Exploring fraud detection with Neo4j & Graph Data Science – summary

AI Research Engineer, Neo4j
3 min read

Fraud Detection is one of today’s most challenging data science problems. Thankfully, Neo4j Graph Data Science (GDS) offers practical solutions that empower data scientists to make rapid progress in fraud detection analytics and machine learning.
Summary
Whether you are responsible for combating financial crimes, online identity theft, or smuggling or trafficking operations, you are aware of the significant costs incurred when fraud goes unnoticed for too long. There are massive benefits to be gained if only you could leverage data science and machine learning to detect more fraud earlier.
Despite this, viable fraud detection remains one of today’s most challenging data science problems. This is because fraud detection has a unique quality — the entity you want to predict is trying assiduously to prevent you from doing so. It’s not just a “needle-in-the-haystack” problem. In this case, the proverbial needle is actively trying to hide from your detection.
Fortunately, graph-based approaches explicitly model relationships between entities in the data. This, coupled with the intuitive analytics capabilities of Neo4j Graph Data Science (GDS), empower practitioners to rapidly explore, analyze, resolve, and predict fraud entities and patterns. Patterns which would otherwise remain obfuscated and challenging to infer in other data models.
In this blog series, we will explore how Neo4j and GDS can be practically applied to a fraud detection workflow. We will explore a real anonymized data sample from a peer-to-peer (P2P) payment platform, identify fraud patterns, resolve high risk fraud communities, and apply recommendation methods and machine learning.
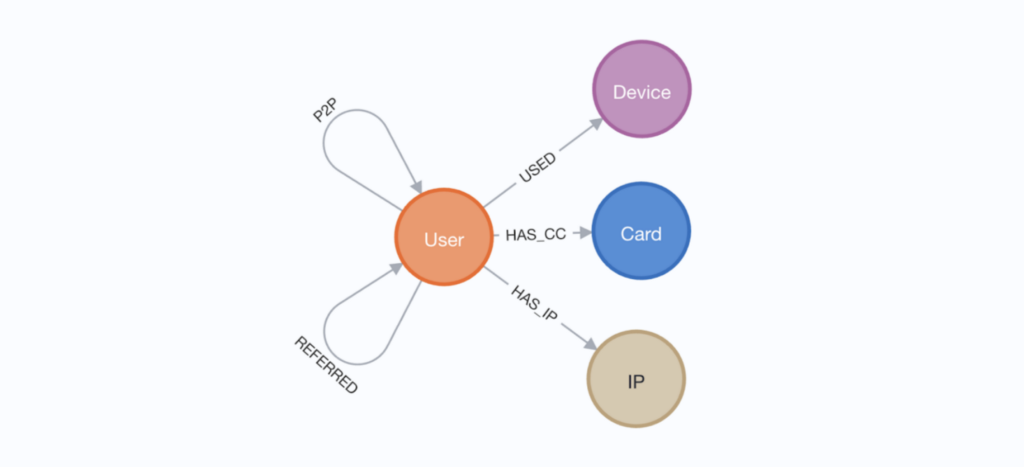
Using this real P2P data, and with little knowledge beforehand, we will identify new fraud risks that went undetected with non-graph methods, increasing the number of flagged users by 87.5 percent. We will also demonstrate methods to further recommend similar suspicious user accounts and train a machine learning model to predict similar fraud risks.
While we focused on this specific P2P sample dataset here, the methodologies introduced are highly scalable and transferable to a broad range of fraud detection use cases. It is designed to be representative of a more general graph workflow where the goal is to identify sparse instances of people and organizations who attempt to hide their identities while performing nefarious activities.
Want to learn more?
- Part 1: Exploring Connected Fraud Data
- Part 2: Resolving Fraud Communities Using Entity Resolution & Community Detection
- Part 3: Recommending Suspicious Accounts With Centrality & Node Similarity
- Part 4: Predicting Fraud Risk Accounts With Machine Learning
Exploring Fraud Detection With Neo4j & Graph Data Science — Summary was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Learn how to build more accurate, sophisticated fraud detection applications with graph databases. Download the free ebook, Accelerate fraud detection with graph databases.
Share Article



Explore
Related Articles
Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report


Fraud rings hide in the connections: Graph-Enriched Detection for Databricks Genie with Neo4j

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3
