
Exploring the Pandora Papers with Neo4j

Head of Product Innovation & Developer Strategy, Neo4j
4 min read

The courageous journalists of the International Consortium of Investigative Journalism (ICIJ) just published a gigantic piece of work: The Pandora Papers.
As you might already know from previous works on the Panama Papers and the Paradise Papers, and several other investigations, the ICIJ takes enormous amounts of leaked information from law firms and banks and spends many months clearing, validating, and researching the data about shell companies, offshore accounts, their secret ultimate owners, (semi-) legal dealings in properties, shares, arms, and more, and publishes local stories simultaneously in many countries.
Pandora By the Numbers
This time the numbers were even more staggering:
- 600 journalists from 150 media outlets in 117 countries
- 2.94 terabytes
- 11.9 million files
- 14 offshore service providers (like law firms and banks)
- Oldest documents from 1970, but most between 1996 and 2020
- Shell companies in 38 jurisdictions, including the United States for the first time
- 27,000 shell companies and 29,000 ultimate beneficial owners
- 130 billionaires (Forbes list)
- 330 politicians from 90 countries
Technology Stack
The ICIJ is a modern organization that uses an open source stack consisting of their datashare platform, machine learning (ML) toolkits in Python, Neo4j, and Linkurious as graph visualization and analytics tooling.
Only 4% of the files were structured, with data organized in tables (spreadsheets, csv files, and a few “dbf files”).
…
In cases where information came in spreadsheet form, the ICIJ removed duplicates and combined it into a master spreadsheet. For PDF or document files, the ICIJ used programming languages such as Python to automate data extraction and structuring as much as possible.
In more complex cases, the ICIJ used ML and other tools, including the Fonduer and Scikit-learn softwares, to identify and separate specific forms from longer documents.
…
After structuring the data, the ICIJ used [graph] platforms (Neo4j and Linkurious) to generate visualizations and make them searchable. This allowed reporters to explore connections between people and companies across providers.
Offshore Leaks Database
In a few weeks, the Pandora Papers data will be published and integrated into the Offshore Leaks database, which is also powered by Linkurious and Neo4j.
Sneak Preview of Power Players Data
Until then, I thought we could at least start to investigate the data of the “Power Players” on our own – those are the illustrious figures that the ICIJ chose to highlight in a dedicated section of the investigation.

This interactive document produced by the ICIJ explores the stories behind the use of offshore companies by high-profile politicians – more than 3,300 in all – or by their relatives or close associates. Among them are 35 current or former country leaders and other prominent politicians and public officials found to have direct connections to structures in tax havens.
A large team of journalists, researchers, and digital artists has unearthed more details about these figures and created interactive and detailed reports on each of them. Be sure to check out the original feature.
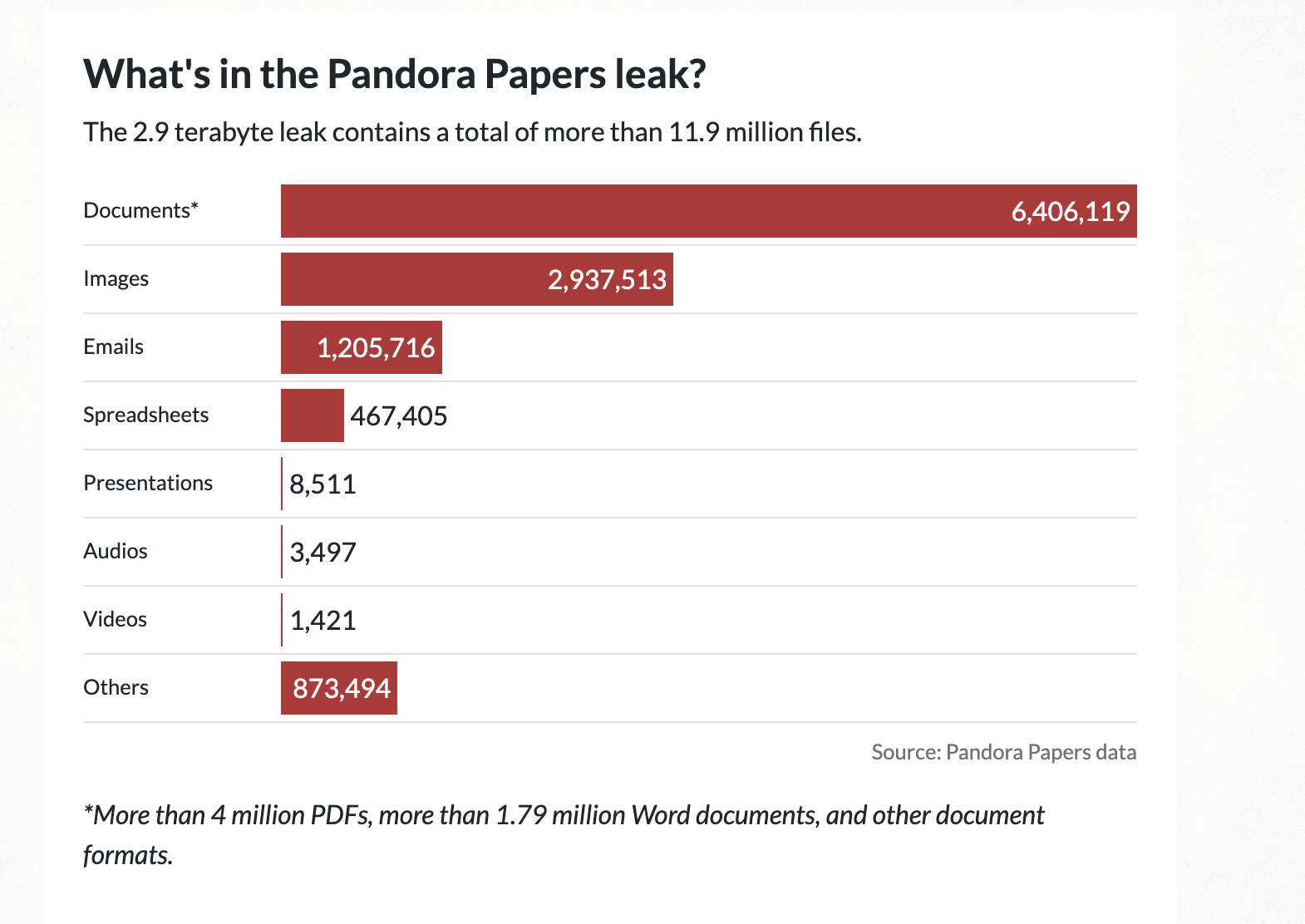
Data Model
For us, the data is the most interesting component. I grabbed the raw data from the interactives and put it into a Neo4j graph database instance to query and visualize. The data model for the ICIJ investigations looks a bit like this.
Where the elements are:
- Entity: shell company or offshore construct
- Intermediary: law firm or bank that helped create and manage the shell company
- Officer: proxy or real owners/shareholders/directors of a shell company
- Address: registered addresses for the entities above
In the current Power Players visualizations, only Officers and Entities are depicted, so we have to wait for the remaining data to become available.
Online Neo4j Database and Import
You can spin up a blank Neo4j Sandbox instance in the cloud, then just run these statements to load the data after logging into Neo4j Browser.
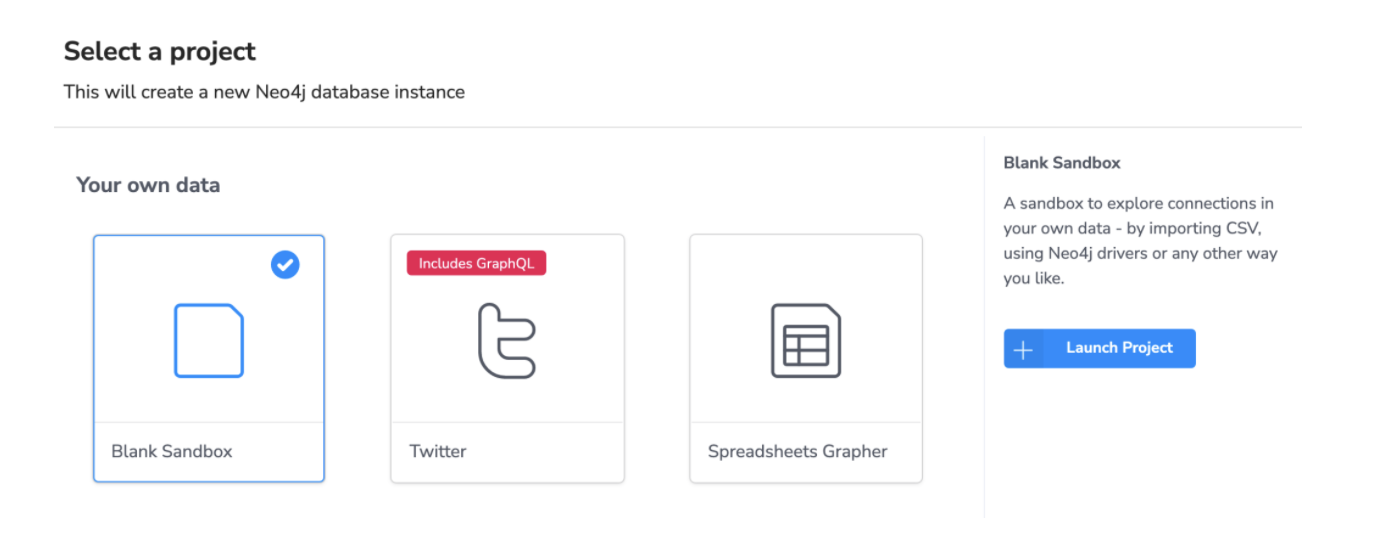

Data Exploration in Neo4j Browser
Then you can start exploring the data e.g. with these queries in Neo4j Browser.
MATCH (o:Officer)-[rel]->(e:Entity) WHERE e.jurisdiction CONTAINS “British Virgin Islands” RETURN o, rel, e

// most frequent providers match (e:Entity) return e.provider, count(*) as c order by c desc;

// most frequent jurisdiction match (e:Entity) return e.jurisdiction, count(*) as c order by c desc;

Here’s an example for the Aliyev family in Azerbaijan.
MATCH (o:Officer)-->(e:Entity) WHERE toLower(o.name) CONTAINS 'aliyev' RETURN *
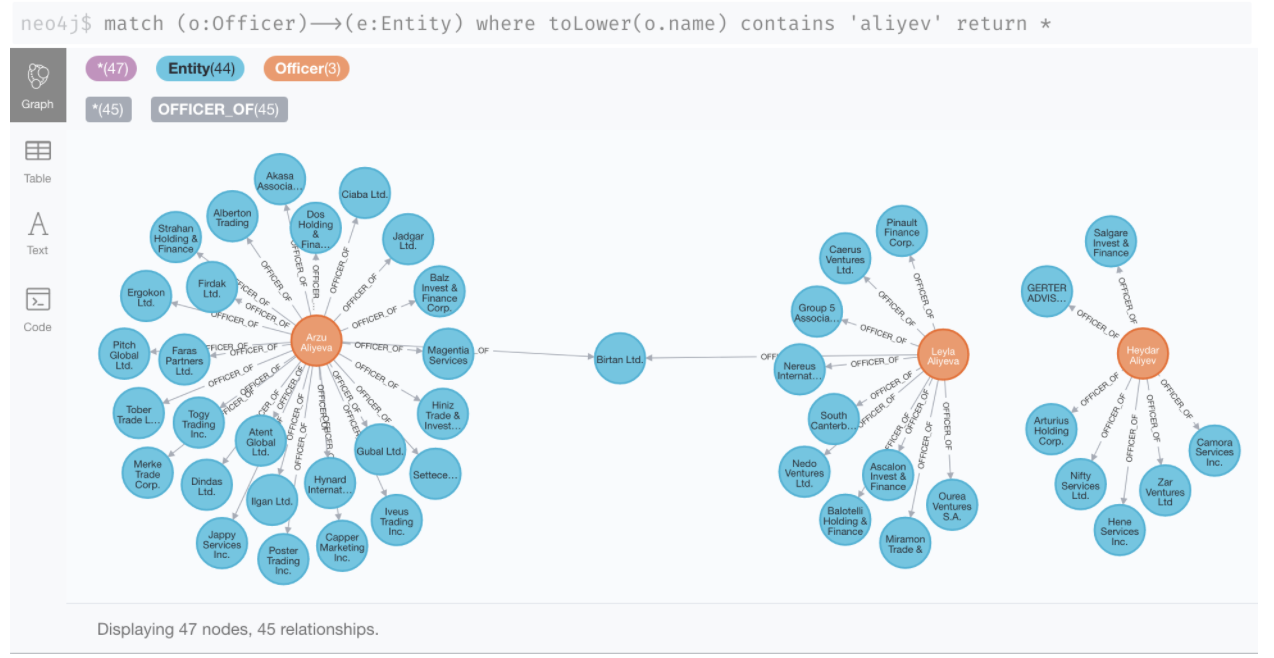
Data Exploration in Neo4j Bloom
Or you can run it visually in Neo4j Bloom, which is even easier, as you can both query with natural language in the search field as well as explore interactively and style and filter the data to your heart’s content. Here is an example for a phrase matching officers involved in more than one entity: “Officer Entity Officer“.
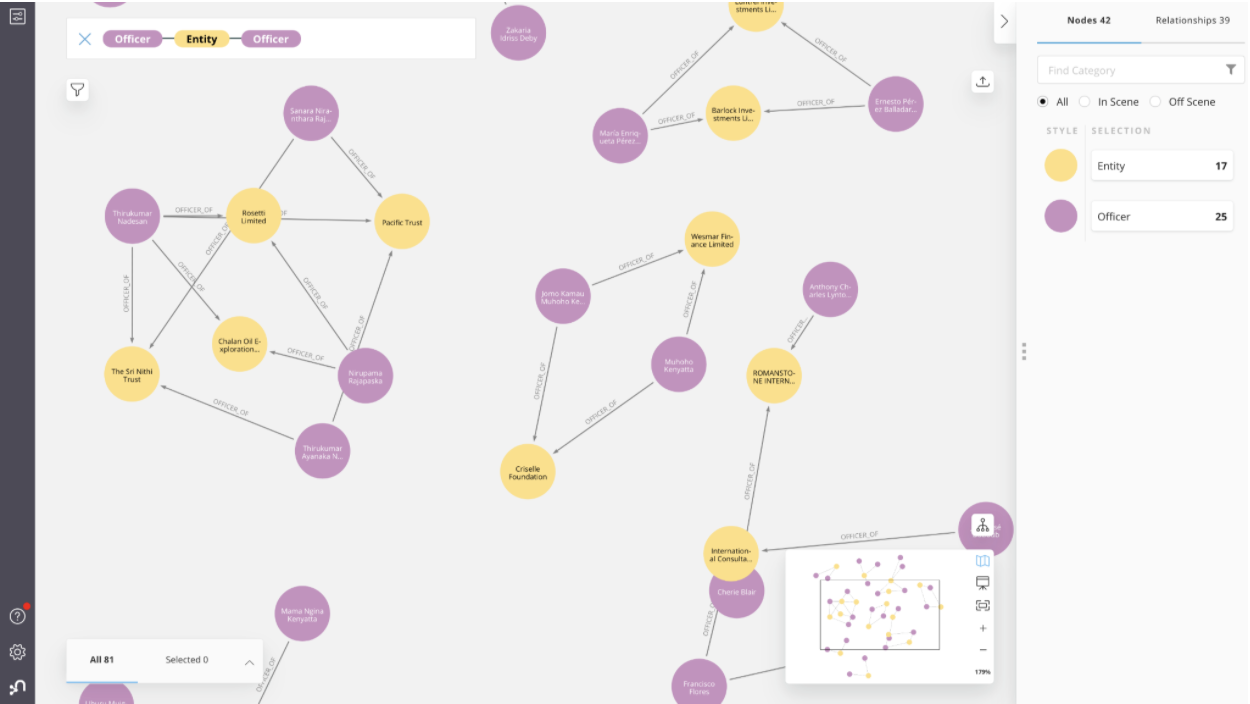
I hope this quick exploration of the “Power Players” mini-dataset was interesting. Now we just have to wait for the public data release from the ICIJ.
Conclusion
Meanwhile, I encourage you to read through publications from the ICIJ and other news outlets on the Pandora Papers, especially those relevant to your local circumstances. And if you can, please donate to the ICIJ so they can continue to do their great research and data work and make all these stories and their data public.
If you can’t wait to get your hands on such data, we have the full dataset of the previous Paradise Papers available in a Neo4j Sandbox.
It would just be great if governments and banks had the same passion, interest, and use of technology for shell-company oversight, tax evasion, and anti-money-laundering (AML) as the ICIJ does.
Share Article



Explore
Related Articles

Mastering Fraud Detection With Temporal Graph Modeling


Text2Cypher Across Languages: Evaluating Foundational Models Beyond English


