Git commit history – Discover AuraDB Free: week 44

Head of Product Innovation & Developer Strategy, Neo4j
10 min read

Let’s explore the output of git log as a graph in Neo4j AuraDB Free.
This time Alex, couldn’t make it, hope he gets better soon.
Some interesting things that happened since last weekend
- Went to watch Dungeons and Dragons: Honor among Thieves with the kids (was really good)
- Played a lot with GPT-4
- Missed the asteroid DZ2 2023, due to the cloudy sky 🙁
- Been running Arc browser, which is really neat Invite here in the show-notes
- Went to a local whisky festival which was great for tasting rare spirits
Between everything I saw the TIL post by Simon Willison about his GPT-4 coding exercise to turn git logs into JSON output.
He uses the swiss army knife of JSON processing jq, which is awesome.
His post inspired me to today’s session on looking at git commit history as a graph.
If you rather want to see the recording, check it out here:
Data source and preparation
We’re using Neo4j’s open-source repository here for our experiment: https://github.com/neo4j/neo4j
Clone the repository (I limited it to the 5.6 branch) and follow along.
Simon did two interesting things
- Using git log –pretty with NULL-bytes as separators (instead of commas or tabs)
- Using jq to parse split the raw string by those NULL bytes and output JSON for the fields
git log --date=iso --pretty=format:'%H%x00%an%x00%ad%x00%s%x00' | head -2 |
jq -R -s '[split("n")[:-1] | map(split("u0000")) | .[] | {
"commit": .[0],
"author": .[1],
"date": .[2],
"message": .[3]
}]'
The output is:
[
{
"commit": "5ad4387ed521f169a737f9836402dbac8759a9fc",
"author": "Johannes Donath",
"date": "2023-03-08 16:17:12 +0100",
"message": "Corrected an issue in which the number of writable bytes is incorrectly calculated. ()"
},
{
"commit": "c53e91519eca145c6879d5c9be9a421fdd223338",
"author": "Tobias Johansson",
"date": "2023-03-07 13:34:12 +0100",
"message": "Do polling of the fabric transaction lock in terminate"
}
]
The placeholders in the pretty-print string are a bit ominous but the man page and the cheat-sheet here help a lot.
I wanted to add the parent commit via %P to see the git commit history chain. Also tried to get one of the files of the commit in but we’ll leave that for another time.
The other change that we need to do is to turn the data into a CSV, not a JSON file. Fortunately, jq also supports CSV as an output so we can select our 5 fields and tell it to send it through the @csv processing step.
echo 'commit,parent,author,date,message' > ~/Downloads/neo4j-git.csv
git log --date=iso --pretty=format:'%H%x00%P%x00%an%x00%ad%x00%s%x00' |
jq -r -R -s 'split("n")[:-1] | map(split("u0000")) | .[] | [
.[0],
.[1],
.[2],
.[3],
.[4]
] | @csv' >> ~/Downloads/neo4j-git.csv
We can check the resulting CSV file with the xsv tool and see that it has the 76k commits and the right fields, it’s about 14MB of data.
xsv count ~/Downloads/neo4j-git.csv
76567
xsv stats ~/Downloads/neo4j-git.csv
field,type,sum,min,max,min_length,max_length,mean,stddev
commit,Unicode,,0000257bb06e29e15c11b6bc5ad4f8253deed4a4,ffff9ee399d15bd834e4aeb4719a02e5e39308d5,40,40,,
parent,Unicode,,0000257bb06e29e15c11b6bc5ad4f8253deed4a4,ffff9ee399d15bd834e4aeb4719a02e5e39308d5,0,81,,
author,Unicode,,@fbiville,wujek srujek,2,30,,
date,Unicode,,2007-05-24 01:34:45 +0000,2023-03-08 16:17:12 +0100,25,25,,
message,Unicode,, - BeansAPITransaction handles multiple calls to tx.finish(),zoo_keeper_servers example changed to something useful (the default ZK port),1,3217,,
ls -lh ~/Downloads/neo4j-git.csv
14M 27 Mar 10:17 /Users/mh/Downloads/neo4j-git.csv
Ok, now we have everything to turn those commits into a graph.
Are you ready?
Let’s first spin up a Neo4j AuraDB database and get the data imported.
Create a Neo4j AuraDB Free instance
Go to https://dev.neo4j.com/neo4j-aura to register or log into the service (you might need to verify your email address).
After clicking Create Database you can create a new Neo4j AuraDB Free instance.
Choose the “Empty Instance” option as we want to import our data ourselves.
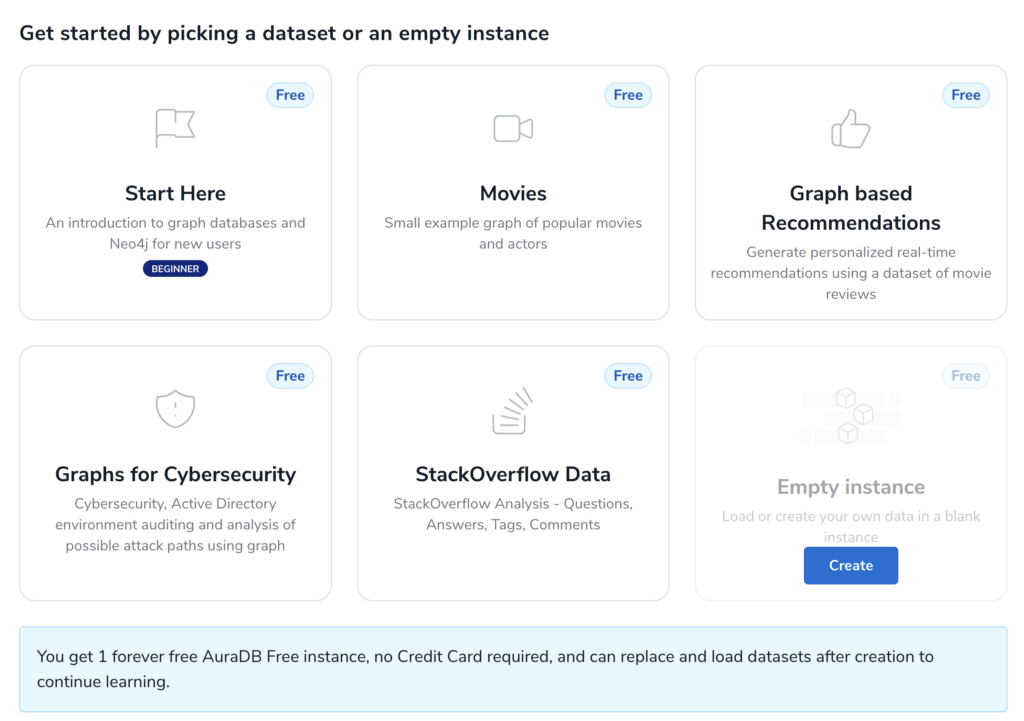
On the Credentials popup, make sure to save the password somewhere safe, best is to download the credentials file, which you can also use for your app development.
The default username is always neo4j.
Then wait 2-3 minutes for your instance to be created.
Afterward, you can connect via the “Open” Button with Workspace (you’ll need the password), which offers the “Import” (Data Importer), “Explore” (Neo4j Bloom), and “Query” (Neo4j Browser) tabs to work with your data.
On the database tile, you can also find the connection URL: neo4j+s://xxx.databases.neo4j.io (it is also contained in your credentials env file).
If you want to see examples of programmatically connecting to the database go to the “Connect” tab of your instance and pick the language of your choice
After opening Neo4j Workspace via the “Open” button, and logging in with the downloaded credentials, we can go to the “Import” tab and get started.
Data modeling
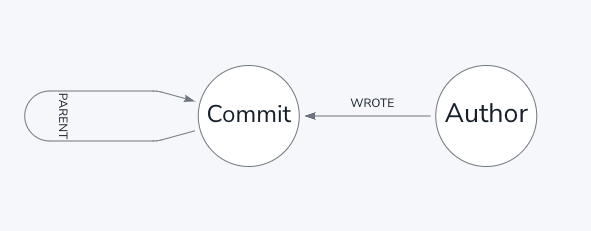
The data model is pretty straightforward, we just have Commit and Author nodes connected by a WROTE relationship.
The commits are also pointing to their parent commit via a PARENT relationship.
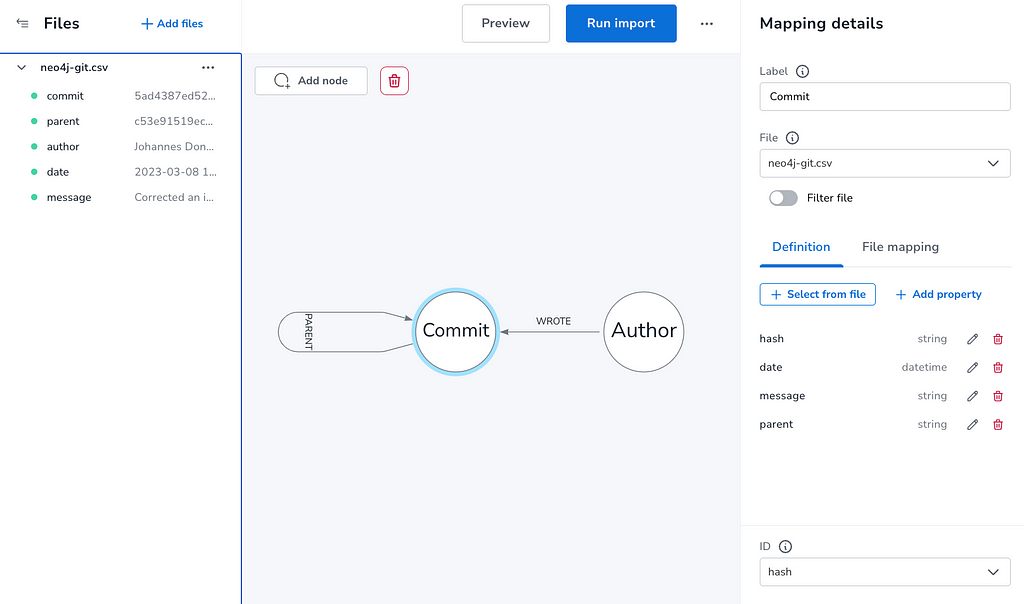
Now we can add our CSV file and map the attributes and select our id-fields.
- Commit (hash, date, parent, subject)
- Author (author)
With the data mapped we can “Preview” our import and inspect nodes and relationship attributes and structure to see if we messed anything up.

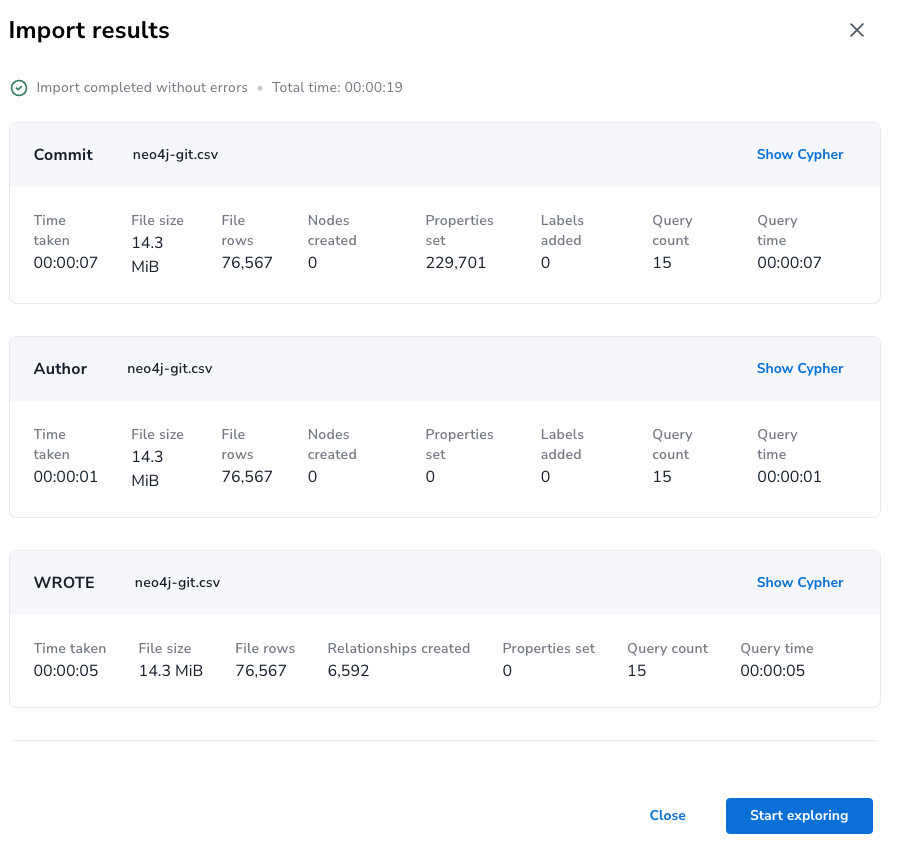
As we’re good we can click “Import” and, after a few seconds, the results are presented. There you can also inspect the Cypher statements used to create the data which you can use in your own code or scripts.
The image below is from a 2nd run, so the data is already in the graph.
Explore
Now with “Start Exploring” we head over to the “Explore” tab and see data in the graph.
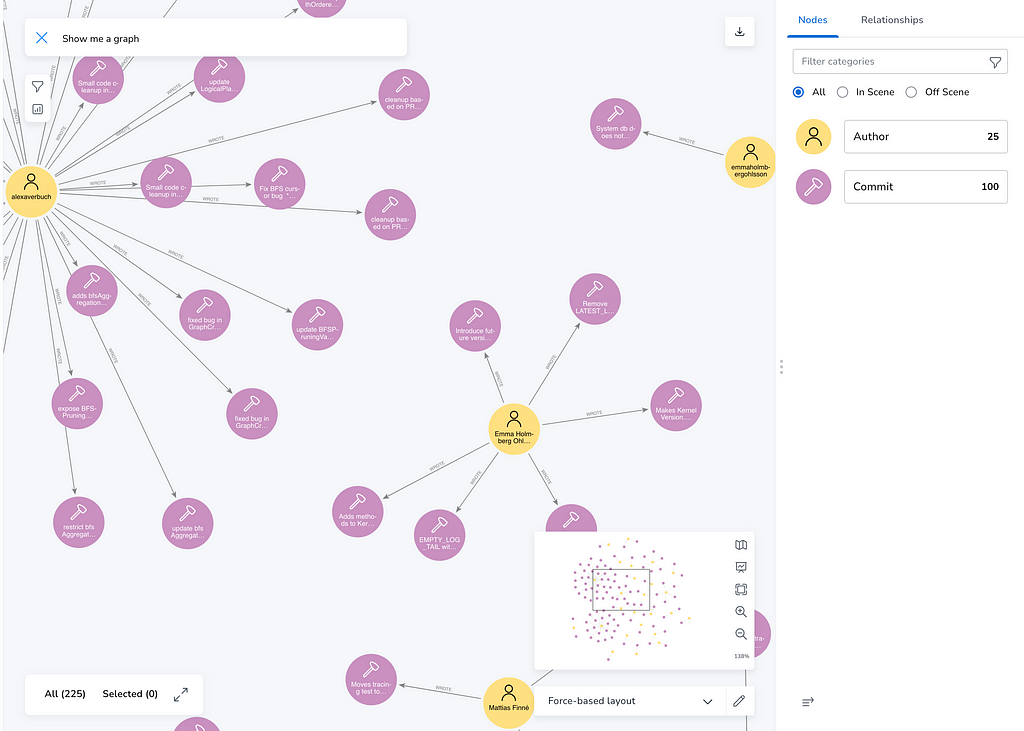
There we can also style our nodes and for instance determine the shortest paths between commits (select two nodes and right click for the context menu).
Now let’s get our hands dirty and write some Cypher statements.
Query & evolve
Opening the left sidebar shows us the labels and relationship-types in the graph, we can click on any of them to see a subset of our data.
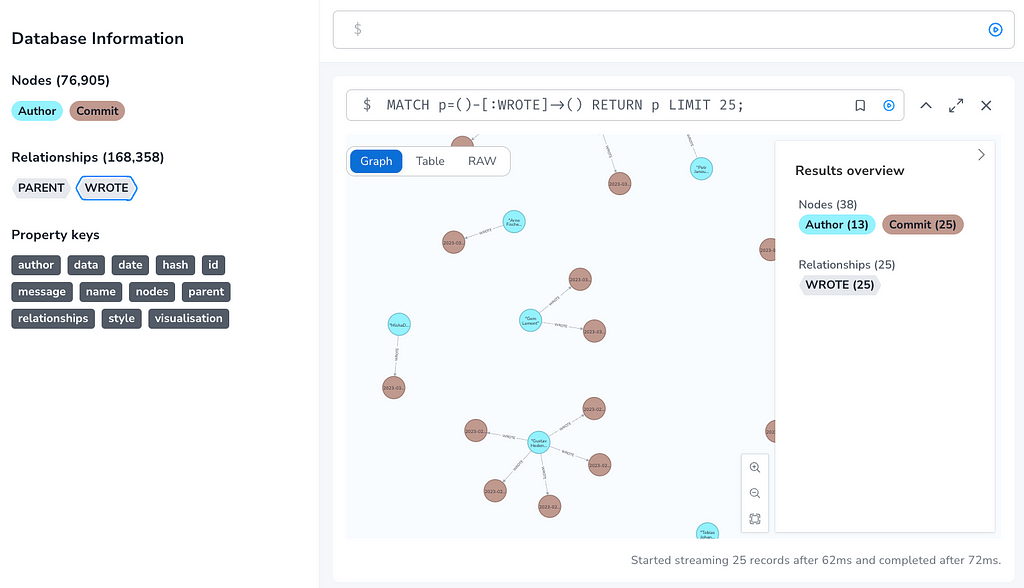
Now we can start to explore a bit,
First looking at the total number of commits and authors:
MATCH (:Commit) RETURN count(*)
// 76k
MATCH (:Author) RETURN count(*)
// 338
Contributor activity
Let’s find the most active authors, we can find out their outgoing relationships.
MATCH (a:Author)
WITH a, count { (a)-[:WROTE]->() } as commits
ORDER BY commits DESC LIMIT 10
RETURN a.author, commits
Which gives us these folks:
a.author commits
Mattias Persson 6592
Anders Nawroth 4106
Pontus Melke 4030
MishaDemianenko 3989
Andres Taylor 3640
Chris Vest 2983
Jacob Hansson 2521
Anton Persson 2212
Mattias Finné 2148
Davide Grohmann 1987
The usual suspects 🙂
Oh, Mattias has been with us for 15 years but got married in between, so he shows up with two different names.
Let’s fix that and move the 6592 relationships from his old alter-ego to the new one:
MATCH (new:Author { author: "Mattias Finné"})
MATCH (old:Author { author: "Mattias Persson"})
MATCH (old)-[rel:WROTE]->(c:Commit)
CREATE (new)-[:WROTE]->(c)
DELETE rel
RETURN count(*);
So that should fix the results:
a.author commits
Mattias Finné 8740
Anders Nawroth 4106
Pontus Melke 4030
MishaDemianenko 3989
Andres Taylor 3640
Chris Vest 2983
Jacob Hansson 2521
Anton Persson 2212
Davide Grohmann 1987
Satia Herfert 1896
If we wanted to limit the people by commit-date, so we see who has been more active recently, we can do that too:
MATCH (a:Author)
WITH a, count { (a)-[:WROTE]->(c:Commit) WHERE c.date > datetime("2019-01-01T00:00:00")} as commits
ORDER BY commits DESC LIMIT 10
RETURN a.author, commits
Now we have a different set of people with fewer total contributions:
a.author commits
MishaDemianenko 1892
Pontus Melke 1570
Mattias Finné 1284
Satia Herfert 1126
Anton Persson 920
Chris Vest 746
Louise Söderström 578
Tobias Johansson 463
Therese Magnusson 439
Georgiy Kargapolov 415
Fixing parents
Another thing we need to fix is that some commit multiple parents not just one so that their parent-hash was not found in the database to connect them.
We have roughly 15k commits of that kind. Here is what the property looks like.
parent: "e5697a0900ff849f92d0ae3c88bd8e31e3163024 d26c6ab67c34a5f91cc6cfadfc75ca4b1def3bef"
We can fix it by:
- Finding these commits
- Splitting the parent field by space
- Turning that list of hashes into rows
- Find the parent commit with the hash
- Create the relationships
Or in Cypher:
// find commits without PARENT relationship but with multiple parent hash values
MATCH (c:Commit)
WHERE NOT exists { (c)-[:PARENT]->() }
AND c.parent contains ' '
// split by space into list of hashes
WITH c, split(c.parent,' ') as parents
// turn list into rows
UNWIND parents as parent
// find parent commit
MATCH (p:Commit {hash:parent})
/// create relationship
MERGE (c)-[:PARENT]->(p)
RETURN count(*);
Now our graph is better connected, and we can run a few long path queries:
MATCH path = (c:Commit)-[:PARENT*100]->(p:Commit)
RETURN path LIMIT 1
Which gives us this beautiful long, flowery chain of commits
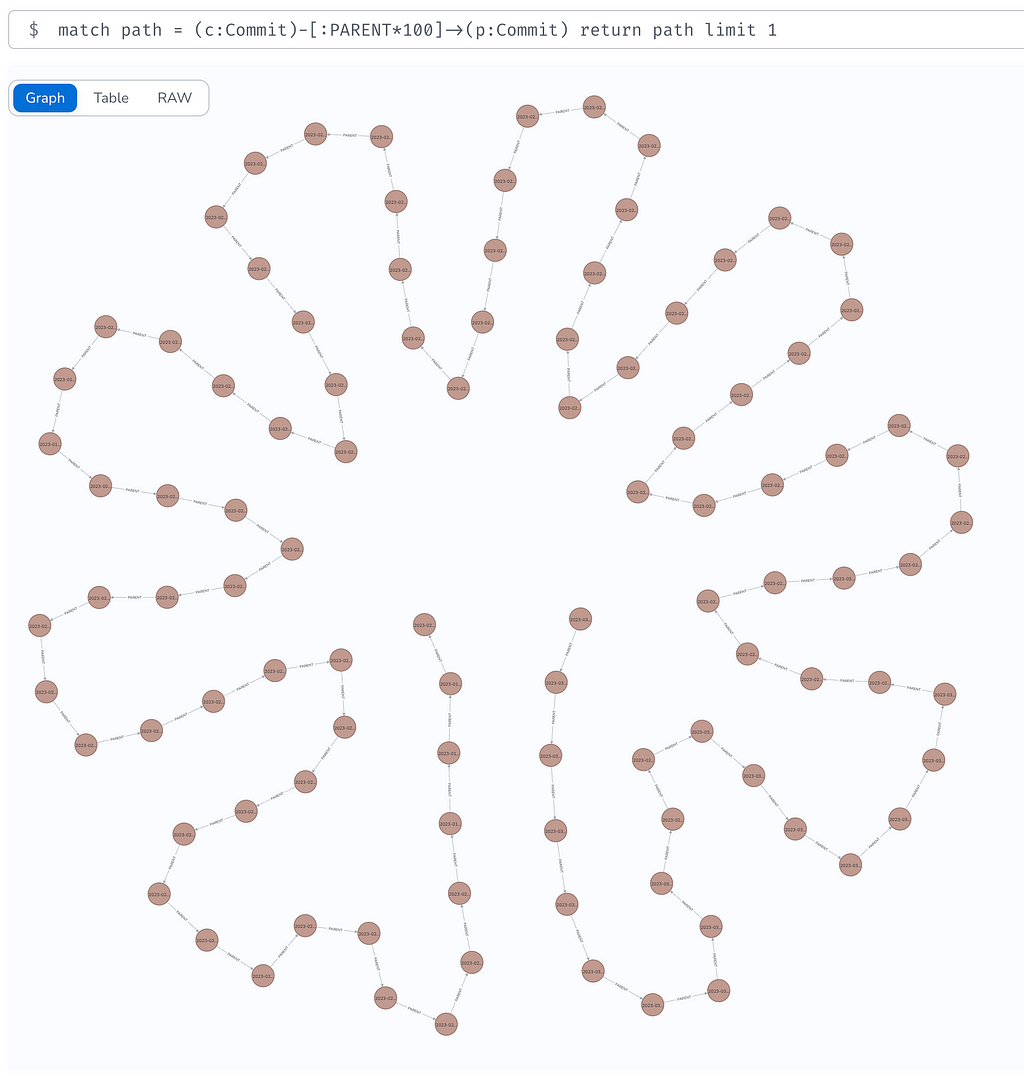
We can also look at “root” commits and see which ones have the most children.
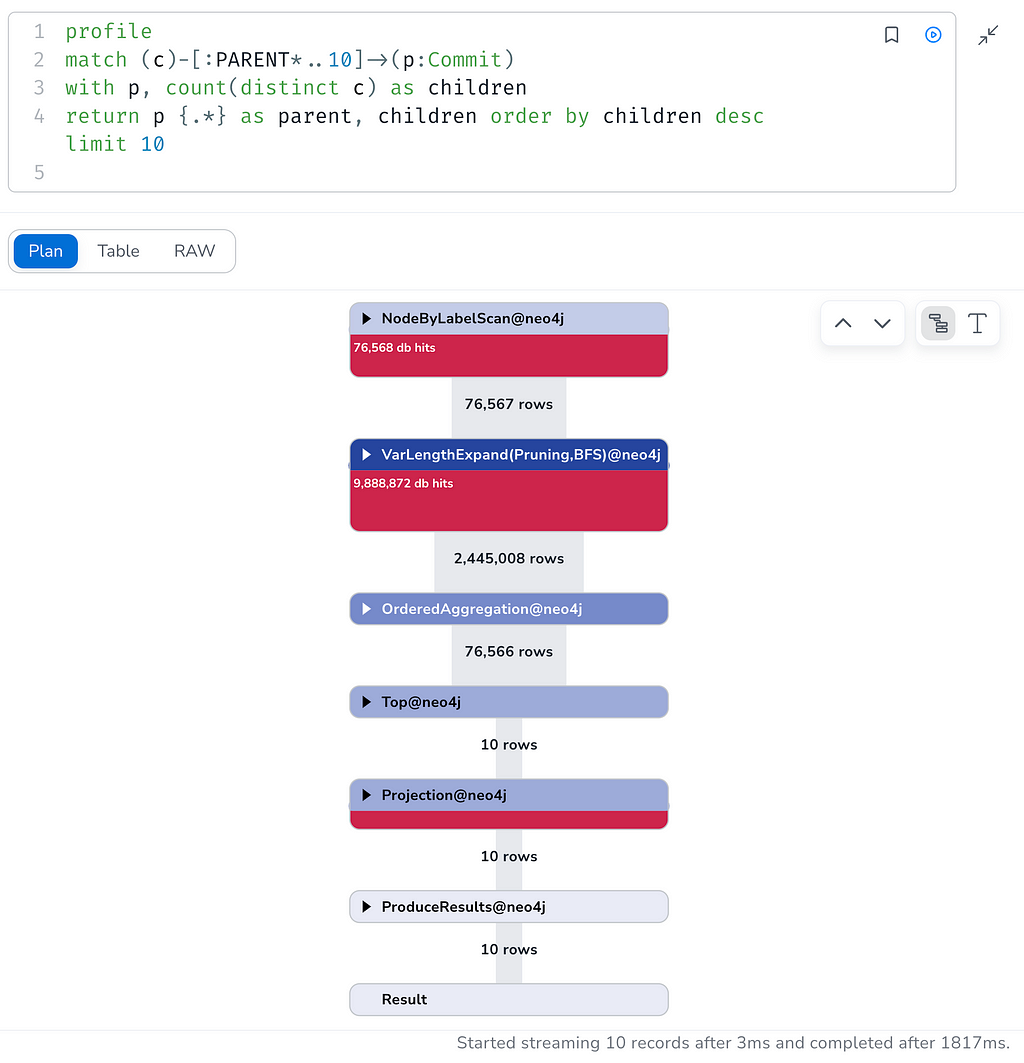
With PROFILE we can sneak under the hood and see how the query planner optimizes this query, it completes in about 2 seconds checking 10-hop paths for all 76k commits.
profile
match (c)-[:PARENT*..10]->(p:Commit)
with p, count(distinct c) as children
return p {.*} as parent, children order by children desc limit 10
Some of them have more than 600 children even only up to level 10!
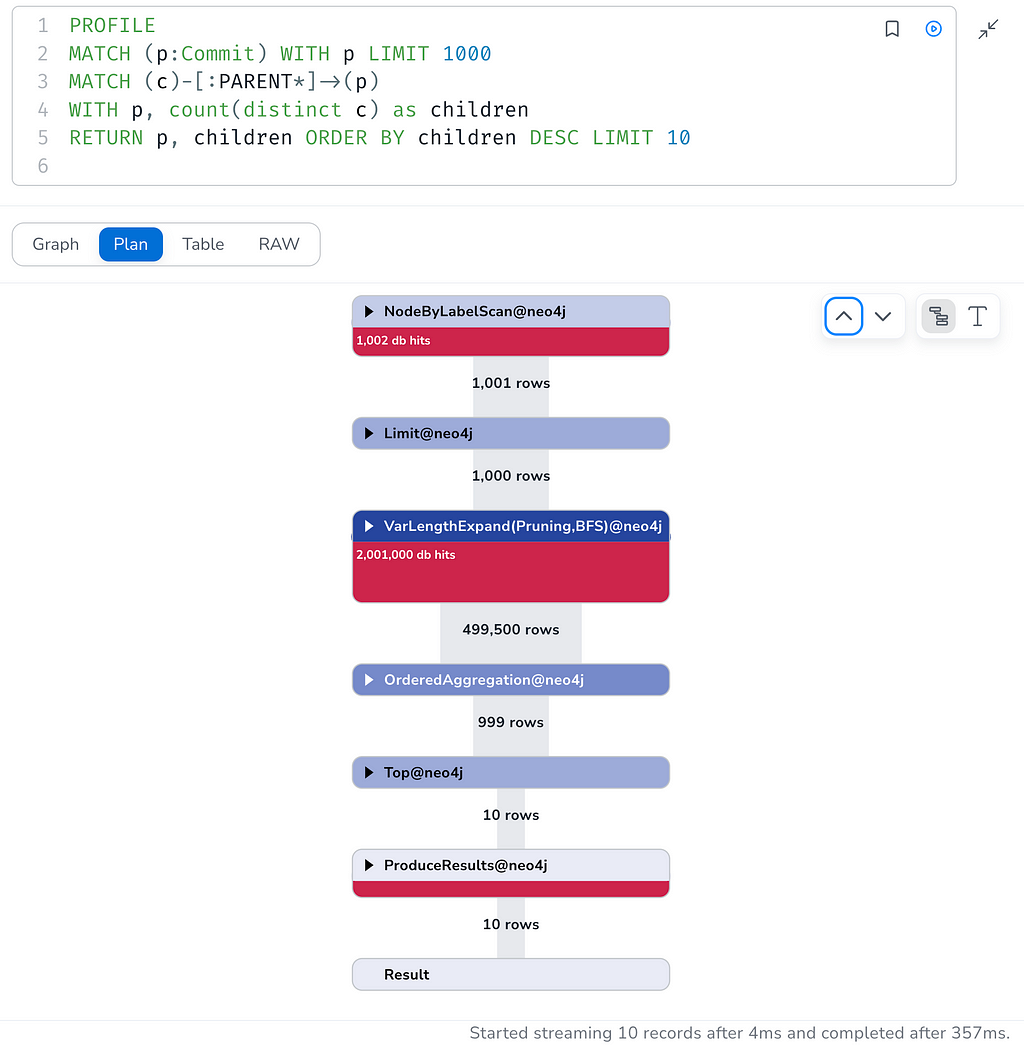
We can do the same without an upper limit but for a subset of commits:
PROFILE
MATCH (p:Commit) WITH p LIMIT 1000
MATCH (c)-[:PARENT*]->(p)
WITH p, count(distinct c) as children
RETURN p, children ORDER BY children DESC LIMIT 10
And with that, we were out of time and had covered a lot of ground.
If you want to see videos, write-ups, and data for past livestreams check out our overview page:
Discovering AuraDB Free with Fun Datasets
Or our repository: https://github.com/neo4j-examples/discoveraurafree
Hope this was as much for you as it was for me,
Happy Graphing!
Git Commit History — Discover AuraDB: Week 44 was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles



Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher


