


Enriching Vector Search With Graph Traversal Using the GraphRAG Python Package

Senior Software Engineer, AI
6 min read

In our last blog post on the Neo4j GraphRAG Python package, we covered how you can use the package to build a basic GraphRAG application. In this and upcoming posts, we’ll dive deeper into the package’s capabilities and show how to further customize and improve your applications by using the other included retrievers. Here, we’ll demonstrate how to use Cypher queries to extend the vector-search approach used in the previous blog by incorporating graph traversal as an additional step.
Setup
We’ll use the same pre-configured Neo4j demo database we used in the previous blog. This database simulates a movie recommendations knowledge graph. (For more details on the database, read the Setup section of the previous blog.)
You can access the database through a browser at https://demo.neo4jlabs.com:7473/browser/ using “recommendations” as both the username and password. Use the following snippet to connect to the database in your application:
from neo4j import GraphDatabase
# Demo database credentials
URI = "neo4j+s://demo.neo4jlabs.com"
AUTH = ("recommendations", "recommendations")
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)Additionally, make sure to export your OpenAI key:
import os
os.environ["OPENAI_API_KEY"] = "sk-…"Other Nodes in the Graph
Run the following command in the Neo4j web UI to visualize the movie “Tom and Huck” and its immediate relationships to other nodes:
MATCH (m:Movie {title: 'Tom and Huck'})-[r]-(n) RETURN *;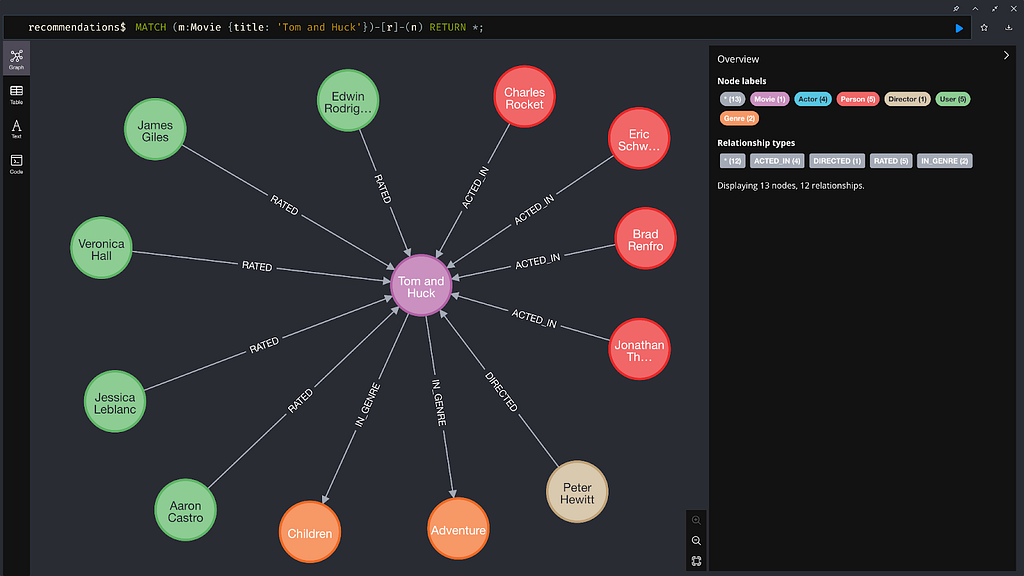
Notice we can now see the genres of the movie, which actors starred in it, and other useful information not included in the Movie node itself.
In the previous blog, we used movie plot embeddings and a vector retriever to retrieve the Movie nodes most similar to a user’s query. These Movie nodes served as the context for an LLM to generate an answer to the query. However, in this setup, only the information contained in the Movie nodes themselves could be used as the context, with the additional information contained in the other nodes connected to the unused Movie nodes. As a result, if users asked questions about the genre of a movie or the actors that starred in it, for example, the LLM wouldn’t be given the appropriate context to answer them.
Retrieval
Fortunately, we can use the VectorCypherRetriever class to retrieve this additional information. This retriever first retrieves an initial series of nodes from the knowledge graph using vector search, then uses a Cypher query to traverse the graph from each of these initial nodes and gather the additional information from the nodes connected to them.
To use this retriever, we first need to write the Cypher query to specify exactly what additional information to fetch along with the node retrieved through vector search. For example, to retrieve actor information along with the Movie nodes, we can use the following query:
retrieval_query = """
MATCH
(actor:Actor)-[:ACTED_IN]->(node)
RETURN
node.title AS movie_title,
node.plot AS movie_plot,
collect(actor.name) AS actors;
"""The node variable in this query is a reference to the nodes retrieved through the initial vector search step, which here are Movie nodes. This query finds all of the actors who have acted in each of the movies and returns their names along with the title and plot of the movie.
We then pass this query to the VectorCypherRetrieverwith the same information we passed to the VectorRetriever in the previous blog, such as the name of the vector index and an embedded:
from neo4j import GraphDatabase
from neo4j-graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j-graphrag.retrievers import VectorCypherRetriever
driver = GraphDatabase.driver(URI, auth=AUTH)
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
vc_retriever = VectorCypherRetriever(
driver,
index_name="moviePlotsEmbedding",
embedder=embedder,
retrieval_query=retrieval_query,
)Again, we use the text-embedding-ada-002model as the movie plot embeddings in the demo database that were originally generated using it.
Now we can use our retriever to search for information about movies in our database as well as the actors that starred in them:
query_text = "Who were the actors in the movie about the magic jungle board game?"
retriever_result = retriever.search(query_text=query_text, top_k=3)
items=[
RetrieverResultItem(content="<Record
movie_title='Jumanji'
movie_plot='When two kids find and play a magical board game, they release a man trapped for decades in it and a host of dangers that can only be stopped by finishing the game.'
actors=['Robin Williams', 'Bradley Pierce', 'Kirsten Dunst', 'Jonathan Hyde']>",
metadata=None),
RetrieverResultItem(content="<Record
movie_title='Welcome to the Jungle'
movie_plot='A company retreat on a tropical island goes terribly awry.'
actors=['Jean-Claude Van Damme', 'Adam Brody', 'Rob Huebel', 'Kristen Schaal']>",
metadata=None),
RetrieverResultItem(content='<Record
movie_title='Last Mimzy, The'
movie_plot='Two siblings begin to develop special talents after they find a mysterious box of toys. Soon the kids, their parents, and even their teacher are drawn into a strange new world and find a task ahead of them that is far more important than any of them could imagine!'
actors=['Joely Richardson', 'Rhiannon Leigh Wryn', 'Timothy Hutton', "Chris O'Neil"]>',
metadata=None)
]
metadata={'__retriever': 'VectorCypherRetriever'}Notice that we have retrieved the actors who acted in each movie along with its title and plot. Using the VectorRetriever, it would have been possible to retrieve the title and plot and not the actors, as these were stored in the Actor nodes attached to each Movie node.
GraphRAG
To build a full GraphRAG pipeline, all we need to do is replace the VectorRetriever used in the previous blog with our VectorCypherRetriever:
from neo4j-graphrag.llm import OpenAILLM
from neo4j-graphrag.generation import GraphRAG
# LLM
# Note: the OPENAI_API_KEY must be in the env vars
llm = OpenAILLM(model_name="gpt-4o", model_params={"temperature": 0})
# Initialize the RAG pipeline
rag = GraphRAG(retriever=vc_retriever, llm=llm)
# Query the graph
query_text = "Who were the actors in the movie about the magic jungle board game?"
response = rag.search(query=query_text, retriever_config={"top_k": 3})
print(response.answer)This returns the following response:
The actors in the movie "Jumanji," which is about a magical board game, are Robin Williams, Bradley Pierce, Kirsten Dunst, and Jonathan Hyde.Summary
In this blog, we demonstrated how the VectorCypherRetriever class from the GraphRAG Python package can be used to build a simple GraphRAG application. We showed how this powerful class incorporates a graph-traversal step in addition to an initial vector retrieval step to fetch information from a graph that can’t be fetched through vector retrieval alone. We then showed how this allows an LLM to answer certain questions about our movie database that it would not have been able to answer using the VectorRetriever class.
We invite you to use the neo4j-graphrag-python package in your projects and share your insights via comments or on our GraphRAG Discord channel.
The package code is open source, and you can find it on GitHub. Feel free to open issues there.
Read Next: Hybrid Retrieval for GraphRAG Applications Using the Neo4j GraphRAG Python package
Enriching Vector Search With Graph Traversal Using the GraphRAG Python Package was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Enhancing Hybrid Retrieval With Graph Traversal Using the GraphRAG Python Package
