Rags to reqs: Making ASVS accessible through the power of graphs and chatbots


11 min read

OWASP Application Security Verification Standard (ASVS) is great, but it feels underused, definitely compared to OWASP Top 10. The concept is fantastic: a standard that any development organization can use for self-assessment and methodical improvement of its application security. Why is this standard not used everywhere?
Let’s hear from Josh Grossman, one of the biggest champions of the ASVS project: “The ASVS has about 280 requirements. We don’t want to be looking at those for every single feature. We want to be able to focus on what counts. We want to be able to focus on what is important for this particular feature, for this particular stage in the application’s development.”
This blog describes our journey through ASVS adoption in Neo4j engineering.
Background
One of the first recommendations when starting with ASVS is to tailor it to your organization’s context. We had a volunteer security champion who went through the standard and got rid of the irrelevant requirements. After this exercise, we were still left with 166 valid requirements. Can we – the security team – ask the developers to go through this list for every feature? Sure, we can ask, but let’s face it – not likely to hear an enthusiastic “Yes!” No, that’s still too many requirements. Also, how would that look in practical terms? Nobody needs another spreadsheet in their lives. Surely we can do better.
Inspiration
We are a small AppSec team in Neo4j. But you don’t need to work for such a company to see that ASVS is very “graphy” data by its nature. Can we use it to our advantage?
ASVS Imported to Neo4j as a Graph
As we started looking into ASVS adoption, the industry exploded in terms of large language models (LLMs). Could we use an LLM to describe our feature and have it generate the relevant ASVS requirements for it?

First Attempt – Hallucinations
Even before discussing how relevant the requirements were to the feature described, it became clear that ChatGPT hallucinates about the requirements, and no amount of prompt engineering could convince it to stick to the reality.
Fortunately, multiple blogs discussed grounding LLMs through the use of Retrieval-Augmented Generation (RAG): the process of optimizing the output of an LLM, so it references an authoritative knowledge base outside of its training data sources before generating a response.
We have an authoritative knowledge base of ASVS in place. We have a database that supports vector indexes and similarity search. We have a tutorial that uses a movie database to illustrate RAG usage. Can we put it all together?
Architecture of the tool
We want our users to describe their features in a paragraph or two, similar to what you’d put on a Jira or Trello card. The tool will calculate vector embedding of this text, retrieve ASVS requirements above the similarity threshold, and provide these requirements to the LLM as a context.
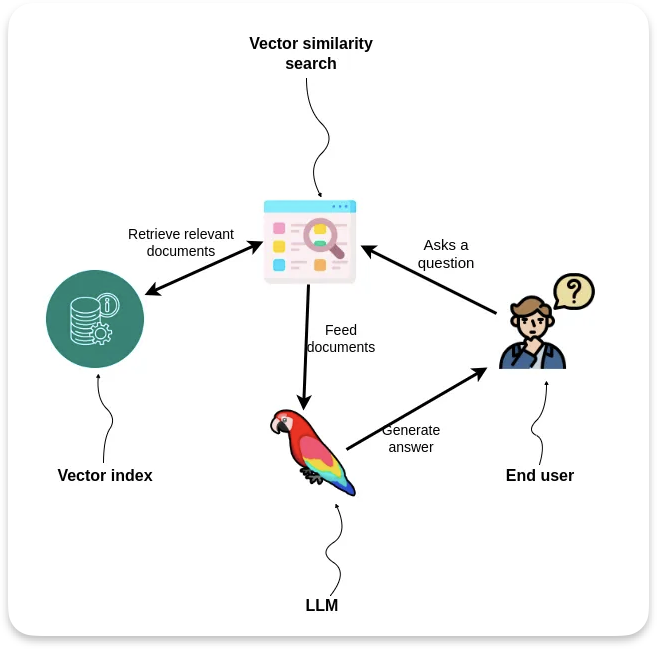
Conceptual architecture
Before showing the code and the examples of interacting with it, let’s look closer at the underlying knowledge graph. (Smaller nodes denote level 1 requirements if you are curious about this layout.)
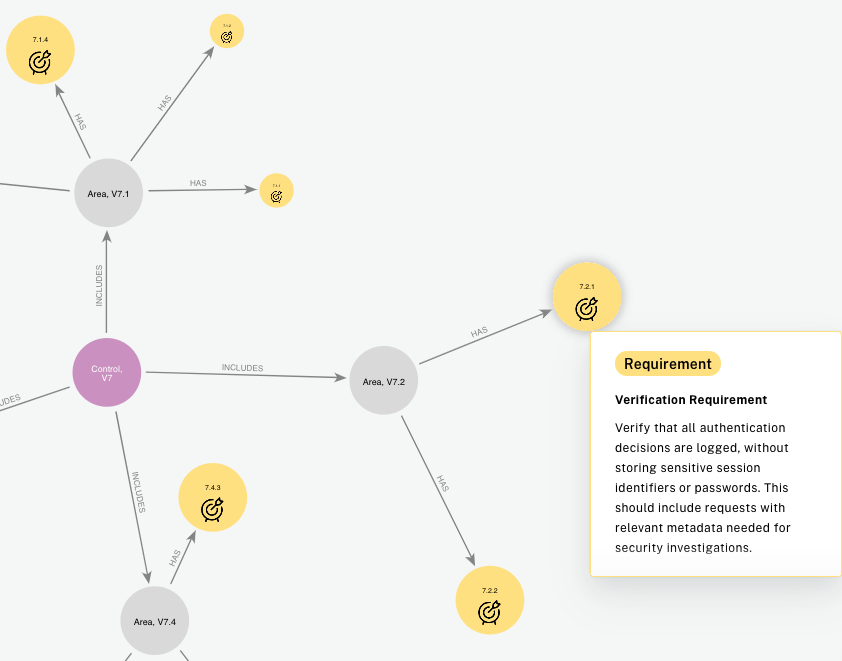
Zoom-in to V7: Error Handling and Logging
The main relationships are (c:Control)-[:INCLUDES]->(a:Area)-[:HAS]->(r:Requirement)
Control and Area nodes are very simple: They only have their number and name.


Requirement node is a bit more juicy.

Requirement Node Properties
We can calculate vector embedding on the Verification Requirement property, and store it in a separate node.
from neo4j import GraphDatabase, Query
from openai.embeddings_utils import get_embedding
import openai
import os
"""
LoadEmbedding: call OpenAI embedding API to generate embeddings for each property of node in Neo4j
Version: 1.1
"""
EMBEDDING_MODEL = "text-embedding-ada-002"
NEO4J_URL = os.environ['NEO4J_URI']
NEO4J_USER = os.environ['NEO4J_USER']
NEO4J_PASSWORD = os.environ['NEO4J_PASS']
OPENAI_KEY = os.environ['OPENAI_KEY']
class LoadEmbedding:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
openai.api_key = OPENAI_KEY
def close(self):
self.driver.close()
def load_embedding_to_node_property(self, node_label, node_property):
self.driver.verify_connectivity()
with self.driver.session(database="neo4j") as session:
result = session.run(f"""
MATCH (a:{node_label})
WHERE a.{node_property} IS NOT NULL
RETURN id(a) AS id, a.{node_property} AS node_property
""")
# call OpenAI embedding API to generate embeddings for each property of node
# for each node, update the embedding property
for record in result.data():
id = record["id"]
text = record["node_property"]
# Below, instead of using the text as the input for embedding, we add label and property name in
# front of it
embedding = get_embedding(f"{node_label} {node_property} - {text}", EMBEDDING_MODEL)
# key property of Embedding node differentiates different embeddings
cypher = "CREATE (e:Embedding) SET e.key=$key, e.value=$embedding"
cypher = cypher + " WITH e MATCH (n) WHERE id(n) = $id CREATE (n) -[:HAS_EMBEDDING]-> (e)"
session.run(cypher, key=node_property, embedding=embedding, id=id)
if __name__ == "__main__":
loader = LoadEmbedding(NEO4J_URL, NEO4J_USER, NEO4J_PASSWORD)
loader.load_embedding_to_node_property("Requirement", "`Verification Requirement`")
loader.close()
After running this script, we need to create the index:
CALL db.index.vector.createNodeIndex('embeddingIndex', 'Embedding', 'value', 1536, 'COSINE')
The dump of Aura database with pre-calculated embeddings and the index is available for download from https://github.com/neo4j-examples/appsec-asvs-bot.
Now that we have our knowledge database, let’s put it all together. For the interface, we went with the https://docs.streamlit.io/develop/tutorials/llms/llm-quickstart example.
import os
import streamlit as st
from openai import OpenAI
from langchain_community.graphs import Neo4jGraph
NEO4J_URL = os.environ['NEO4J_URI']
NEO4J_USER = os.environ['NEO4J_USER']
NEO4J_PASSWORD = os.environ['NEO4J_PASS']
OPENAI_KEY = os.environ['OPENAI_API_KEY']
EMBEDDING_MODEL = "text-embedding-ada-002"
OPENAI_MODEL = "gpt-4o" # replace with your favourite model
st.title('🦜🔗 AppSec Verification Standard (ASVS) Chat App')
st.write("This program looks up ASVS requirements relevant to your feature description.")
with st.sidebar:
st.subheader("Browse the full ASVS:")
st.write("https://github.com/OWASP/ASVS/tree/master/4.0/en")
st.subheader("Here is an example of feature description:")
st.markdown('''_We want to add some pay-per-use features in our SaaS product. Each cloud tenant will have
an agent monitoring the usage of these features. The agents send data through a custom proxy to BigQuery.
We will use the data in BigQuеry to bill the customers._
''')
st.subheader("Some params you can tweak:")
num_reqs = st.number_input("Maximum number of ASVS requirements to take into account", 2, 20, value=10,
help='''Number of reqs above similarity threshold to pass to OpenAI."
If you have lots of relevant requirements, increase this param to pass them on.''')
threshold = st.number_input("Cut-off for low scoring matches", 0.5, 0.99, value=0.87,
help='''Semantic similarity threshold in vector lookup, 0.99 is the most strict.
0.85 seems reasonable, but YMMV. Passing in irrelevant reqs will lead to
hallucinations.''')
st.subheader("Bring your own key:")
open_api_key = st.text_input("OpenAI API Key", type="password") # Not overwriting env. key at the moment
llm = OpenAI()
graph = Neo4jGraph(
url=NEO4J_URL,
username=NEO4J_USER,
password=NEO4J_PASSWORD
)
# Set a default model
if "openai_model" not in st.session_state:
st.session_state["openai_model"] = OPENAI_MODEL
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
def generate_response(input_text):
embedding = llm.embeddings.create(input=input_text, model=EMBEDDING_MODEL)
r = graph.query("""
// 2. Find other requirements which have high semantic similarity on description
CALL db.index.vector.queryNodes("embeddingIndex", $lookup_num, $feature_embedding) YIELD node, score
WITH node, score
WHERE score > $threshold // exclude low-scoring matches
// 3. From the returned Embedding nodes, find their connected Requirement nodes
MATCH (m2:Requirement)-[:HAS_EMBEDDING]->(node)
WHERE node.key = '`Verification Requirement`'
RETURN m2.`#` AS reqNumber, m2.`Verification Requirement` AS requirement, score
ORDER BY score DESC;""",
{'feature_embedding': embedding.data[0].embedding,
'lookup_num': num_reqs,
'threshold': threshold})
if not r:
# The graph didn't return anything, abandon mission
st.write('''Your feature description doesn't bring up any relevant ASVS requirements, maybe it doesn't have
security impact? Lucky you! Maybe try a lower cut-off, just to be sure''')
return "Come back with your next feature."
with st.expander("Here are some requirements for your feature in descending order of relevance, click for details"):
for entry in r:
st.write(entry)
messages = [{
"role": "system",
"content": """
You are an application security specialist. Your role is to assist developers in
identifying relevant security requirements. You are knowledgeable about OWASP and ASVS in particular
Attempt to answer the user's question with the context provided.
Respond in a short, but friendly way.
Use your knowledge to fill in any gaps, but no hallucinations please.
If you cannot answer the question, ask for more clarification.
When formatting your answer, break long text to multiple lines of
up to 70 characters
"""
}, {
"role": "assistant",
"content": """
Your Context:
{}
""".format(r)
}, {
"role": "user",
"content": """
Answer the users question, wrapped in three backticks:
```
{}
```
""".format(input_text)
}]
with st.spinner("Let me summarise it for you..."):
# Send the message to OpenAI
chat_completion = llm.chat.completions.create(model=OPENAI_MODEL, messages=messages)
return chat_completion.choices[0].message.content
with st.form('my_form'):
text = st.text_area('Provide a paragraph describing your feature:', 'As a Neo4j PM...')
submitted = st.form_submit_button('Submit')
if submitted:
response = generate_response(text)
if not response:
st.write("Something went wrong with OpenAI call.")
else:
st.write(response)
Let’s see what it looks like in action.
The side panel gives the users some parameters and the ability to bring their own key, if that’s what you want in your environment. We can ignore it for now and focus on the main show.
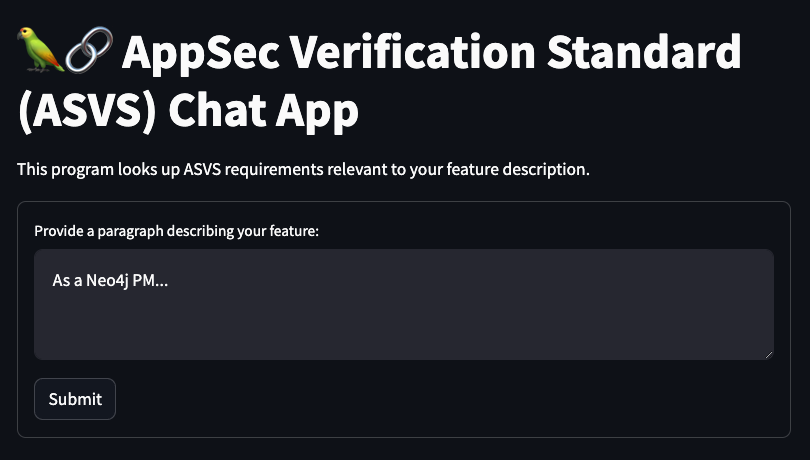
User Prompt
Using the feature description in the example, we first get the list of ASVS requirements:
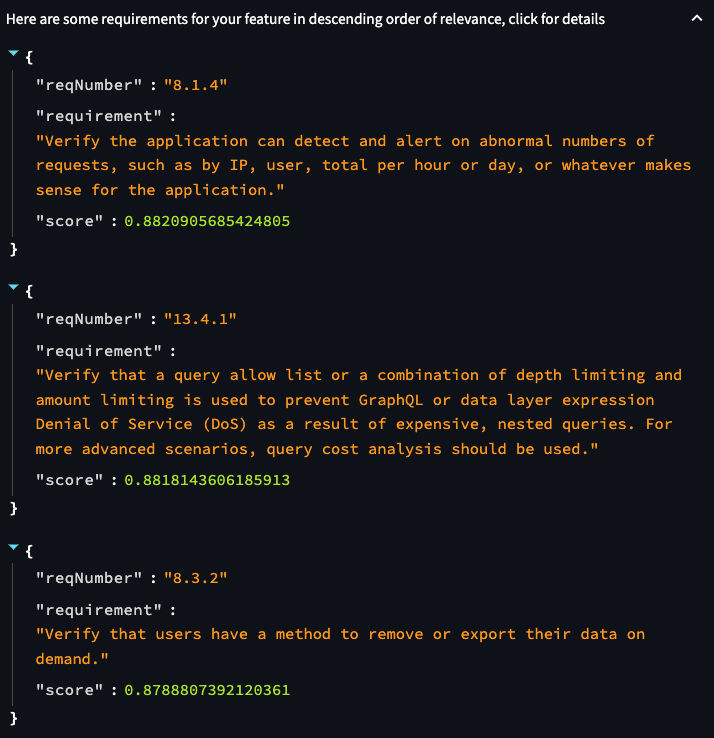
List of semantically similar requirements, truncated
This list goes to an LLM of your choice as a context, and we get back what seems a sensible summary with no hallucinations:
That sounds like a solid plan! Here are a few security considerations:
1. **Data Integrity and Authenticity**: Ensure the data from agents
going to BigQuery is encrypted and authenticated. Use secure
protocols like HTTPS or TLS.2. **Rate Limiting**: Implement rate limiting on the proxy to prevent
abuse or DoS attacks.3. **Alert on Abnormal Activity**: As per ASVS 8.1.4, ensure your
system can detect and alert on abnormal numbers of requests
from agents.4. **Access Control**: Ensure proper access controls are in place for
both the agents and users accessing the billing information.
Follow ASVS 4.1.1 guidelines.5. **Data Privacy**: Make sure you’re compliant with data protection
laws like GDPR by allowing users to export or delete their
data (ASVS 8.3.2).Following these guidelines will help secure your SaaS product while
adding new features.
Is it as comprehensive as going through the whole list with a couple of developers and figuring out what’s applicable for our feature? Of course not. But is it a quick and easy start, that’s also miles better than no security requirements? Absolutely. It can drive further engagement with the ASVS and the overall security culture of your organization.
Of course, not every feature has security relevance. Let’s make sure the bot doesn’t create busy work for the engineers.
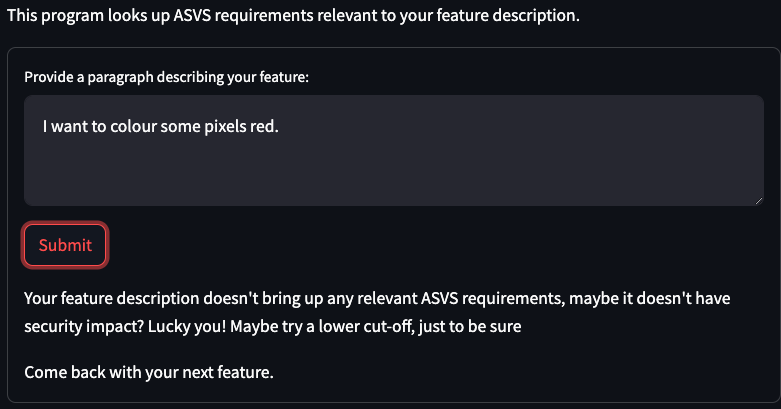
Passing Sanity Checks
Yes, it’s fine.
Ideas for further development
We have many improvement ideas on this basic chatbot. First, if you don’t expect everyone to run it on their local machine, you need to add some authentication. Exporting the requirements – ideally, directly to the backlog tool – would be a useful addition. A more ambitious feature would be getting the description directly from the backlog or even from design documents.
Start using ASVS in a quick and easy way, let the engagement grow naturally rather than dropping the full set of requirements on every team for every feature. Our approach provides much better results in terms of identifying the relevant requirements compared to full text search or chatting to ChatGPT about ASVS (very amusing hallucinations, though).
Download the database dump and the code and start your own experiments.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher




