DateTime database types.
Generating Cypher from GraphQL
An important piece of this integration is taking GraphQL, translating it to Cypher and optimizing that generated Cypher query for one single roundtrip to the database. Doing this solves the n+1 query problem.

Extending GraphQL with Cypher
The next piece is extending the functionality of GraphQL with Cypher. To do that, we’ve added the following Cypher GraphQL schema directive:

What this does is it allows us to bind a Cypher query to a field in our GraphQL schema. In turn, this becomes a computed field, so that an attached Cypher query runs as a subquery in the overall generated Cypher query, and it’s still just one trip to the database. (If you’re not familiar with schema directives in GraphQL, they’re essentially GraphQL’s built-in extension mechanism to define custom server-side behavior.)
There are a few versions of our GraphQL integration. One’s a database plugin that’s useful for local development and testing, but the one I want to discuss today is neo4j-graphql.js, which is published as a Node.js package and used with other JavaScript GraphQL tooling such as Apollo Server GraphQL.js.

An important point here is that we’re just talking about making it easy to build an API application that sits between the client and the database. We’re not sending GraphQL directly to the database; we’re still building this API layer, but rather we’re just doing it in a way that makes it useful and easier to create GraphQL APIs.
Generating Database Queries from GraphQL Requests
Earlier, I discussed how GraphQL engines are declarative database integrations for GraphQL that allow us to either infer or derive a database from GraphQL type definitions. This gives us this auto-generated GraphQL API on top of our database and auto-generates data fetching code, which is really convenient.
You might be curious about how these GraphQL engines work under the hood. Before, when we talked about our GraphQL resolvers, we implemented the resolver, defined some data-fetching code and maybe did some authorization validation.
Now, the resolver is instead passed into arguments, one of which is the ResolveInfo argument. Inside this ResolveInfo argument, we have things like the GraphQL query abstract syntax tree (AST) as well as a representation of the GraphQL schema. In this way, we can find the selection set in a nested fashion and see what variables are passed in.

Essentially, what we do here is traverse that AST to find the nested selection set, which looks at all of the fields that are requested. We use this to generate one single database query.
You don’t need to understand how all this works to use our GraphQL integrations, but if you’re curious, I gave a talk at the GraphQL Summit in San Francisco, which was a more advanced session on how we’ve built this GraphQL integration and how to leverage this ResolveInfo object to generate more efficient data-fetching code in GraphQL.
Who’s Using GRANDstack & Neo4j GraphQL?
What I want to do next is talk a little bit about some of the folks who are using GRANDstack and Neo4j GraphQL, and then point you to some resources.
First, I want to talk about how we use GRANDstack and Neo4j internally. Well, if you’ve ever gone to the community site, you’ve probably seen numerous activity feeds at the top of the page.
Every week, we have This Week in Neo4j, where we feature a community member. We also have links to other resources and popular community content, which includes community projects that people are working on.
The way that we fetch all of this is from a Neo4j database. We call it Community Graph, which has information about the community, what they’re working on, GitHub projects and who’s organizing meetups about Neo4j and graph databases. These are all populated by lambdas that periodically fetch data from various APIs.
There’s also a GraphQL API that sits on top of that. Whenever you go to the community site, it sends a GraphQL request to populate the top of that page and fetches data from Neo4j.
The next group I want to talk about is the Financial Times, who’s a financial publication that also uses GRANDstack and Neo4j GraphQL. They employ Neo4j in a few different ways, but the specific project I’ll talk about is known as the bizops API. They wrote a great blog post that mostly talks about performance testing when adopting this Neo4j-GraphQL integration.
Essentially, the data model they have here is one that connects things like products to internal teams to the stakeholders for those teams. When something’s down, they know what products will be impacted, which teams support those teams and who to call in the middle of the night.

This is really neat because it shows how you can use GraphQL and GRANDstack to not only build applications you’re exposing externally, but also to build internal tools.
Rhys Evans from the Financial Times, who’s a principal engineer that works on this project, gave a great talk, where he shows how they put this system together. He compares using GRANDstack to being Mark Zuckerberg and hacking something together very productively, which I thought was an interesting comparison. What we’re really talking about is developer productivity. As we look back to the popularity of LAMP stack and MEAN stack, it was because they made it easy for developers to start building applications. I hope GRANDstack will be like that as well.
The third GRANDstack and Neo4j-GraphQL user I want to talk about is Human Connection, who’s building a decentralized social network in an effort to bring about positive local and global changes. Specifically, they use Neo4j GraphQL and GRANDstack to power their network. They held an online meetup a few months ago, where they talked about some of the internal workings of the project.
Ultimately, I really appreciate working with the GraphQL community and seeing the interest around this. Everyone who’s involved with GraphQL sees its advantages and the benefits.
This is why Neo4j joined the GraphQL Foundation as a founding member earlier this year. The GraphQL Foundation essentially comprises the stewards of GraphQL after it was open-sourced by Facebook, who then handed it over to this foundation to nurture and evolve GraphQL for the community. At Neo4j, we believe GraphQL is really important, and we’re happy to support it by being a member of the GraphQL Foundation.
Download your free copy Fullstack GraphQL Applications with GRANDstack – Essential Excerpts.
Share Article



Explore
Related Articles

Text2Cypher Across Languages: Evaluating Foundational Models Beyond English




Integrating Neo4j With Symfony: Profiling Queries and Centralized Logging
