Create Neo4j database model with ChatGPT

Full Stack Developer
4 min read

Proper modeling of a graph database may be challenging. Because it requires a little bit of a different approach than relational database, we need to take into consideration what types of questions we want to answer.
Luckily, nowadays we can use tools like ChatGPT that can help us to model our data. Of course, it won’t replace a skilled data engineer; however, it can be a good starting point to evaluate our problem. Let’s check how it will perform with the semi-real case (it’s something that I’m working on after hours).
The problem
I have a son with Down Syndrome and it’s challenging to track all the supplements he takes and their influence on all the processes in the body.
So I want to build a database of supplements and their ingredients. Here are few informations I’d like to include in the database:
- supplements can have multiple ingredients
- supplements are branded
- each supplement ingredient can have influence on processes in the body
- some supplements can be taken together to increase their effect
- some supplements cannot be taken together and there must be time between intakes to reduce harm
- to check if a supplement works, some blood tests must be performed
- effects of the supplement should have a reference to the docs (medical publications, official papers, etc.) to support its influence, as well as supplements that should/could be intaken together.
Let’s try ChatGPT!
OK, so now it’s time for a try. Let’s just throw the questions right into ChatGPT and see what happens:
The question / prompt:
The response:
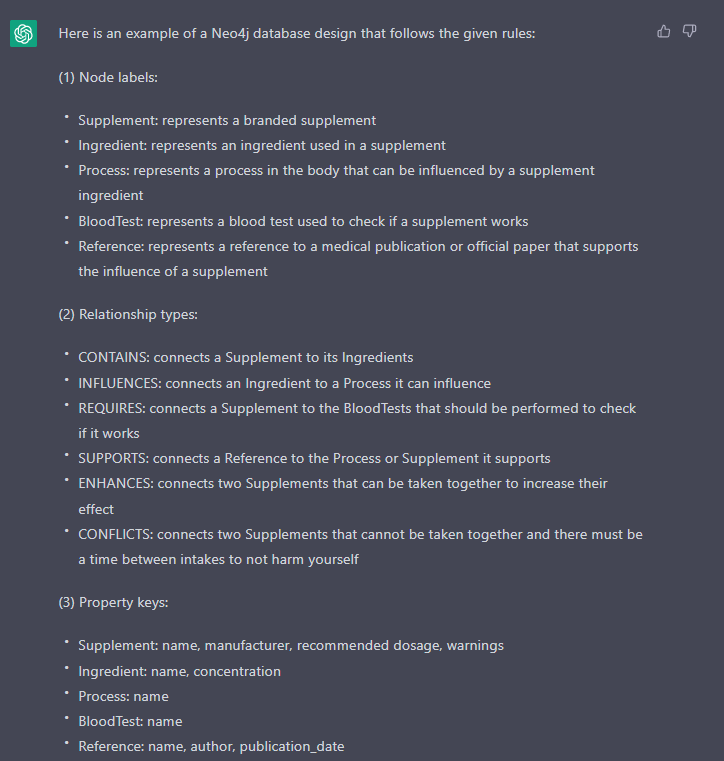
Pretty cool, although we would like to have a manufacturer as a separate node. Let’s add that requirement:

Now, let’s ask for CYPHER queries that can answer some of our questions:
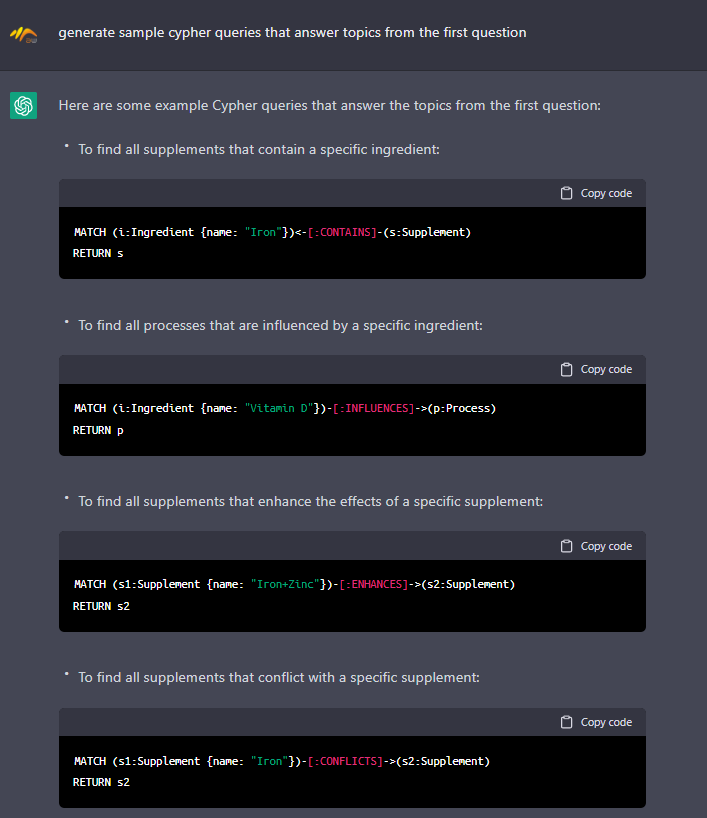

Looks pretty good, but it’s not ideal.
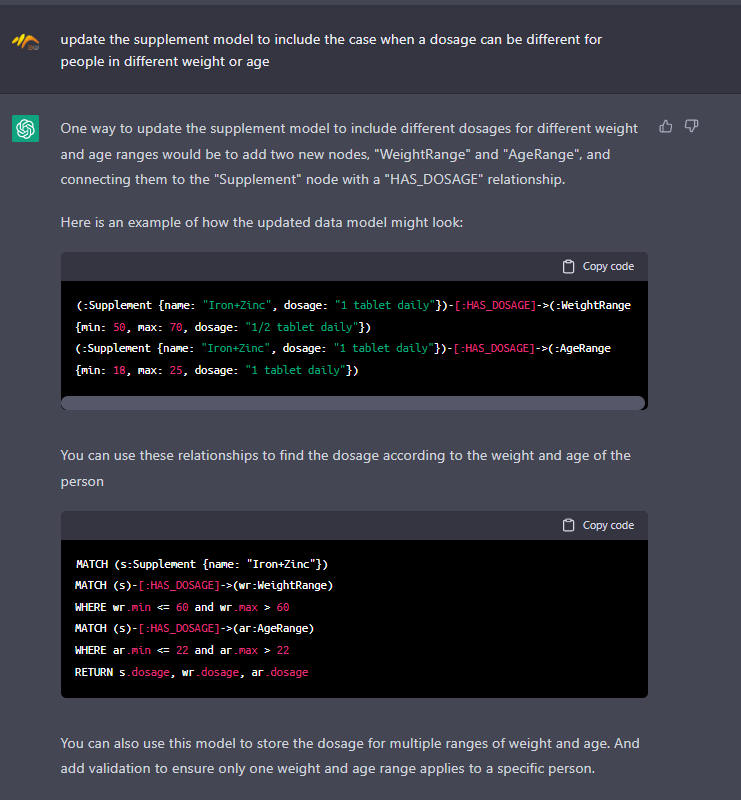
If we want to enhance a particular item, we could also use chat for that. Take a look at the Supplement and the dosage property. It does not include a case when a child is growing and may need different volumes of the supplement depending on age or weight. Let’s update the model.
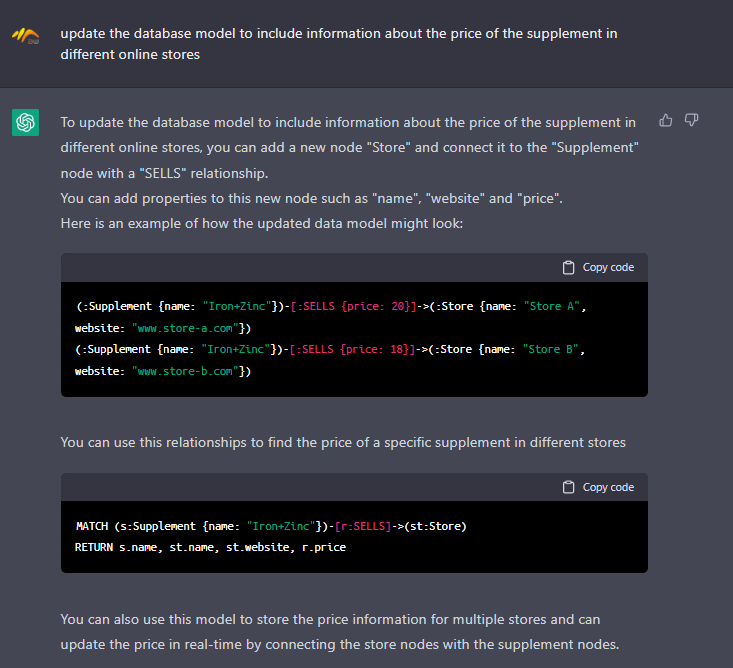
Or, if we want to add some information about any node, for example, the cost of the supplement in different online stores.
We also can ask about Cypher code that generates the sample database so we could play with it:
give me the Cypher code for the latest version of the entire model

And it will give it to us. We can even ask for more data to be returned, and it will generate a few items, too:
generate dummy data for all nodes and relationships

As well, it will return some more results.
Although, I don’t want to ask too much, just in case AI takes over the world and wants to exterminate all humans — perhaps it will spare me 😉
Conclusion
As you can see, ChatGPT can be pretty useful to generate basic data model. And the more specific you are, the better results you’ll get. The nice thing about it is that it has the context of the entire conversation. So it’s pretty comfortable. As a parent of a kid with DS, or even as someone who wants to track all the supplements I take, I see this chatbot as an opportunity to make some parts of building applications easier. And fun.
For more explorations of ChatGPT with Neo4j also see:
Week 38 — Exploring ChatGPT for Learning, Code, Data, NLP and Fun
Create Neo4j Database Model with ChatGTP was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report


