A tale of LLMs and graphs: The GenAI Graph Gathering

Senior Developer Advocate, Neo4j
8 min read

Graph Retrieval-Augmented Generation (GraphRAG) with knowledge graphs is a recent wave in generative AI (GenAI), showing up in research papers, orchestration frameworks, and conferences. This rising interest in using knowledge graphs for memory, explainability, and expanded data representation inspired us at Neo4j to reach out to experts across the space. How much is real? What are the experiences? And where must we learn and investigate more? We realized that we wanted more than one-on-one conversations but also many-to-many conversations. So, at the end of May, we gathered in the beautiful San Francisco Presidio to share, discuss, and learn together.
Neo4j hosted the gathering under the Chatham House Rule to encourage the free exchange of ideas. You can share information and reveal your own attendance, but not attribute or reveal other attendees and affiliations. All mentions in this blog are with permission.
Neo4j was there, of course, the company best known for our open source graph database and augmenting large language models (LLMs) with knowledge graphs. People from across GenAI joined us: LLM creators, RAG orchestrators, knowledge graph designers, researchers, and deep thinkers. Everyone was curious and intent on contributing, with unabated discussion through sessions, Fika breaks, lunch, and dinner.
Framing GraphRAG
Emil Eifrem framed the discussion to start things off, outlining the opportunities and challenges for GraphRAG and sharing some customer insights and questions. His basic premise is that by combining a knowledge graph with an LLM using GraphRAG techniques, you get the creativity of a conversational interface grounded in facts.

The benefits of GraphRAG include higher accuracy, easier development and explainability of results. There are some challenges, though. Knowledge graph construction needs to be more accessible, and there’s a learning curve for developers new to working with graphs.

One important distinction that might not have been obvious initially was the differentiation of the “lexical graph” (think documents, sections, chapters, and chunks with embeddings) and the “domain graph” that represents the traditional entity knowledge graph. Combined, these provide the means to make the right structural and contextual information available for grounding an LLM.

We broke out into group discussions, focusing on knowledge graph construction, GraphRAG techniques, and real-world experience. Here are some highlights from the shared notes compiled by Michael Hunger.
Knowledge graph construction
Generally, a knowledge graph is a data model for representing information using entities and the relationships between them. The specifics get interesting, so that’s what we explored.
Notes:
- One big question was graph data representation inside the database and how to present information to the LLM.
- Are LLMs best for entity extraction? Or are they good enough to get started but too slow/expensive for large volumes, which may then be better served with dedicated Named Entity Recognition (NER) models?
- Most use cases have mixed data, so the data ingestion has to provide the means to construct connections from structured and unstructured information.
Graph retrieval patterns
Independent of data representation, GraphRAG encompasses multiple techniques for information retrieval:
- Information search — Find text that is most likely to have enough information to answer a user question. It could be any form of a lexical graph, from simple chunks to hierarchical summarizations. Here, the graph can help with ranking results through techniques like page rank.
- Pattern matching — Expanding context for indirect yet relevant information. Start with graph pattern matching and include relevant text, or start with relevant text and expand into local graph patterns.
- Graph queries — Directly translate from a natural language question to a database query. This can be powerful when used responsibly.

Notes:
- Many advanced RAG patterns can be easily represented as graphs and used by just querying the data.
- The challenges are with the user context and how to integrate it into the system — an agentic system with generic, text2cypher, and specific tools can help, but also round-trips with clarifying questions.
- The biggest challenges are in evaluating quality, latency impacts of more complex workflows, and the impacts of data quality and schema.
Real-world experience
Chat with your PDF may be the “hello world” of GenAI. What are people actually doing with GenAI applications?
Notes:
- Many RAG applications today are in text-heavy domains like research, legal, and customer support, which explains the dominance of text vector search. As existing enterprise and structured data become more important in GenAI applications, other database models will take over.
- For lexical graphs, the trend is to move beyond chunks to structured document representations with explicit and derived cross-references.
- Additional GenAI use cases for graphs are in conversational memory, personalized systems, and explainability.
Unconference sessions
Following the initial discussions, we followed an unconference format to continue on particular topics.
RAG to GraphRAG — If I have an existing RAG pipeline set up, how do I incrementally add GraphRAG without disruption?
- Green-field RAG projects on unstructured data start with vector databases, but run into problems and limits. There’s an easy path to incrementally add a knowledge graph to the pipeline and start using GraphRAG without disruption.
- A regular database with vector search capability makes advanced RAG patterns and queries easier. Graphs capture high domain complexity and enriched data.
- Requirements include a robust infrastructure, good data engineering/prep, security, and subject-matter expertise to make applications successful.
Evaluation Strategies (Testing)
- The golden dataset/baseline — best human-generated, second-best LLM-generated and validated with human verification.
- LLMs are terrible at numbers both for generation as well as eval — try to map numbers to categories.
- Don’t just do semantic comparisons on generated queries and results but also content verification and quality, especially for query generation.
Graph Agent With AutoGen
- In this session, we did a quick intro to AutoGen and its capabilities for building agentic systems.
- Then we used the time to build a prototypical AutoGen setup for Neo4j — an Assistant agent with access to tools and a managing User Agent that can execute functions.
- Ability to query the database, provide schema in system prompt, iteratively build and execute the Cypher statements and retrieve data, and aggregate information for the answer.
Semantics and Representations of Connected LLM Data
- What kind of structural representation — graph patterns, triples, nested structures (YAML) — is best for interacting with the LLM?
- Can we use the graph to rewrite the original question to match the structural information?
- Can we inversely build up a graph like an index based on embeddings (similarity) and then label nodes and relationships based on meaning?
Multi-Agent Systems
- It’s important to know when to use multi-agent systems because they come with cost (money, latency, error propagation) over regular software for decisions on execution (order).
- Would it make sense to have agents per sub-domain/sub-graph? Specific agents should have subject-matter expertise in addition to generic agents to get started.
- Only call heavyweight agents when necessary, such as for validation on smaller contexts not for generation. Look at master-apprentice approaches for agents, too.
LlamaIndex property graph index
OK, not officially a part of the gathering, but underscoring the theme was LlamaIndex’s awesome release of a Property Graph Index that same week.
Notes:
- Construct a knowledge graph according to a set of pre-defined or custom extractors.
- Query a knowledge graph with myriad retrievers that can be combined — keywords, vector search, text-to-cypher, and more.
- Include the text along with the entities/relationships during retrieval.
- Perform joint vector search/graph search.
Knowledge Graph Builder Show and Tell
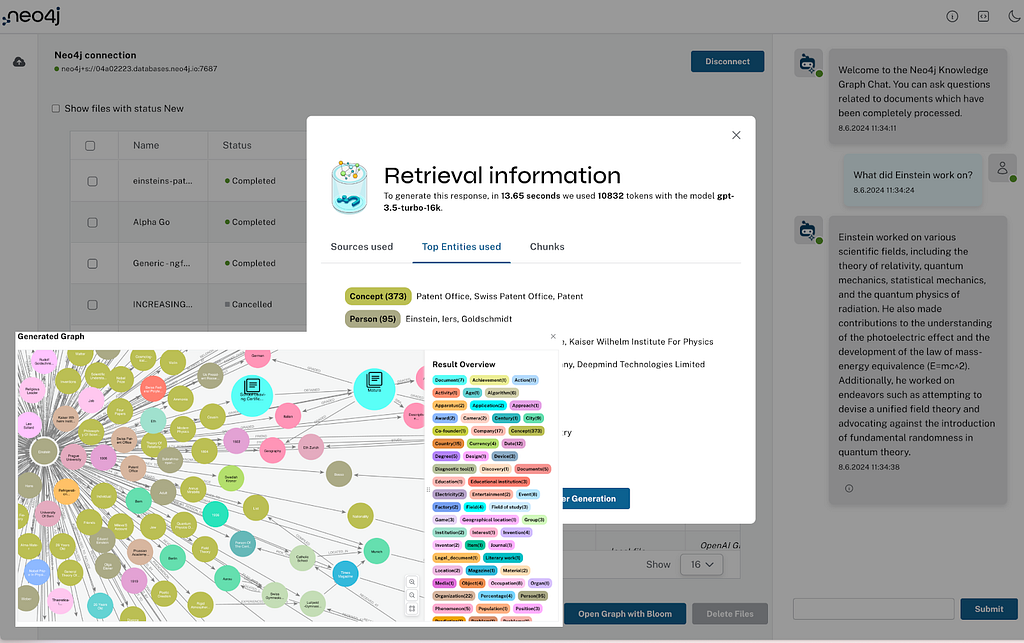
- Because there was interest, Michael Hunger showed his LLM Graph Builder, which is built on top of integrations with LangChain. It’s aimed at getting started without the blank-slate problem and showing what such a system would look like.
- It allows you to extract graphs stored in Neo4j from PDFs, Wikipedia pages, and YouTube transcripts, optionally providing a schema.
- Using a GraphRAG-based chatbot (vector + retrieval query) to inquire about the documents.
Wrap-up
As usual, when you are deeply thinking, questioning, and exploring topics with engaged experts, time flies.
We wrapped up with a feedback round. Everyone appreciated that The Gathering brought together a diverse group of experts to delve into the challenges and ideas for integrating graphs with LLMs. The participants were impressed by the technical depth and the variety of perspectives, which led to rich discussions about solving complex problems without having to explain basic concepts.
There was general agreement to continue the collaborations. We’ll find the right channel for ongoing communication and consider when and where to have the next GenAI Graph Gathering. Reach out to us if you’re interested.
We concluded the amazing day with an equally amazing dinner at Spruce where the conversations continued, and we learned more about each other’s background and interests.
Thank you to everyone who joined us for this memorable day!

A Tale of LLMs and Graphs — the Inaugural GenAI Graph Gathering was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



