
Bluesky User Interaction Graph — Discover AuraDB Free (Week 47)

Head of Product Innovation & Developer Strategy, Neo4j
10 min read

As social networks are really nice to import and explore in a graph database, this is what I did this week. If you rather watch the recording of the stream, you can do so below. Otherwise, this blog goes into the details for you.
Bluesky as the reference social media application for the Authenticated Transfer Protocol (ATP), currently sees a massive hype. There are almost 2M people on the waitlist while the current user count is 65k with roughly 2M posts so far.
A number of celebrities, journalists, and tech folks already made it there, but what is most compelling is that a larger number of people from usually underrepresented minorities like BIPOC and gay and trans-folks are active there.
Bluesky currently feels like the early Twitter of 2007, with lots of fun and jokes and everyone feeling comfortable just sharing tidbits. It’s refreshing and cool to be able to ping Jake Tapper, AOC (who also did an AMA), or James Gunn and actually get an answer.
So far I’ve seen no harassment or bad behavior (but that might also just be my bubble). But there are many conversations about scalable moderations and user protection with varying points of view.
The app itself is really the bare minimum, but it’s also just meant to provide a reference implementation to test the protocol at a larger scale than before. Expansion happens at a slow scale, most users get 1 invite code every two weeks, with some exceptions.
The AT-protocol itself is quite interesting, basing everything on distributed IDs (DID) to identify users. Data (posts, likes, media) is stored cryptographically signed in repositories that are hosted by federated “personal data servers” (PDS).
Protocol Overview | AT Protocol
The AT protocol allows users to use their own domains to authoritatively declare who they are (like washingtonpost.com) with an _atproto DSN record.
You can get the record from DNS yourself and then query the Placeholder Service (PLC) for more details on that ID, here you can see also the repository data server (PDS) for my case and my domain as an alias.
dig TXT _atproto.mesirii.de
; <<>> DiG 9.10.6 <<>> TXT _atproto.mesirii.de
...
;; ANSWER SECTION:
_atproto.mesirii.de. 3276 IN TXT "did=did:plc:gteyzzitmjhuezvsi6nyrszj"
curl -s https://plc.directory/did:plc:gteyzzitmjhuezvsi6nyrszj/data | jq .
{
"did": "did:plc:gteyzzitmjhuezvsi6nyrszj",
"verificationMethods": {
"atproto": "did:key:zQ3shXjHeiBuRCKmM36cuYnm7YEMzhGnCmCyW92sRJ9pribSF"
},
"rotationKeys": [
"did:key:zQ3shhCGUqDKjStzuDxPkTxN6ujddP4RkEKJJouJGRRkaLGbg",
"did:key:zQ3shpKnbdPx3g3CmPf5cRVTPe1HtSwVn5ish3wSnDPQCbLJK"
],
"alsoKnownAs": [
"at://mesirii.de"
],
"services": {
"atproto_pds": {
"type": "AtprotoPersonalDataServer",
"endpoint": "https://bsky.social"
}
}
}
There is more detail in the protocol docs, a number of clients in Go, Rust, Python, Javascript, and other languages are available and about 1000 folks are already on the Bluesky-Dev-Discord. The protocol uses HTTPS and XRPC behind the scenes for communication, with a “Lexicon” based schema approach to ensure correct interpretation of data.
Alternative apps like GraySky, FireSky, or SkyPulse are already using the protocol, with more to come.
One way of getting the firehose of all posts on the platform is to register an event listener with the stream and then get “commit notifications” when new posts have been added to the data repositories. This works for new data but not for past events.
Bluesky user Jaz has been working for a while on a system that not only tracks and collects posts from the mainstream in a Postgres database, but also aggregates and visualizes it as an interaction graph (with currently 20k users and 140k connections representing 630k interactions), which is really cool.
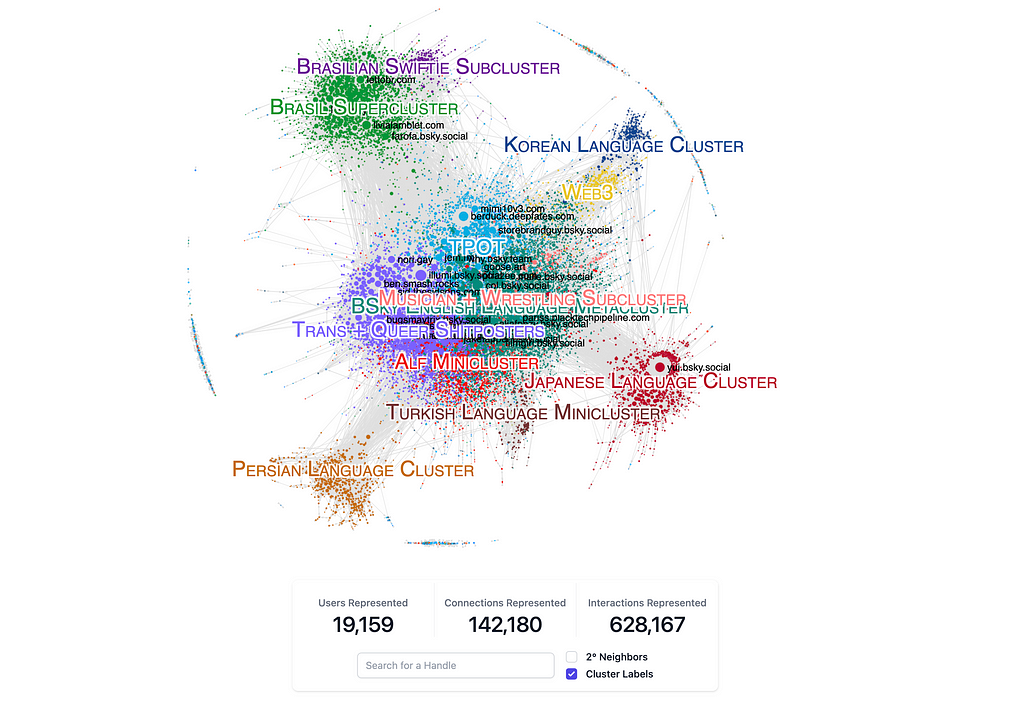
I dived deeper into the topic in my “Coding with ChatGPT” session last week, where we walked through their code in detail, played around with the APIs, and even integrated Neo4j a bit (more to come).
The interaction graph (at least 2 conversations between the users) is kept in memory and can be serialized, rendered, and enhanced with graph algorithms for clustering, centrality-based sizing, and pre-layouting. Jaz uses sigma.js to visualize the already layouted graph in the front-end and add interactivity, like searching for your own handle.
But that goes too deep for today’s “intro to graphs session”.
Here we just want to import the interaction graph from Jaz’s precomputed data and visualize and query it in Neo4j and run some graph algorithms on the data for clustering and sizing, as Jaz did for pre-computation.
Fortunately, the data loaded into the web visualization is available as JSON file with “nodes” and “edges” entries that allow us quickly to construct the graph.
To run the graph algorithms on our data, today we will provision an AuraDS (data science) instance, that’s optimized for this purpose and has the graph-data-science library installed.
You can also use the blank Neo4j Sandbox or a local installation with Neo4j Desktop or Docker.
The minimal instance size is a bit overkill for our uses, it could easily manage 1000 times more data, but it’s easiest to use and set up. Initially, the estimator allows you to provide your data volume and the algorithms you want to use and gives you an instance size.
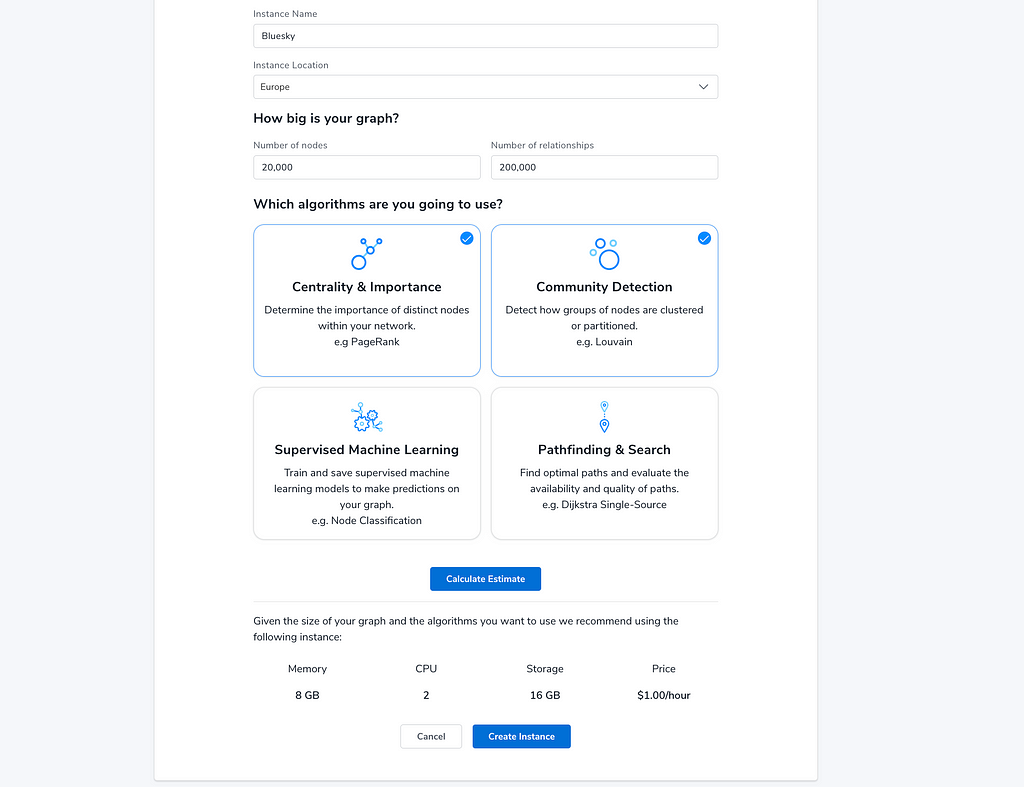
While creating the instance, make sure to download the credentials file with the database URI, username, and password.
To import the data we open “Neo4j Workspace” with the “[Open]” button and provide the password.
Then we can visit the “Query” tab to get started with our quick import.
Our data model is really simple, we have User nodes that are connected by an INTERACTED relationship. Both of which have a number of attributes (key, label (handle), size, weight, color, community, x,y) that we can take from the JSON directly.
Let’s first create a constraint for User and key so that we can ensure uniqueness and can look the users up quickly by key to connect them.
create constraint user_key if not exists for (u:User) require (u.key) is unique;
Originally I had also created a constraint for the user name (aka label in the data) but there was a duplicate user, that we need to merge first. But more about that later.
Next, we can look at some entries from the file, we use the user-defined procedure apoc.load.json to load the file and a JSON-Path expression, to grab the “nodes” entries.
call apoc.load.json("https://bsky.jazco.dev/exported_graph_minified.json","$.nodes")
yield value as nv
return nv limit 5;
Which returns the structure in the file as Cypher constructs, nested maps (dicts), and lists(arrays).
{
attributes: {
area: 9.51,
size: 3.48,
color: "#7EC0EE",
x: -824.56,
y: -6222.31,
label: "maxberger.bsky.social",
community: 1,
key: 1
},
key: "1"
}
So we see we can create the user with the key as id and set the other attributes. Which is what we’re going to do.
Note: We’re going to use MERGE to make our operation idempotent (it’s a get-or-create), we can re-run as often as we want. And we’re using batches of 10k rows, not so important with 20k users but think about all the millions to come.
We’re also removing key from the attributes before adding them to the nodes, because it’s a different datatype (string vs. integer).
call apoc.load.json("https://bsky.jazco.dev/exported_graph_minified.json","$.nodes")
yield value as nv
call { with nv
merge (n:User {key:nv.key})
on create set n += apoc.map.clean(nv.attributes,["key"],[])
} in transactions of 10000 rows;
This gives us roughly 19k lonely nodes in our database.
We can style and position them based on their attributes, but without relationships, this is all boring.
So let’s add them, again by first looking at the data and then using it.
call apoc.load.json("https://bsky.jazco.dev/exported_graph_minified.json","$.edges") yield value as ev
return ev limit 5;
Which returns:
{
attributes: {
size: 0.2,
weight: 2,
ogWeight: 2
},
source: "723",
key: "geid_35_0",
target: "15220"
}
So with this data for each edge, we can look up the start and end nodes and then connect them with an INTERACTS relationship and set the attributes from the record on the relationship.
In our MERGE operation here, we leave off the direction as it combines bi-directional interactions.
call apoc.load.json("https://bsky.jazco.dev/exported_graph_minified.json","$.edges") yield value as ev
call { with ev
match (source:User {key:ev.source}),(target:User {key:ev.target})
merge (source)-[r:INTERACTED {key:ev.key}]-(target)
set r += ev.attributes
} in transactions of 20000 rows;
With the data in the graph, we can now start exploring it, head over to the explore tab, and follow along.

Instead of describing all I did with screenshots, why don’t you just watch the 5 minutes section of the stream below (from 25:30)?
At this point, we have:
- explored the interaction graph visually, expanding relationships and loading additional data,
- styled nodes and relationships based on community, size, and weight attributes,
- ran graph algorithms (Louvain for clusters and page rank for size/importance) and used the results for styling,
- layout the graph both naturally with force layout as well as with the pre-computed x,y-values from Jaz with coordinate layout, and
- used filtering to dismiss the low-weight (2,3) relationships.
Discovering Neo4j AuraDB Free with Michael and Alexander – Importing Bluesky User Interactions
More recently, Jaz has been working on rendering large threads (like the Hellthread with more than 10000 posts) visually.

As those thread visualizations also contain posts, I wanted to import them too.
So let’s grab the data and have a quick look.
call apoc.load.json("https://bsky-search.jazco.io/thread?authorHandle=ihatenfts.hellthread.vet&postID=3jv6terdbop2z&layout=true","$") yield value as post
RETURN count(*);
// 10939
call apoc.load.json(https://bsky-search.jazco.io/thread?authorHandle=ihatenfts.hellthread.vet&postID=3jv6terdbop2z&layout=true","$") yield value as post
RETURN post limit 5;
{
depth: 2,
post: {
root_post_id: "3juzlwllznd24",
parent_relationship: null,
author_did: "did:plc:pbxv2f7r5eo47e3ylwczhk32",
has_embedded_media: false,
parent_post_id: "3juzoytvr7s2y",
created_at: "2023-05-05T19:35:36.601-07:00",
id: "3juzp3fjlds26",
text: "Were you supposed to tag someone?"
},
x: 1657.06,
y: -344.76,
author_handle: "kentbye.com"
}
So we see we have the author handle and did, the post id, text, and created_at, and if it has embedded media. The parent post id links it to the previous post in the thread (parent-relationship is always null) and the root post-id is a reference to the post that started the thread (one without parents).
So we can use this to create the structure of:
(:User {did, label/handle})-[:POSTED]→(p:Post {id, text, created, media, root})-[:PARENT]→(parent:Post)
But first, we need to fix the duplicate users in our source data that we have already imported. Fortunately, there is only one duplicate user with the same label (handle) but different keys.
We can group users by label, count occurrences and collect the entries into a list users. For all labels that have a count greater than one, we merge that list of nodes into a single node while preserving the relationships.
Our friend here is apoc.refactor.mergeNodes which does exactly that.
match (u:User)
with u.label as label, count(*) as count, collect(u) as users
where count > 1
call apoc.refactor.mergeNodes(users) yield node
return node;
Now we can create the constraint for that property, so we can look up users quickly by labeling and connecting them to their posts.
create constraint user_label if not exists for (u:User) require (u.label) is unique;
Now let’s run the import statement, to pull in the Hellthread.
- load the posts as a stream
- batch in transactions of 10k
- get-or-create Post with id
- set attributes (x,y,depth) from entry
- set attributes (root, media, created_at, text)
- get-or-create parent-post
- connect to parent-post
- get-or-create author user
- connect to author
call apoc.load.json("https://bsky-search.jazco.io/thread?authorHandle=ihatenfts.hellthread.vet&postID=3jv6terdbop2z&layout=true","$") yield value as entry
call { with entry
with entry, entry.post as post
merge (p:Post {id:post.id})
set
p += entry {.depth, .x, .y},
p += post { .root_post_id, .has_embedded_media, created_at: datetime(post.created_at), .text}
merge (parent:Post {id:post.parent_post_id})
merge (p)-[:PARENT]->(parent)
with *
merge (u:User { label: entry.author_handle})
set u.did = post.author_did
merge (u)-[:POSTED]->(p)
} in transactions of 10000 rows;
// Created 10995 nodes, created 21878 relationships, set 98507 properties, added 10995 labels
Now we have a nice subset of posts to explore paths and threading in our database.
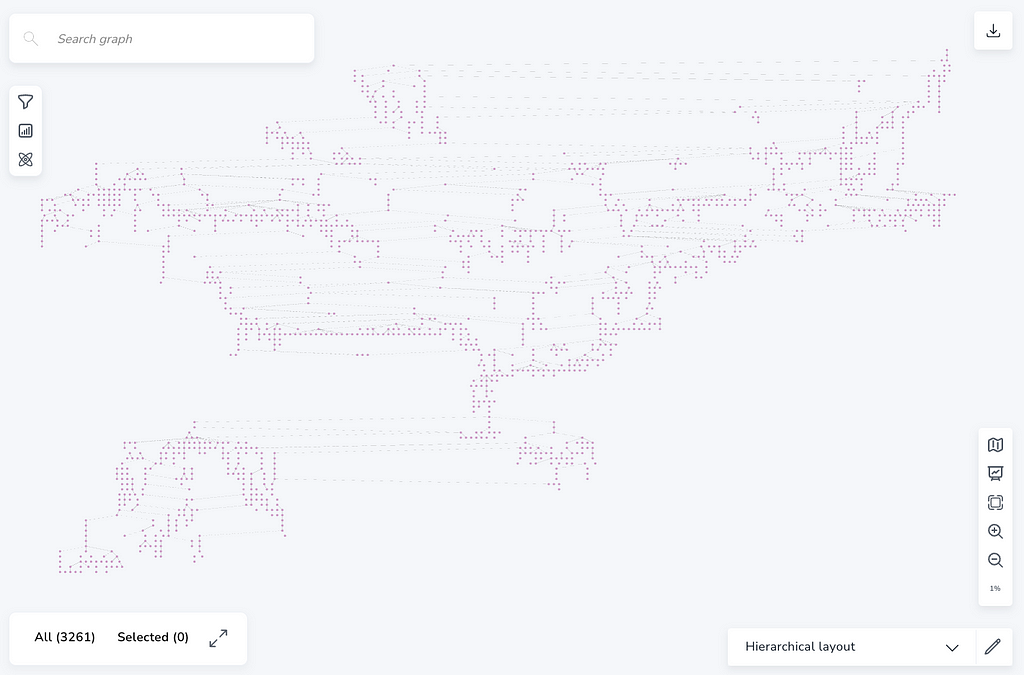
A basic pattern (post:Post)-[:PARENT]→(parent:Post) can be extended to a variable length one by adding a star. Like here for 50 hops: (post:Post)-[:PARENT*50]→(parent:Post)
So if we fetch that single path or a few, we get a nice long chain (or tree)
MATCH path = (post:Post)-[:PARENT*50]->(parent:Post)
RETURN path LIMIT 50
But “Explore” is much better with the hierarchical layout, or coordinate layout of the pre-computed thread visualization. Also its WebGL-based layout and rendering scales better than the d3 one in Query.
We can now find the shortest paths between users, e.g. via the interaction network, or via posts in the thread(s), either visually in the context menu in Explore or with the following statement.
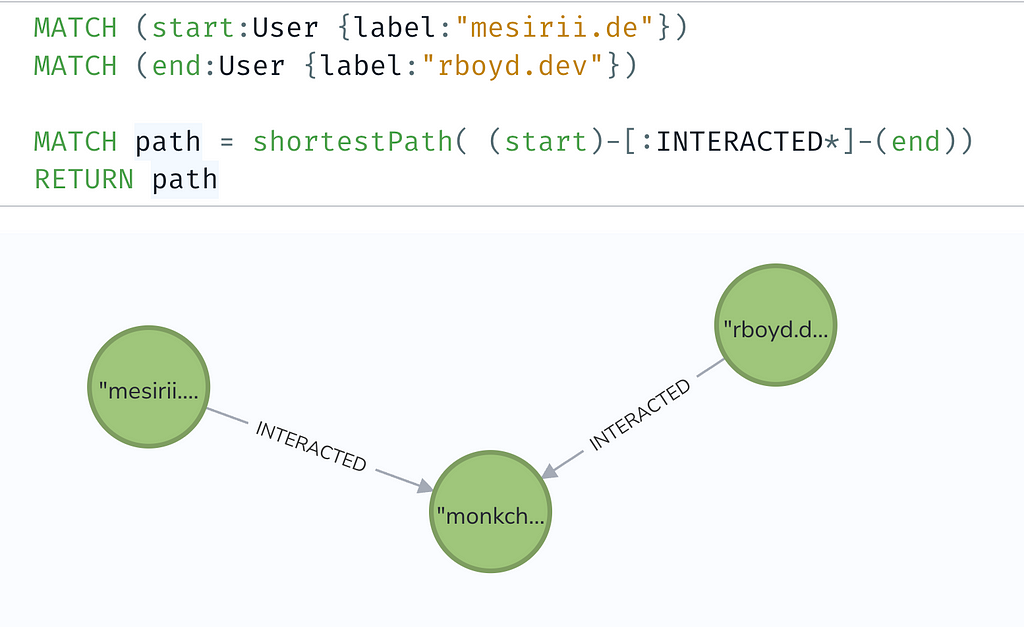
MATCH (start:User {label:"mesirii.de"})
MATCH (end:User {label:"rboyd.dev"})
MATCH path = shortestPath( (start)-[:INTERACTED*]-(end))
RETURN path
As you can see, even my friend Ryan and I need James Governor to mediate 🙂
You can find the code we used today in my GitHub Gist.
Happy socializing and graphing. Be kind.
The next thing I want to write up is how to use the Bluesky data captured in Postgres by zhuowei to import the users, posts, likes, and follows graph into Neo4j. Already got the CSV dumps imported. But that’s for the next blog post 🙂
Bluesky User Interaction Graph — Discover AuraDB Free (Week 47) was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles





How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs
