


Knowledge Graphs and LLMs: Fine-Tuning vs. Retrieval-Augmented Generation


14 min read

Many organizations are considering LLMs for business use cases like answering questions as chatbots or virtual assistants or generating creative text. However, they usually run into limitations such as knowledge cutoff, hallucinations, and the lack of user customization.
Two approaches that address these challenges are fine-tuning and retrieval-augmented generation. Fine-tuning an LLM involves a supervised training phase, where question-answer pairs are provided to optimize the LLM’s performance. Conversely, in retrieval-augmented generation (RAG), the LLM serves as a natural language interface to access external information, which means it doesn’t rely only on its internal knowledge to produce answers.
This article explores the pros and cons of using fine-tuning and RAG to curb the limitations of LLMs. We also consider the implications of each approach for organizations that already use knowledge graphs to organize and manage their data.
The Limitations of LLMs

After the launch of ChatGPT in November 2022, people began considering integrating LLMs into their applications to generate creative content and solve typical natural language processing tasks like text summarization and translation.
Using LLMs out of the box for business use cases can cause serious issues, though. Let’s explore the most critical concerns.
Knowledge Cutoff
Knowledge cutoff refers to the fact that LLMs are unaware of any events that happened after their training. For example, if you ask ChatGPT about an event that occurred in 2024, you’ll get a response like this:

The same problem will occur if you ask an LLM about any event not present in its training dataset. While the knowledge cutoff date is relevant for any publicly available information, the LLM doesn’t have knowledge about private or confidential information that might be available even before the knowledge cutoff date.
For example, many companies have confidential information they don’t share publicly, but they might be interested in having a custom LLM that could answer questions about that information. On the other hand, publicly available information that an LLM is aware of could already be outdated.
Hallucinations
We cannot blindly believe everything that LLMs produce.
LLMs are trained to produce realistic-sounding output, but it might not always be accurate. Some invalid information is more challenging to spot than others. Especially for missing data, the LLMs are likely to make up an answer that sounds convincing (but is nonetheless wrong) instead of admitting that it lacks the base facts in its training.
For example, research or court citations might be easier to verify. In 2023, a lawyer got in trouble for blindly believing the court citations ChatGPT produced. While people have become more wary since then about the information that public LLMs like ChatGPT and Gemini generate, it’s still risky.
LLMs will also consistently produce assertive yet false information about any sort of identification number, including Wikidata IDs:

In the screenshot above, ChatGPT gave an assertive response, but it’s inaccurate. The Wikidata ID that ChatGPT gave points to a Russian singer.
Other Problems
LLMs also have other problems:
- Bias – LLMs can inherit biases from their training data, leading to discriminatory or unfair outputs.
- Prompt injection – Malicious users can craft prompts that manipulate the LLM to generate harmful or misleading content.
- Common sense reasoning – LLMs often struggle with tasks requiring common-sense reasoning or an understanding of the situation’s context.
- Explainability – It can be difficult to understand the reasoning or sources behind an LLM’s output, which reduces trust in its outputs and complicates debugging efforts.
We won’t explore these in detail for brevity’s sake. Instead, let’s explore your first option for overcoming these challenges: supervised fine-tuning.
Supervised Fine-Tuning of an LLM
Fine-tuning is a targeted training approach for LLMs. It refers to the supervised training phase during which you provide additional question-answer pairs to optimize an LLM’s performance. By repeatedly processing these data samples, the LLM refines its understanding and improves its ability to answer questions or generate text in that specific area.
Fine-tuning lets you use the LLM’s existing capabilities while tailoring it to address your unique needs. If you combine fine-tuning with domain-specific pre-training, you can have a domain-specific LLM to carry out specialized operations in a field such as finance, with increased accuracy.
Note: Two prominent use cases for fine-tuning an LLM are updating and expanding its internal knowledge and fine-tuning a model for a specific task (like text summarization or translating natural language to database queries). You could also prepare a model for creative purposes, such as personalized artistic content generation and analysis of user preferences and behavior patterns for content filtering and recommendation. This article discusses the first use case of using fine-tuning techniques to update and expand the internal knowledge of an LLM.
Where Does Fine-Tuning Fit In?
Explaining in detail how LLMs are trained is beyond the scope of this blog post. If you’re curious, you can watch this video by Andrej Karpathy to catch up on LLMs and learn about the different phases of LLM training.
The first step of creating an LLM involves pre-training a model to develop a base LLM. A base LLM is usually pre-trained using a gigantic corpus of text, frequently in the billions or even trillions of tokens. The cost of training can be upwards of hundreds of thousands or even millions of dollars — something most organizations want to avoid.
Recently, a paper by Microsoft (published in June 2024) showed that techniques like gradient checkpointing and low-rank adaptation can reduce memory bottlenecks during the fine-tuning process. This would make fine-tuning more time- and cost-efficient, but so far, we don’t have any real-world examples that have proved cost reduction.
.](https://dist.neo4j.com/wp-content/uploads/20230608064931/1LTfNOqZQB_M42KyvttjSyw.png)
Therefore, the most common first step is to choose a pre-trained base LLM for your use case. You need to consider several things when making this choice:
- The number of parameters in an LLM determines its capacity to learn and represent complex patterns in the data. Larger models require more computational power and memory for training and inference. They can also have longer training times. Fine-tuning such models can be resource-intensive, necessitating powerful hardware such as GPUs and TPUs.
- The license of the base LLM dictates how you can use the fine-tuned model. Some licenses may have restrictions on commercial use, distribution, or modification. Open source models offer more flexibility for fine-tuning and customization, while proprietary models might provide better performance or specific features but with more restrictive licenses. You must comply with the license terms to avoid legal issues.
- Bias in the base model can be amplified during fine-tuning if not properly addressed, which can lead to unfair or discriminatory behavior by the fine-tuned model. Identifying and mitigating bias needs additional data preprocessing and evaluation steps, including employing data balancing techniques, bias detection tools, and fairness-aware training algorithms. You want to choose a base LLM that has the least known bias in its initial training dataset.
- Toxicity refers to the fact that models can generate toxic or harmful content if they’re not properly controlled. To minimize toxicity, maintain a positive user experience, and prevent harm, you want to filter training data and implement safety layers and continuous monitoring. If possible, also choose a base LLM that has the least known toxicity and includes mechanisms to detect and mitigate toxicity during fine-tuning.
After selecting the base LLM, the next step is fine-tuning it.
Preparing the Training Dataset
The first step of fine-tuning is to prepare the dataset you’ll use to fine-tune the base LLM.
Compared to pre-training, fine-tuning is relatively cheap in terms of computation cost due to techniques like LoRA and QLoRA. However, constructing the training dataset is more complex than the training itself and can get expensive.
Some organizations that can’t afford a dedicated team of annotators go really meta and use an LLM to construct a training dataset for fine-tuning their LLMs. For example, Stanford’s Alpaca training dataset was created using OpenAI’s LLMs. The cost of producing 52,000 training instructions was about USD $500, which is relatively cheap. The Vicuna model was fine-tuned using the ChatGPT conversations users posted on ShareGPT. Training this model cost even less at USD $140.
H2O also developed a project called WizardLM that turns documents into question-answer pairs for fine-tuning LLMs.
However, we have yet to see any implementations around using knowledge graphs to prepare good question-answer pairs that can help fine-tune an LLM to expand its internal knowledge. This is concerning for organizations that rely on knowledge graphs to store their company-specific data. Creating a training dataset from their data store will most likely be problematic for them. A possible way to do this is the community report summarization step in the Graph RAG proposal by Microsoft, but that idea hasn’t been tested yet.
Limitations of Fine-Tuning
A key issue with LLMs is that there are many unknowns currently. For example, can you provide two different answers to the same question, and would the LLM then somehow combine them in its internal knowledge store?
If your organization wants to use data from knowledge graphs to train an LLM, consider that some information in a knowledge graph becomes relevant only when you examine its relationships. Do you have to predefine relevant queries to consolidate these relationships into the training dataset, or is there a more generic way to do it? Or can you generate relevant pairs using the node-relationship-node patterns representing subject-predicate-object expressions?
Those concerns aside, let’s imagine you somehow managed to produce a training dataset containing question-answer pairs based on the information stored in your knowledge graph. As a result, the LLM now includes updated knowledge. Still, fine-tuning the model didn’t solve the knowledge cutoff problem; it only pushed the knowledge cutoff to a later date.
Furthermore, while fine-tuning approaches can decrease hallucinations, they can’t eliminate them. On their own, LLMs can’t cite their sources when providing answers. Therefore, you have no idea if the answer came from pre-training data, the fine-tuning dataset, or if the LLM made it up. If you use an LLM to create the fine-tuning dataset, a falsehood source is also always possible.
A fine-tuned model also can’t automatically provide different responses depending on who asks the questions. Likewise, there’s no concept of access restrictions, meaning that anybody interacting with the LLM has access to all its information.
When to Use Fine-Tuning
Keeping the limitations of fine-tuning in mind, we recommend updating the internal knowledge of an LLM through fine-tuning techniques only for data that changes or updates slowly.
For example, you could use a fine-tuned model to provide information about historic tourist attractions as long as it doesn’t require any specific, time-dependent information. You would run into trouble the second you wanted to include special time-dependent (real-time) or personalized promotions in the responses.
Similarly, fine-tuned models are not ideal for analytical workflows where you might ask how many new customers the company gained over the past week.
Fine-tuning is most useful when your app requires the model to excel in highly specialized tasks or domains. By training the model on specific datasets, you can customize responses to better align with the nuances and details of the particular area of interest. This process enhances the model’s intrinsic understanding and generation capabilities, which makes it better at handling specialized queries and producing more accurate and contextually relevant outputs.
Retrieval-Augmented Generation
The idea behind retrieval-augmented LLM applications is to avoid relying only on internal LLM knowledge to generate answers.
RAG uses LLMs to solve tasks like constructing database queries from natural language and constructing answers based on externally provided information or by using plugins or agents for retrieval. Instead of using the internal knowledge of an LLM, RAG allows you to use the LLM as a natural language interface to your company’s or private information.
How Retrieval-Augmented Generation Works
.](https://dist.neo4j.com/wp-content/uploads/20230608064925/1zydD2GKzjpEyvL-d_cP0vA.png)
RAG uses a smart search tool to provide your LLM with an appropriately phrased question and a set of relevant documents from your data store. It then generates an answer based on information from your data source. This means you don’t rely on internal knowledge of the LLM to produce answers. Instead, the LLM is used only to extract relevant information from documents you passed in and summarize it.
The introduction of agents and tool-calling support has acted as a catalyst for the rise of RAG.
Agents act as intermediaries that connect LLMs to external knowledge sources like databases and APIs. As a result, LLMs can tap into a vast pool of real-time data, overcoming the knowledge cutoff and enabling them to access the latest information. Agents can integrate fact-checking services and verification tools into the LLM workflow, which enhances the trustworthiness of the LLM’s outputs by mitigating the risk of factual errors.
Native tool-calling functionality takes this a step further. LLMs can directly call upon external tools for specific tasks, such as complex calculations or data analysis, which allows them to handle a wider range of problems and expand their overall capabilities. For example, the ChatGPT tools for getting web responses and uploading files for assistance in writing or analyzing can be thought of as a RAG approach to LLM applications. Because the ChatGPT interface has access to the internet, the LLM can search to access up-to-date information and use it to construct the final answer:

In this example, ChatGPT was able to answer who won the NBA MVP in 2024. But, remember the cutoff knowledge date for ChatGPT is January 2022, so it couldn’t know who won the 2024 NBA MVP from its internal knowledge. Instead, it accessed external information from the internet with its Browse with Bing feature, which allowed it to answer the question with up-to-date information. Such features present an integrated augmentation mechanism inside the OpenAI platform.
Implementing Retrieval-Augmented Generation
There are multiple ways in which you can implement RAG in your systems.
LangChain, a library for developing and deploying applications using LLMs, provides tools for integrating LLMs with RAG techniques. You can use the LangChain library to allow LLMs to access real-time information from various sources like Google Search, vector databases, or knowledge graphs.
For example, LangChain has added a Cypher Search chain that converts natural language questions into a [Cypher](https://neo4j.com/docs/cypher-manual/current/introduction/] statement, uses it to retrieve information from the graph database, such as those of Neo4j, and constructs a final answer based on the information provided. With the Cypher Search chain, an LLM is not only used to construct a final answer but also to translate a natural language question into a Cypher query:
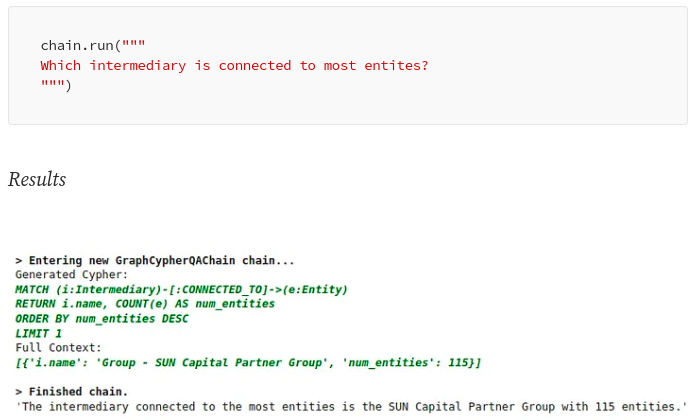
Another popular library for retrieval-augmented LLM workflows is LlamaIndex, formerly known as GPT Index. LlamaIndex is a comprehensive data framework that enhances the performance of LLMs by enabling them to use private or custom data.
LlamaIndex offers data connectors that facilitate ingesting various data sources and formats — including everything from APIs, PDFs, and documents to SQL or graph data — to integrate existing data into the LLM. It also provides efficient mechanisms to structure the ingested data using indexes and graphs, ensuring the data is suitably arranged for use with LLMs. Its advanced retrieval and query interface lets users input an LLM prompt and receive back a context-retrieved, knowledge-augmented output.
LlamaIndex supports creating and connecting to property graph indexes to build a rich knowledge graph from unstructured data and then query it in flexible ways to uncover insights and relationships within your information. You can also skip creating the knowledge graph if you already have one in a graph database tool like Neo4j and use it directly in your LlamaIndex projects.
Because of Neo4j’s native property graph model, knowledge graphs built on Neo4j graph databases can combine transactional data, organizational data, and vector embeddings in a single database, simplifying the overall application design. Pairing it with LlamaIndex’s property graph index lets you create custom solutions to query specific types of information from within the graph.
Advantages and Disadvantages of Retrieval-Augmented Generation
The retrieval-augmented approach has some clear advantages over fine-tuning:
- The answer can cite its sources of information, which allows you to validate the information and potentially change or update the underlying information based on requirements.
- Hallucinations are less likely to occur as the LLM no longer relies on its internal knowledge to answer the question. Instead, it uses information provided in relevant documents.
- It’s easier to change, update, and maintain the underlying information the LLM uses because you transform the problem from LLM maintenance to one involving database maintenance, querying, and context construction.
- Answers can be personalized based on the user’s context or access permission.
However, keep the limitations of RAG in mind:
- The answers are only as good as the smart search tool. Your smart search tool must be able to provide the LLM with the correctly phrased question along with enough relevant documents from your data store.
- The application needs access to your specific knowledge base, whether a database or other data stores.
- Completely disregarding the internal knowledge of the language model limits the number of questions that can be answered.
- Sometimes LLMs fail to follow instructions, so the context might be ignored, or hallucinations could still occur if no relevant answer data is found in the context.
Contrasting Fine-Tuning and RAG for LLMs
The key differences between the two approaches are depicted in the table below:
| Comparison Point | Fine-tuning | RAG |
|---|---|---|
| Data requirements | Large amounts of task-specific labeled data | Pre-trained LLM, separate information retrieval system, potentially some labeled data for generation |
| Knowledge | Adapts internal LLM knowledge for specific task | Integrates external knowledge sources, allowing access to up-to-date information |
| Accuracy and reliability | More accurate for tasks in its domain, prone to hallucinations for out-of-domain | Less prone to hallucinations; accuracy depends on retrieved data and LLM processing |
| Flexibility and adaptability | Requires retraining for different tasks/domains | Easier to adapt to new domains or update knowledge by modifying retrieval system data sources |
| Transparency and explainability | Difficult to explain reasoning behind answer | Allows citation of sources for better transparency |
| Development and deployment | Requires expertise in data preparation and fine-tuning techniques | Requires building or integrating a retrieval system alongside the LLM |
Fine-tuning is well-suited for tasks with a clear and well-defined domain and access to large amounts of labeled data, such as sentiment analysis and database query generation for a specific product. It can update the base LLM’s context with the new data and entirely remove any dependence on external data sources.
However, RAG is more accurate (see this study and this one for a more in-depth look), which means it’s better for tasks that require access to up-to-date information or integrations with existing knowledge bases such as question-answering systems and customer service chatbots.
RAG with graph databases (like Neo4j) offers several advantages. Access to a richer knowledge base with interconnected entities leads to more comprehensive answers, better adaptability to new domains and evolving knowledge, and insights into relationships and data points used by RAG to generate answers. It also offers a level of explainability that fine-tuning lacks, as well as access to the latest information, unlike fine-tuned LLMs that rely on static training data.
Fine-tuning can be used to supplement RAG, particularly when highly specialized knowledge in a well-defined domain is required. However, for most applications, RAG offers a more cost-effective and time-efficient approach. It allows you to directly use a pre-trained LLM with a knowledge store instead of preparing a training dataset and going through the supervised training phase. RAG also doesn’t require the same level of technical expertise as fine-tuning.
The reality is that most companies don’t necessarily need to create custom LLMs for a niche skill. Combining a pre-trained LLM with domain-specific data through RAG is sufficient for companies to use their own data within a powerful language model, making it an attractive option.
Many teams are working on creating ways to effectively implement RAG with graph databases. The term GraphRAG is catching on, with teams from institutions like Microsoft and Emory University, Atlanta putting forth their ideas on how to best use graphs with RAG to improve the results of RAG systems. To learn more about this combination, Neo4j’s GraphRAG Manifesto breaks it down in detail.
Getting Started With Neo4j & LLM
We’re offering a free GraphAcademy course on how to integrate Neo4j knowledge graph with Generative AI models using LangChain.
The Developer’s Guide:
How to Build a Knowledge Graph
This ebook gives you a step-by-step walkthrough on building your first knowledge graph.
Share Article



Explore
Related Articles

Why Healthcare CIOs Can’t Afford to Scale AI Without a Knowledge Graph Foundation

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.


How Graph Intelligence Drives Breakthroughs in Science and Society

