


Introducing Concurrent Writes to Cypher Subqueries

Product Manager, Neo4j
9 min read


Create and update graph structures in parallel
Neo4j has received some important performance-enhancing product updates in recent months, including both the Parallel Runtime, which increases the speed of read operations, and the introduction of our next-generation Block store format.
Read: Speed Up Your Queries With Neo4j’s New Parallel Runtime
With the recent 5.21 update, we turn our attention to write performance with the release of the CALL {}… IN CONCURRENT TRANSACTIONS (CICT) feature, which brings a similarly impressive performance boost to write queries.
To understand CICT, it’s helpful to talk a little about the history of the CALL {}… IN TRANSACTIONS (CIT) feature that it builds upon.
This feature is useful with large-scale data inserts or graph updates (migrations, refactorings, and deletions) that would result in huge transactions.
Introduced in Neo4j 4.2, CIT helps you deal with the memory issues sometimes encountered when executing large transactions where the memory required exceeds that available in the configured transaction pool, leading to aborting the transaction.
CIT gives us a Cypher-native way of splitting transactions into batches of rows; breaking those updates into multiple smaller transactions, which each consume less memory.
CIT’s purpose is not only to improve query performance, and these batched subqueries are executed in a single CPU thread — not in parallel.
For this reason, many have continued to use apoc.periodic.iterate to speed up large, independent write transactions because it provides a way of executing queries in parallel (i.e., using multiple CPU cores to run a single query).
Using APOC is less effective for several reasons: APOC procedures need to treat Cypher queries as string parameters, and as such, they can become more difficult to edit, with no syntax support from tools like the Neo4j language server. They are also more difficult to read than regular Cypher. APOC procedures also have to go through the whole Cypher stack for every statement execution.
Since APOC is an external library, the Cypher planner has less ability for query optimizations, and the Cypher runtime has less capacity for memory management.
The introduction of CALL {}… IN CONCURRENT TRANSACTIONS now gives us an official and familiar Cypher syntax for executing the batched subqueries generated by a CIT subquery across multiple CPU threads, using a similar approach to the Parallel Runtime, by distributing the available work across a pool of workers.
CICT will be particularly useful for large and long-running data loading operations such as LOAD CSV — where the statement uses a lot of transactional memory, which will benefit from batching, and generates a large number of batches, which will benefit from concurrent processing.
To demonstrate how CICT can significantly speed up workloads, I set up a simple test to load 2 million (synthetic) customer records into an empty database using LOAD CSV. I used Neo4j Desktop on a Windows 11 laptop with 64GB RAM and 16 CPU cores (i9 processor), which should provide a good demonstration of how well CICT can exploit those additional CPU threads.
A Simple Experiment
To begin, I created an empty Neo4j 5.21 database and edited the configuration file to set my initial heap size to 2GB (maximum heap to 8GB) and assigned 2GB to my page cache. You can download the dataset to replicate these tests yourself.
My first step was to try loading the data using a basic, naive loading strategy with LOAD CSV:
LOAD CSV WITH HEADERS FROM 'file:///customers-2000000.csv' AS row
CREATE (c:Customer {C_Id: row.`Customer Id`, firstName: row.`First Name`, lastName:row.`Last Name` , company: row.`Company`, city: row.`City`, email: row.`Email`})
RETURN row.`'Customer Id'`as cid,row.`Company` as company
Unsurprisingly, attempting to pass 2 million nodes with their properties into my heap quickly resulted in an out-of-memory error, but rewriting the query to use CALL {}… IN TRANSACTION allowed the data load to complete.
Note the :auto prefix in Neo4j Browser (to indicate that transaction management is handled by Cypher itself); it’s not necessary in cypher-shell or Neo4j Workspace.
:auto
LOAD CSV WITH HEADERS FROM 'file:///customers-2000000.csv' AS row
CALL {
WITH row
CREATE (c:Customer {C_Id: row.`Customer Id`, firstName: row.`First Name`, lastName:row.`Last Name` , company: row.`Company`, city: row.`City`, email: row.`Email`})
RETURN row.`'Customer Id'`as cid,row.`Company` as company
} IN TRANSACTIONs OF 500 ROWS
ON ERROR CONTINUE
REPORT STATUS AS s
with cid, company, s where s.errorMessage is not null
RETURN cid, company, s
This time, we could add all 2 million nodes and labels, and set 12 million properties in 30 seconds.
Next, I added the new CONCURRENT modifier. Not knowing how many CPU threads would make a difference, I initially selected 4.
Note: In all the examples here and below, I deleted all elements in the database and restarted the server after each run to ensure that the database was not able to use page and query caches to speed up its responses.
:auto
LOAD CSV WITH HEADERS FROM 'file:///customers-2000000.csv' AS row
CALL {
WITH row
CREATE (c:Customer {C_Id: row.`Customer Id`, firstName: row.`First Name`, lastName:row.`Last Name` , company: row.`Company`, city: row.`City`, email: row.`Email`})
RETURN row.`'Customer Id'`as cid,row.`Company` as company
} IN 4 CONCURRENT TRANSACTIONs OF 500 ROWS
ON ERROR CONTINUE
REPORT STATUS AS s
with cid, company, s where s.errorMessage is not null
RETURN cid, company, s
This time, the query completed in 6.3 seconds — almost five times faster than the non-concurrent version of the same query! And that was with CONCURRENCY set to just 4. So let’s add more workers and see how much faster we can complete the data load. With 12 CONCURRENT TRANSACTIONS OF 500 rows, the data load operation completed in just 5.6 seconds. With 16 CONCURRENT TRANSACTIONS, that dropped to just 4.5 seconds.
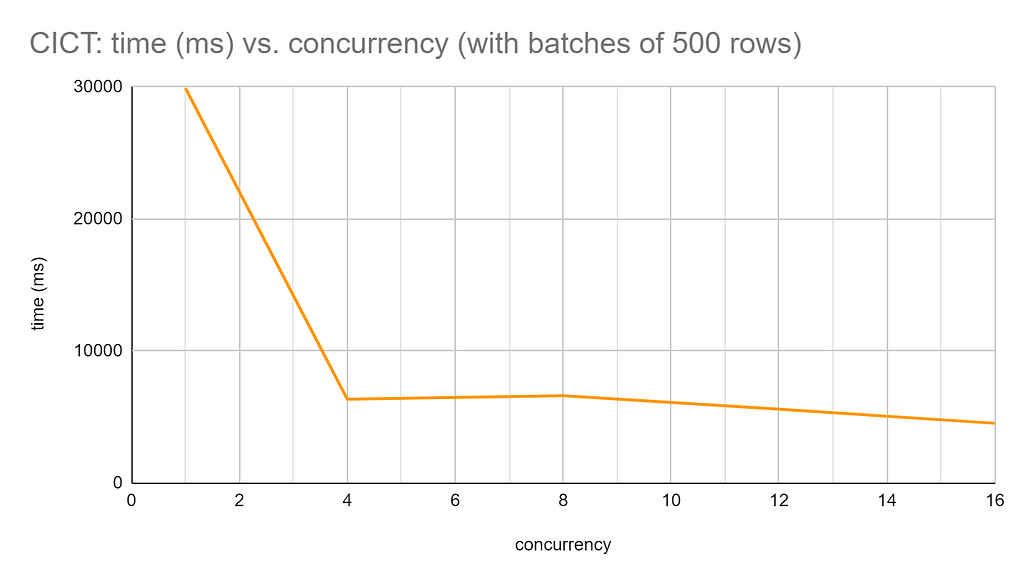
So, without using CALL {}… IN TRANSACTIONS at all, the LOAD CSV operation ran out of transaction memory and could not be completed.
With CALL {}… IN TRANSACTIONS, in batches of 500 rows, the load operation completed in about 30 seconds. With CICT, I got the response time down to about 4.5 seconds. With very little effort, CICT gave me a 600-percent performance increase.
I wondered about further optimizations: Could increasing the number of rows per batch reduce the number of intermediate transactions and, therefore, improve overall performance? This proved not to be the case. With 4 CONCURRENT TRANSACTIONS, increasing the batch size to 10,000 rows slowed the performance, taking more than 12 seconds to complete, compared to the 6 seconds achieved with batches of 500 rows.
Similar tests showed comparable results: 12 CONCURRENT TRANSACTIONS OF 50000 ROWS took 12.7 seconds to complete, compared to 6.7 seconds when configured for just 500 rows. So, for my LOAD CSV query at least, the best recipe seems to be small batch sizes with high concurrency.
Luckily with Neo4j, you won’t often need to think too much about balancing concurrency and batch size when using CALL {}… IN CONCURRENT TRANSACTIONS because the database actually does a pretty good job of working out the concurrency level. Together with CIT, the default batch size (1,000), it delivers good performance, at least for my experiment. Omitting concurrency and batch size values from our LOAD CSV query altogether returned a result in a fairly swift 7.5 seconds:
:auto
LOAD CSV WITH HEADERS FROM 'file:///customers-2000000.csv' AS row
CALL {
WITH row
CREATE (c:Customer {C_Id: row.`Customer Id`, firstName: row.`First Name`, lastName:row.`Last Name` , company: row.`Company`, city: row.`City`, email: row.`Email`})
RETURN row.`'Customer Id'`as cid,row.`Company` as company
} IN CONCURRENT TRANSACTIONS
ON ERROR CONTINUE
REPORT STATUS AS s
with cid, company, s where s.errorMessage is not null
RETURN cid, company, s
That result compares favorably with some of the more fine-tuned results above. So in many cases, you can happily just use IN CONCURRENT TRANSACTIONS and not worry about the details.
Deleting Your Data
I mentioned above that while running my LOAD CSV experiment, I cleared out the database and restarted the server between each query run. If you decide to replicate my experiment, you may well find that deleting 2 million nodes and their properties presents a challenge, given that a simple DELETE query is unlikely to complete unless you have a larger amount of memory allocated to your heap. Fortunately, CIT and CICT offer us some help with large deletions, as well as large data loads.
Here is a simple CIT query (with no concurrency) that batches deletions:
:auto
MATCH (n)
CALL {
WITH n
DETACH DELETE n
} IN TRANSACTIONS OF 10000 ROWS
CICT can help us speed it up, allowing us to batch our deletes and execute them concurrently across a number of workers. (Note that I have not defined the specific level of concurrency here; I decided the database could work out the optimal settings.)
:auto
MATCH (n)
CALL {
WITH n
DETACH DELETE n
} IN CONCURRENT TRANSACTIONS OF 10000 ROWS
It takes about 2 seconds to delete the 2 million nodes.
Good to know:
- If you delete complex graph structures concurrently, the underlying infrastructure sometimes takes locks in non-suitable ways, leading to deadlocks. It is more sensible to go back to single threaded deletion with larger batch sizes.
- Due to Cypher’s isolation properties (to avoid acting on data that was just updated), it inserts an Eager Operator for execution boundaries (i.e., everything before the boundary has to be executed before the next operation can be run). This has gotten much better in recent versions, but can still sometimes cause excessive memory usage issues before your update operation starts. In those cases, APOC’s
apoc.periodic.iteratewith its different (more loose) semantics can still be useful.
Summary
I hope this introduction to CALL {}… IN CONCURRENT TRANSACTIONS will encourage you to try it for yourself. In particular, you should find that replacing any existing usage of apoc.periodic.iterate with the new Cypher syntax provides simpler, cleaner code, with performance at least as good as APOC without the APOC drawbacks. We can also look forward to some further performance enhancements coming soon. Until then, we are always happy to hear from Neo4j users with news of your experiences and any questions.
Introducing Concurrent Writes to Cypher Subqueries was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.




