Generative transformation from ER diagram to graph model using Google’s Gemini Pro

Field Engineer, Neo4j
10 min read
A multi-modal model use case.
In this tutorial, we’ll demonstrate how easy it is to use Google’s Gemini Pro to extract entities, relationships, and fields from an entity-relationship (ER) diagram, which are then transformed into assets of a property graph model stored in Neo4j.
This project’s source code (colab notebook) can be found here on GitHub.
What is the Gemini model
Google’s Gemini was declared to be their most advanced AI model yet. It was designed to be multimodal, and capable of understanding and generating across different types of information, including text, code, audio, image, and video. It promises state-of-the-art performance across numerous benchmarks and introduces next-generation multimodal reasoning abilities.
Unlike traditional models that typically specialize in one modality (e.g., text-only or image-only models), multi-modal generative models can process and generate content that combines several types of data, enabling a more comprehensive understanding and richer generation capabilities. One same
Gemini was optimized in three versions — Ultra, Pro, and Nano. Gemini 1.0 Pro Vision supports multimodal prompts, i.e., it is possible to include text, images, and video in prompt requests and get text or code responses. As per Google’s online documentation, Gemini implements visual understanding capabilities, which enable a broad range of use cases:
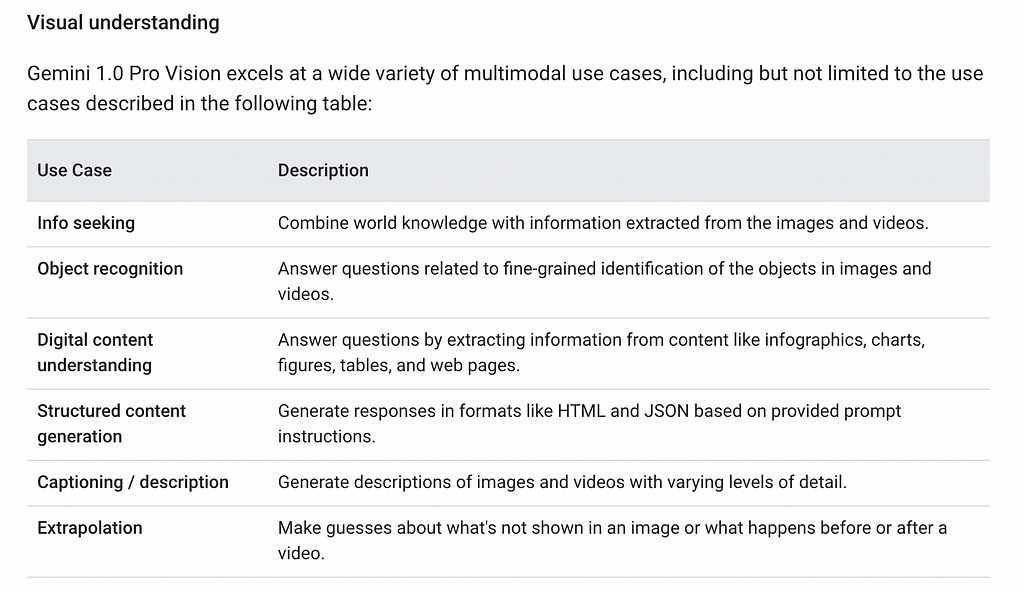
In this short tutorial, I will showcase steps to use Gemini Vision Pro 1.0 to extract entities, relationships, and fields from an ER diagram picture, and then transform them into assets of a property graph model stored in Neo4j.
Introducing Gemini: our largest and most capable AI model
What is Label Property Graph
A Label Property Graph (LPG) is a type of graph database model that uses nodes, relationships, and properties. Nodes and relationships in LPGs can have labels that define their types or roles within the graph. Properties are key-value pairs attached to nodes and relationships, allowing for the storage of additional information. This structure enables flexible and intuitive modeling of complex, interconnected data, making LPGs valuable for applications requiring rich data relationships, such as social networks, recommendation systems, and knowledge graphs.
Below is a very simple graph from Neo4j website:
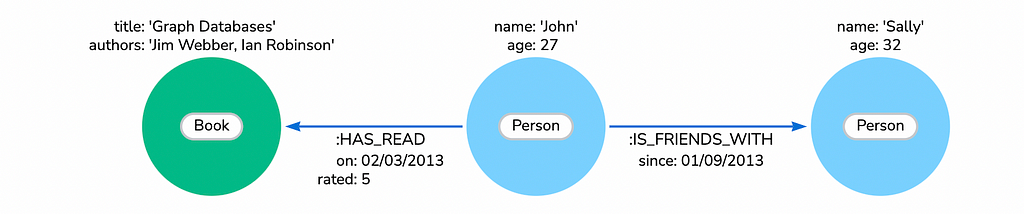
Here we can see:
- Nodes (circles) represent objects categorized by label (e.g., Book, Person, etc.).
- Nodes can have properties (name/value pairs).
- Relationships (arrows) connect nodes and represent actions.
- Relationships are directional and can have properties (name/value pairs).
Graph models excel in handling relationships, especially when connections between data points are as important as the data itself. This is crucial for applications like social networks, recommendation engines, fraud detection, knowledge graphs, and supply chains, where the depth and speed of relationship traversal can significantly impact performance. Graph databases offer flexibility, efficiency in querying connected data, and better scalability for certain types of queries and data structures, making them more suitable than relational databases in these contexts.
If you are interested in knowing more about how graph databases can be used in generative AI-related applications, feel free to check my other blog posts.
Prompt is all you need
Below is an ER diagram for a movie database:
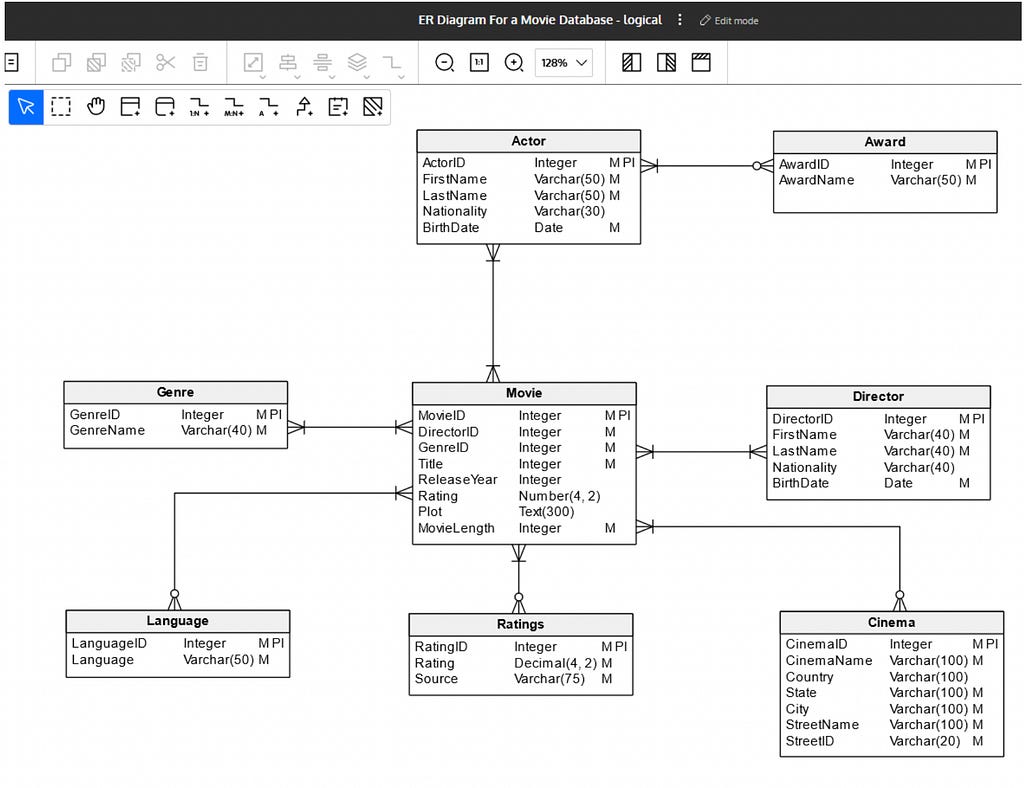
Using Gemini to extract entities, relationships, and fields from an ER diagram like this one is as simple as just three steps:
1 ) Prepare
2 ) Prompt
3 ) Generate
Let’s go through each of them in the Python Colab Notebook. The complete code can be found in my GitHub repository.
from vertexai.generative_models import (
GenerationConfig,
GenerativeModel,
Image,
Part,
)
# Prepare an instance of gemini pro vision model
multimodal_model = GenerativeModel("gemini-1.0-pro-vision")
For a multi-modal model, the prompt can consist of text, image and even video, as shown by the code snippets below:
image_er_url = "https://github.com/Joshua-Yu/graph-rag/raw/main/gemini-multimodal/resources/movie-er.jpg"
image_er = load_image_from_url(image_er_url)
prompt = "Document the entities and relationships in this ER diagram and structure your response in JSON format for entity, relationship and their fields."
contents = [prompt, image_er]
Then, what’s left is just to generate a response:
# Use a more deterministic configuration with a low temperature
generation_config = GenerationConfig(
temperature=0.1,
top_p=0.8,
top_k=40,
candidate_count=1,
max_output_tokens=2048,
)
responses = multimodal_model.generate_content(
contents,
generation_config=generation_config,
stream=True,
)
finalResponse = ""
print("n-------Response--------")
for response in responses:
# Because streaming mode is enabled, we need to collect all pieces of generated text
finalResponse += response.text
print(response.text)
The response contains recognized details of entities, relationships, and their fields as per the ER diagram:
-------Response--------
```json
{
"entities": [
{
"name": "Actor",
"fields": [
{
"name": "ActorID",
"type": "Integer",
"primary_key": true,
"not_null": true
},
},
... ... MORE ENTITIES TO FOLLOW ... ...
],
"relationships": [
{
"name": "Actor-Award",
"type": "many-to-many",
"source-entity": "Actor",
"source-field": "ActorID",
"target-entity": "Award",
"target-field": "AwardID"
},
... ... MORE RELATIONSHIPS TO FOLLOW ... ...
]
}
```
ER to graph schema mappings
To transform a relational model into a graph model, consider starting with these principles:
- tables to node labels
- rows to individual node instances
- foreign keys to relationships/edges connecting nodes
- attributes/fields becoming properties of nodes and edges.
This transformation leverages the graph database’s ability to represent complex relationships and hierarchies more naturally and efficiently than relational tables, facilitating faster and more intuitive queries for interconnected data. This approach enhances performance and scalability for applications requiring deep relationship traversal or real-time insights from connected data.
I recommend this article from Neo4j’s website for a more comprehensive explanation of the process.
Transition from relational to graph database – Getting Started
As a No-SQL native graph database, Neo4j implemented schema-lite storage, i.e., there is no need for schema definition for nodes or relationships. DBMS will handle types during the time data is stored. On the other side, Neo4j does provide certain constraints to ensure schema consistency and data quality.
The following code snippet will go through the entities in response and generate a CREATE CONSTRAINT statement for the primary key attribute (Uniqueness Constraint), as well as non-nullable attributes (Existence Constraint).
cypher_constraints = ""
cypher_load_nodes = ""
cypher_build_relationships = ""
# a.1 Iterate through entities and create UNIQUENESS and/or EXISTENCE constraints
for entity in responseJson.get("entities"):
entity_name = entity.get("name")
for field in entity.get("fields"):
field_name = field.get("name")
if field.get("primary-key") == "true":
cypher = f"CREATE CONSTRAINT {entity_name}_{field_name}_unique FOR (n:{entity_name}) REQUIRE n.{field_name} IS UNIQUE;n"
cypher_constraints += cypher
if field.get("not-null") == "true" and not field.get("primary-key") == "true": # primary-key must be unique
cypher = f"CREATE CONSTRAINT {entity_name}_{field_name}_notnull FOR (n:{entity_name}) REQUIRE author.{field_name} IS NOT NULL;n"
cypher_constraints += cypher
print(cypher_constraints)
The output is a collection of Cypher statements (the query language of Neo4j):
CREATE CONSTRAINT Actor_ActorID_unique FOR (n:Actor) REQUIRE n.ActorID IS UNIQUE;
CREATE CONSTRAINT Actor_FirstName_notnull FOR (n:Actor) REQUIRE author.FirstName IS NOT NULL;
CREATE CONSTRAINT Actor_LastName_notnull FOR (n:Actor) REQUIRE author.LastName IS NOT NULL;
... ... ... ...
Data ingestion
Assume we have CSV files storing extracted records for each table, using the generated response, it wouldn’t be too hard to generate data ingestion scripts, too.
Let’s assume the exported records are stored in a CSV file, with column headers from actual attribute names. The file name will be passed as a parameter at runtime by a job orchestrator.
Ingestion of entity records
The following Python code will generate a LOAD CSV statement for each entity:
for entity in responseJson.get("entities"):
entity_name = entity.get("name")
cypher_load_nodes = f"// ----------- LOAD CSV for nodes of {entity_name} -----------n"
cypher_load_nodes += f":autonWITH $filenamenLOAD CSV FROM $filename AS linenCALL " + "{" + f"nMERGE (n:{entity_name} "
set_statement = "SET "
for field in entity.get("fields"):
field_name = field.get("name")
if field.get("primary-key") == "true":
cypher_load_nodes += "{" + f"{field_name}:line.{field_name}" + "}" + ")n"
else:
set_statement = set_statement + f"n.{field_name} = line.{field_name},"
cypher_load_nodes += set_statement[:len(set_statement)-1]
cypher_load_nodes += "n} IN TRANSACTIONS 2000;"
print(cypher_load_nodes)
Sample output:
// ----------- LOAD CSV for nodes of Actor -----------
:auto
WITH $filename
LOAD CSV FROM $filename AS line
CALL {
MERGE (n:Actor {ActorID:line.ActorID})
SET n.FirstName = line.FirstName,n.LastName = line.LastName,n.Nationality = line.Nationality,n.BirthDate = line.BirthDate
} IN TRANSACTIONS 2000;
Something to highlight here:
a. LOAD CSV goes through each record/line in the CSV file and creates nodes with given labels and properties.
b. MERGE is equivalent to UPSERT, of which the primary key/property is used to check the existence of a node. This is guaranteed by the Uniqueness Constraint defined above.
c. Every 2000 records, the updates will be commited as one transaction to the database. This will improve the performance and reliability of bulk data ingestion.
Ingestion of relationship records
In a strictly compliant 3NF database, many-to-many relationships are likely stored in so-called relationship-tables or join-tables. Here, let’s assume records of those tables are exported into CSV files with column headers, too.
The following process can read and generate LOAD CSV statements to ingestion relationships:
# a.3 Iterate Relationships to create relationship between nodes
#
# Naming conventions:
# - for source_node:SourceLabel -> target_node:TargetLabel, the name of relationship is HAS_<TargetLabel> in big cases
for relationship in responseJson.get("relationships"):
source_entity = relationship.get("source-entity")
source_field = relationship.get("source-field")
target_entity = relationship.get("target-entity")
target_field = relationship.get("target-field")
relation_name = relationship.get("name")
cypher_create_relationships = f"// ----------- LOAD CSV for relationships of {relation_name} -----------n"
cypher_create_relationships += f":autonWITH $filenamenLOAD CSV FROM $filename AS linenCALL " + "{n"
cypher_create_relationships += f"MATCH (e1:{source_entity}" + "{" + f"{source_field}:line.{source_field}" + "})n"
cypher_create_relationships += f"MATCH (e2:{target_entity}" + "{" + f"{target_field}:line.{target_field}" + "})n"
cypher_create_relationships += f"MERGE (e1) -[:HAS_{target_entity.upper()}]-> (e2)n" + "} IN TRANSACTIONS 2000;n"
print(cypher_create_relationships)
Sample output:
// ----------- LOAD CSV for relationships of Actor-Award -----------
:auto
WITH $filename
LOAD CSV FROM $filename AS line
CALL {
MATCH (e1:Actor{ActorID:line.ActorID})
MATCH (e2:Award{AwardID:line.AwardID})
MERGE (e1) -[:HAS_AWARD]-> (e2)
} IN TRANSACTIONS 2000;
In Cypher, a relationship is always directional at creation, using -> or <- to indicate its direction. Here, the direction is always from the entity having a foreign key pointing to the entity with the primary key.
Conclusion
Just a few days before this post was published, Google released its newest Gemini 1.5 models, which have many more exciting features, including the support of up to 1 million tokens!
The future of generative AI has just been revealed by more sophisticated AI systems capable of processing and generating information across various data types seamlessly. This evolution will likely lead to models that better understand and interact with the world in a human-like manner, enabling breakthroughs in AI-human interfaces, creative content generation, and complex problem-solving across domains.
Generative data transformation is just one of the many use cases that are enabled by the multi-modal capabilities. Look forward to seeing more soon!
Gemini 1.5 technical paper: link.
Generative Transformation from ER Diagram to Graph Model Using Google’s Gemini Pro was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



