GraphRAG field guide: Navigating the world of advanced RAG patterns

Data Scientist & Graph Database Specialist
24 min read

Have you ever stumbled upon the term GraphRAG while diving into the world of Retrieval Augmented Generation (RAG) systems? If so, you’re not alone. This term is making waves, but its meaning can be elusive. Sometimes, it’s a specific retrieval method; other times, it’s an entire software suite, like Microsoft’s GraphRAG “data pipeline and transformation suite.” With such varied uses, it’s no wonder even the most dedicated followers of RAG discussions can feel a bit lost.
So, what exactly is GraphRAG? For us, it’s a set of RAG patterns that leverage a graph structure for retrieval. Each pattern demands a unique data structure, or graph pattern, to function effectively. Intrigued? In this post, we’ll dive into the GraphRAG pattern details, breaking down each pattern’s attributes and strategies.
If you’re looking for an introduction to RAG, check out What Is Retrieval-Augmented Generation (RAG)? or watch recordings from the NODES conference on Nov. 7. This 24-hour free online event features speakers from around the world presenting on knowledge graphs and AI.
Each of our presented patterns is also linked directly to its GraphRAG Pattern Catalog entry. This is an open source initiative to stay up to date on the latest pattern evolution. We just started collecting patterns and are definitely still missing a lot of them. Please help us build a comprehensive catalog for GraphRAG patterns and join the discussion on the GraphRAG Discord channel.
To give you a clearer picture, the patterns explained in this post include:
Basic GraphRAG patterns:
- Basic Retriever (in GraphRAG Pattern Catalog)
- Parent-Child Retriever (catalog)
- Hypothetical Question Retriever (catalog)
Intermediate GraphRAG patterns:
Advanced GraphRAG patterns:
Let’s get started with some background information.
Thematic classification
There are three RAG paradigms: naive RAG, advanced RAG, and modular RAG (Gao et al.):
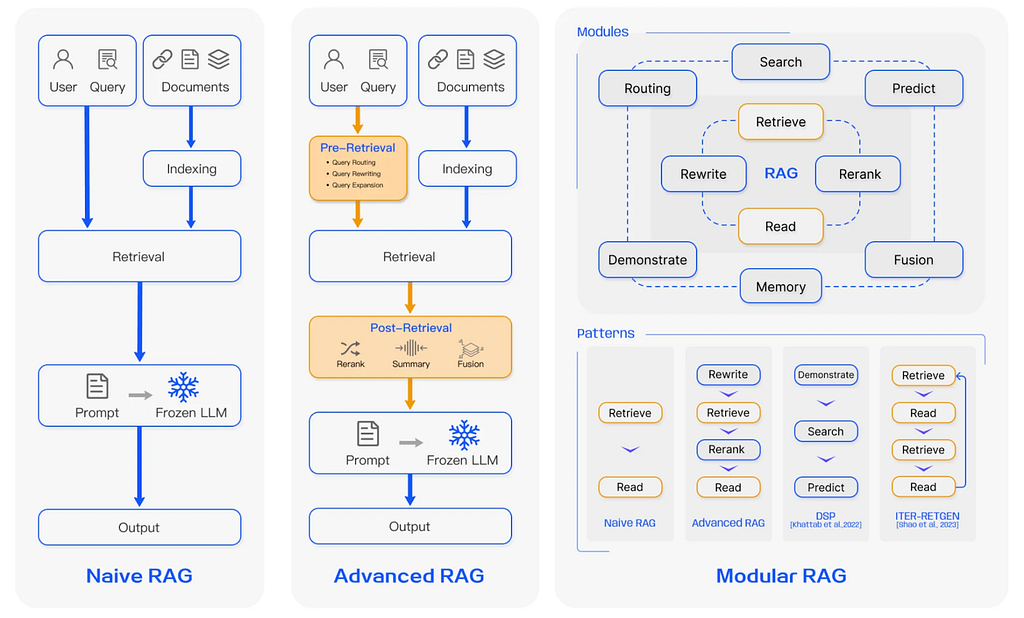
In an advanced RAG paradigm, pre-retrieval and post-retrieval phases are added to the naive RAG paradigm. A modular RAG system contains more complex patterns, which require orchestration and routing of the user query.
The phases of an advanced RAG system:
- Pre-retrieval — Query rewriting, query entity extraction, query expansion, etc.
- Retrieval of relevant context
- Post-retrieval: Reranking, pruning, etc.
- Answer generation
Here, we want to focus on the retrieval phase and conduct a survey of the most-often referenced GraphRAG retrieval patterns and their required graph patterns. Please note that the patterns here are not an exhaustive list.
Essentials of GraphRAG
Pair a knowledge graph with RAG for accurate, explainable GenAI. Get the authoritative guide from Manning.
Why graphs?
When we dive into retrieval patterns, we notice how the most advanced techniques rely on the connections within the data. Whether it’s metadata filtering, like searching for articles by a specific author or on a particular topic, or parent-child retrievers, which navigate back to the parent of a text chunk to provide breadth to the LLM for context-enriched answers, these methods leverage the relationships between the data to be retrieved.
Typically, these implementations rely heavily on client-side data structures and extensive Python code. However, in a graph database, establishing real relationships and querying them with simple patterns is more efficient.
If you’re looking to implement the retrievers discussed here using LangChain, you’d turn to its Neo4j Vector implementation. We won’t cover setting up your Python project for Neo4j-based retrievers here, as that’s well-documented elsewhere (e.g., Neo4j GraphAcademy: Build a Neo4j-backed Chatbot using Python).
Instead, we’ll focus on the intriguing part: using the retrieval_query argument to implement the GraphRAG patterns we’ll discuss. The details of each pattern will include the corresponding query.
Remember, when crafting your query, there’s an invisible “first part” that performs the vector search on your specified node labels and properties (see node_label and embedding_node_property parameters in the from_existing_graph method). See the Neo4j Vector documentation for an example. This first part returns the found nodes and their similarity scores as node and score, which you can then use in your retrieval query to execute further traversals. You can also use custom parameters and the $embedding parameter for the question embedding. Here is an example of how this might look (example from LangChain Neo4j Vector documentation):
retrieval_query = """
RETURN "Name:" + node.name AS text, score, {foo:"bar"} AS metadata
"""
retrieval_example = Neo4jVector.from_existing_index(
OpenAIEmbeddings(),
url=url,
username=username,
password=password,
index_name="person_index",
retrieval_query=retrieval_query,
)
retrieval_example.similarity_search("Foo", k=1)In the above example, a vector similarity search executes on the existing index person_index using the user input “Foo” and the name, the score, and some metadata are returned for the one node with the best fit (k=1).
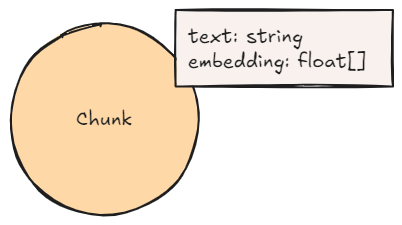
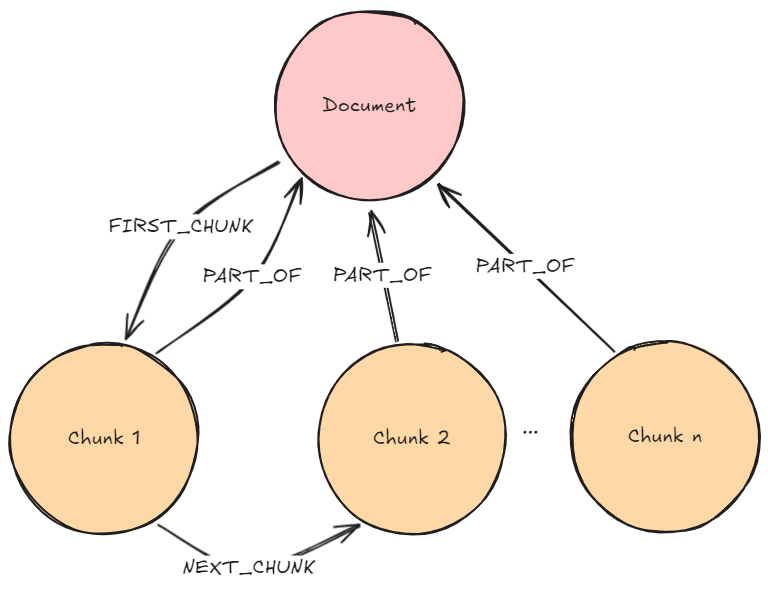
In the graph pattern of almost every pattern, you will see chunk nodes. They are the basis for most of the GraphRAG patterns and have at least the following two properties: text and embedding, where text contains the human-readable text string of the chunk, and embedding contains the calculated embedding of the text.
Let’s now dive into the various GraphRAG patterns.
Basic GraphRAG patterns—retrieval patterns on a lexical graph
You’ve probably come across these RAG patterns before — they’re the usual suspects when diving into RAG on unstructured data. Often showcased in vector databases, these patterns actually rely on relationships within the data.
Basic retriever
Name: Basic Retriever
Also known as: Naive Retriever, Baseline RAG, Typical RAG
Context: It’s useful to chunk large documents into smaller pieces when creating embeddings. An embedding is a text’s semantic representation capturing the meaning of what the text is about. If the given text is long and contains too many diverse subjects, the informative value of its embedding deteriorates.
Required pre-processing: Split documents into chunks and use an embedding model to embed the text content of the chunks.
Required graph pattern: Basic Lexical Graph
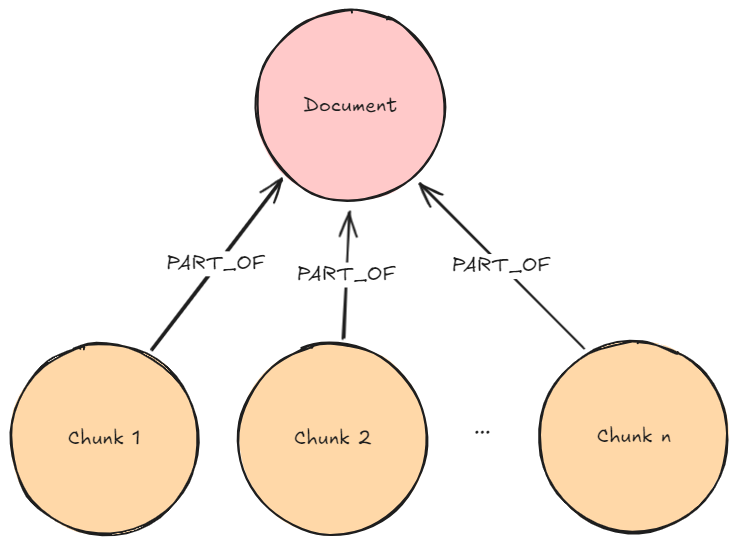
Description: The user question is embedded using the same embedder used before to create the chunk embeddings. A vector similarity search executes on the chunk embeddings to retrieve k (number previously configured by developer/user) most similar chunks.
Usage: This pattern is useful if the user asks for specific information about a topic that exists in one or more (but not too many) chunks. The question should not require complex aggregations or knowledge about the whole dataset. It’s easy to understand, implement, and get started with since the pattern only contains a vector similarity search.
Retrieval query: No additional query is necessary since the Neo4j Vector retriever retrieves similar chunks by default.
Resources: Advanced Retriever Techniques to Improve Your RAGs, Implementing advanced RAG strategies with Neo4j
GraphRAG Pattern Catalog: Basic Retriever
Existing implementation: LangChain Retrievers: Vector store-backed retriever, LangChain: Neo4jVector
Example implementation: LangChain Templates: Neo4j Advanced RAG
Parent-child retriever
Name: Parent-Child Retriever
Also known as: Parent-Document-Retriever
Context: As mentioned, embeddings represent a text’s semantic meaning. A more narrow piece of text will yield a more meaningful vector representation since there is less noise from multiple topics. However, if the LLM only receives a small piece of information for answer generation, the information might be missing context. Retrieving the broader surrounding text that the found information resides within solves the problem.
Required pre-processing: Split documents into (bigger) chunks (parent chunks) and further split these chunks into smaller chunks (child chunks). Use an embedding model to embed the text content of the child chunks. Note that it isn’t necessary to embed the parent chunks since they’re only for the answer generation and not for similarity search.
Required graph pattern: Parent-Child Lexical Graph
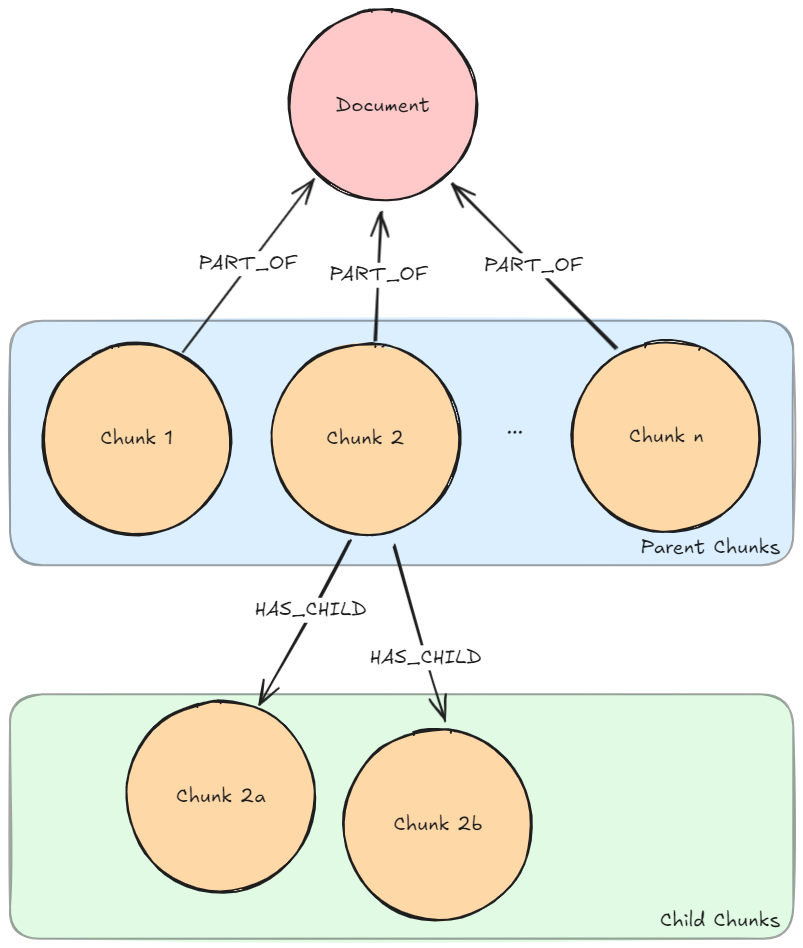
Description: The user question is embedded using the same embedder used to create the chunk embeddings. A vector similarity search is executed on the child chunk embeddings to find k (number previously configured by developer/user) most similar chunks. The parent chunks of the found child chunks are retrieved.
Usage: This pattern is a useful evolution of the Basic Retriever. It is especially useful when several topics are covered in a chunk, which influences the embedding quality negatively, while smaller chunks will have more meaningful vector representations, which can then lead to better similarity search results. With limited additional effort, better results can be obtained.
Retrieval query:
retrieval_query = """
MATCH (node)<-[:HAS_CHILD]-(parent)
WITH parent, max(score) AS score // deduplicate parents
RETURN parent.text AS text, score, {} AS metadata
"""Resources: Advanced Retriever Techniques to Improve Your RAGs, Implementing advanced RAG strategies with Neo4j
GraphRAG Pattern Catalog: graphrag.com: Parent-Child Retriever
Existing implementation: LangChain Retrievers: Parent Document Retriever
Example implementation: LangChain Templates: Neo4j Advanced RAG
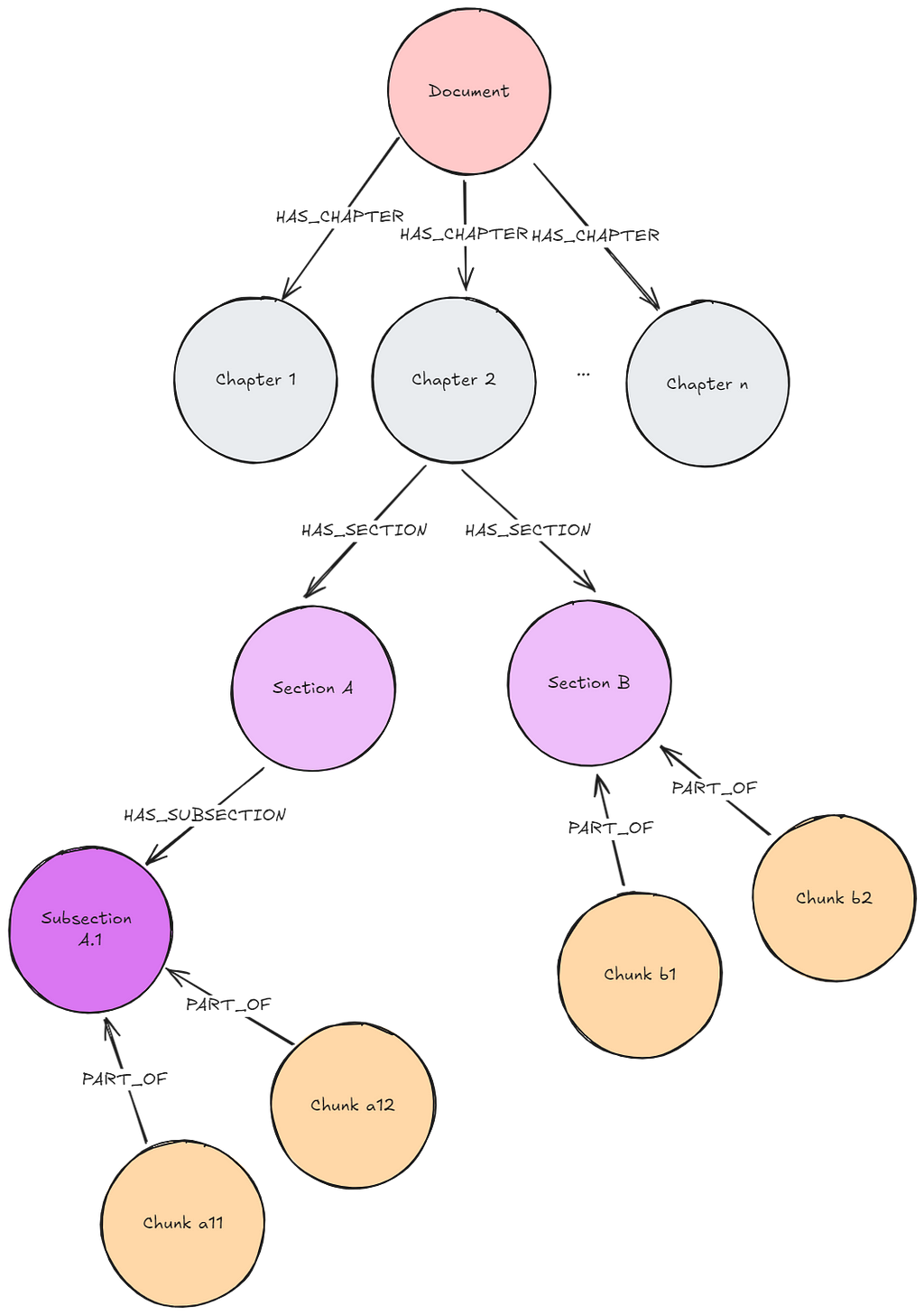
Similar patterns can be implemented on Lexical Graphs With a Sibling Structure or Lexical Graphs With a Hierarchical Structure, where the additional context doesn’t come from retrieving just the parent document but sibling documents or a previously set depth of structures. The Lexical Graph With Sibling Structure is, for example, currently implemented in Neo4j’s LLM Knowledge Graph Builder.
Note that there are two kinds of retrievers possible on a Lexical Graph With a Hierarchical Structure:
- Bottom-up: Execute retrieval on leaf nodes and retrieve other chunks higher up in the tree (see Episode 24 of Going Meta — a series on graphs, semantics, and knowledge)
- Top-down: Use the top-level nodes to determine which subtree(s) to consider for retrieval. Iterate this methodology until the set of nodes for the similarity search is reasonably narrowed down (see RAG Strategies — Hierarchical Index Retrieval).
Hypothetical question retriever
Name: Hypothetical Question Retriever
Context: The vector similarity between a question’s embedding and the text embedding of an appropriate answer or text source might be quite low. If we have question-chunk pairs available, we can execute a vector similarity search on the question embeddings, which will probably deliver much better results than a vector similarity search on the original text chunk.
Required pre-processing: Use an LLM to generate hypothetical questions answered within the chunks. Embed the question using an embedding model. Record the relationship between questions and the chunk that contains their answer.
Required graph pattern: Lexical Graph with Hypothetical Questions
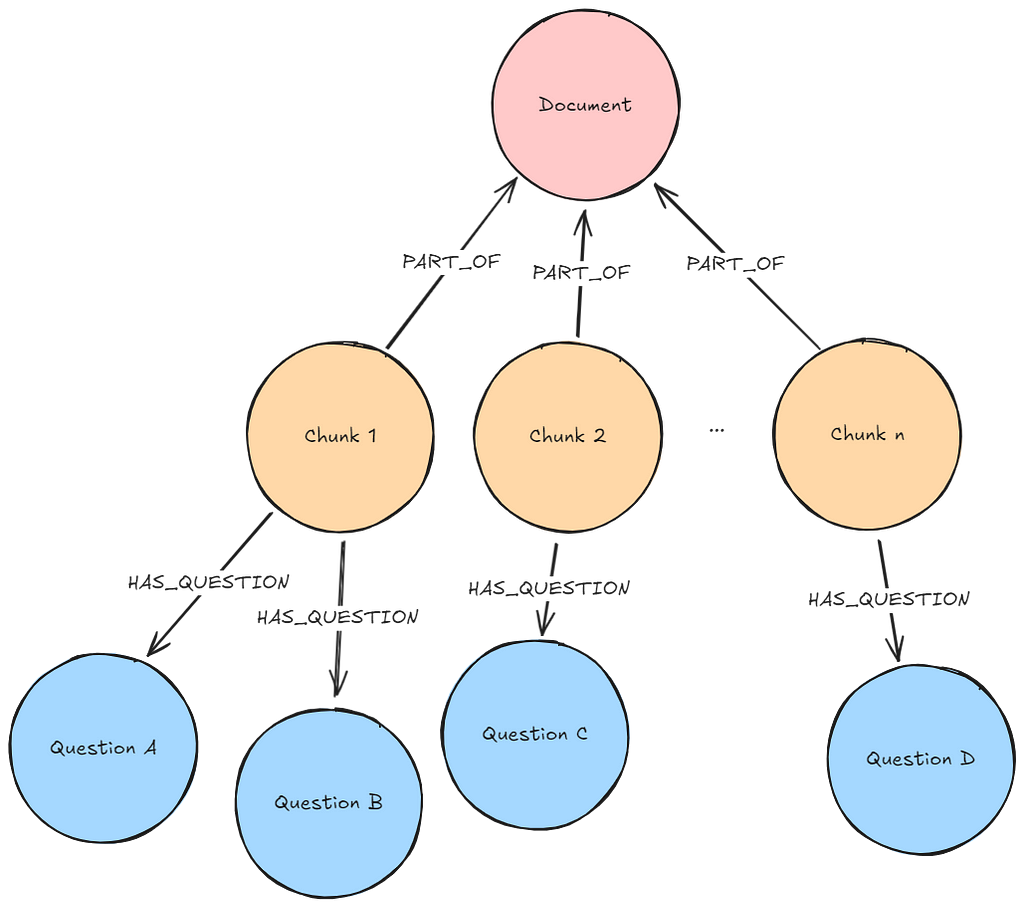
Description: The user question is embedded using the same embedder used to create the question embeddings. A vector similarity search executes on the previously generated questions. k (number previously configured by developer/user) most similar questions are found and their related chunks are retrieved.
Usage: This pattern is an addition to the patterns above. It can yield better results in the vector similarity search. However, it also requires more pre-processing effort and cost in LLM calls for question generation.
Retrieval query:
retrieval_query = """
MATCH (node)<-[:HAS_QUESTION]-(chunk)
WITH chunk, max(score) AS score // deduplicate chunks
RETURN chunk.text AS text, score, {} AS metadata
"""Resources: Implementing advanced RAG strategies with Neo4j
GraphRAG Pattern Catalog: graphrag.com: Hypothetical Question Retriever
Existing implementation: MultiVector Retriever: Hypothetical Queries
Example implementation: LangChain Templates: Neo4j Advanced RAG
The Hypothetical Question Retriever is in a way quite similar to the Hypothetical Document Embeddings (HyDE) Retriever (see RAG using LangChain: Part 5 — Hypothetical Document Embeddings). The main idea behind them is to increase the similarity between the user question and the available text. In the Hypothetical Question Retriever, we generate hypothetical questions the user question matches against. In the HyDE retriever, the LLM generates a hypothetical answer to the user question (without using the grounding database) and, subsequently, the hypothetical answer is matched against the actual chunks in the database to find the best fit. We aren’t looking at the HyDE retriever in more detail since it lives in the pre-processing RAG phase, rather than in the retrieval phase, and also doesn’t require a specific kind of underlying graph pattern.
Intermediate GraphRAG patterns—retrieval patterns on a domain graph
A Domain Graph contains your business domain knowledge. It contains entities and the relationships between them. Frequently used example domain graphs are the Movie Graph or the Northwind Graph.
Since Domain Graphs will look different based on the underlying domain, it isn’t possible to provide a blueprint of how one would look. Just keep in mind that they contain structured data adhering to a schema.
Providing the information contained in a Domain Graph within a question-answer application where natural language queries lead to (deterministic) structured retrieval of data can be executed in several ways.
Cypher templates
Name: Cypher Templates
Context: For the retrieval of structured data, we need to translate a user question into a query that can execute on a database. A basic approach is having predefined queries written by domain experts to which a user question can be mapped.
Required pre-processing: Several domain-specific Cypher queries (containing parameters) and a description of what they do become available to the LLM.
Required graph pattern: Domain Graph
Description: Given a user question, an LLM decides which of the Cypher Templates to use. The LLM can extract parameters from the user question and plug them into the template. The query executes against the database, and the results are provided back to the LLM to generate an answer.
Usage: Templates can be created when the type of questions a user will pose to the domain graph is previously known. A shortcoming of this approach is the restriction to given template queries. What happens if the user asks a question that would result in a query that isn’t existent in the templates?
Resources: Enhancing Interaction between Language Models and Graph Databases via a Semantic Layer
GraphRAG Pattern Catalog: graphrag.com: Cypher Templates
Dynamic Cypher generation
Name: Dynamic Cypher Generation
Context: Many user questions for structured data will contain several filters, but not always the exact same ones. Let’s use the example of the Movie Graph to illustrate. There might be several related questions being asked:
– Which movies has Steven Spielberg directed?
– Which movies did Steven Spielberg direct between 2000 and 2010?
– Which movies did Steven Spielberg direct between 2000 and 2010 that [example]?
This list can infinitely continue. You would not want to create a Cypher Template for every one of these questions. The solution is to (partially) dynamically generate Cypher queries based on the parameters actually given in the user question.
Required pre-processing: Snippets of parameterized Cypher queries and a description of what they do become available to the LLM.
Required graph pattern: Domain Graph
Description: Given a user question, an LLM decides which snippet to use. The LLM extracts parameters from the user question, plugs them into the snippets, and combines them to create a full query. The query execute against the database, and the results are provided back to the LLM to generate an answer.
Usage: This pattern is a useful evolution of the Cypher Templates. It’s much more flexible, allowing for more diverse user questions to be answered. Still, the provided snippets limit the range of questions.
Resources: Build a Knowledge Graph-based Agent With Llama 3.1, NVIDIA NIM, and LangChain
GraphRAG Pattern Catalog: graphrag.com: Dynamic Cypher Generation
Text2Cypher
Name: Text2Cypher
Context: The GraphRAG patterns Cypher Templates and Dynamic Cypher Generation are limited by the queries and query snippets defined during implementation.
Required pre-processing: The LLM should obtain the database schema together with a description of the domain. This will significantly improve the results. You can optionally enhance the schema by actual data value samples, distributions, or lists of categorical values to improve value translation from questions to queries.
Required graph pattern: Domain Graph
Description: The user question translates to a Cypher query by the LLM. The query executes against the database, and the results are provided back to the LLM to generate an answer.
Usage: This pattern is highly flexible. There are no predefined queries, and, in theory, the LLM can generate any query. However, this pattern isn’t 100-percent reliable. LLMs are not perfect when translating text to Cypher. If the LLM can’t translate the given user query correctly, it will not be able to provide any answer.
Resources: Integrating Neo4j into the LangChain ecosystem, LangChain Cypher Search: Tips & Tricks
GraphRAG Pattern Catalog: graphrag.com: Text2Cypher
Existing implementation: LangChain: GraphCypherQAChain
If we compare Cypher Templates, Dynamic Cypher Generation, and Text2Cypher, we could use the following analogy (illustrated in the images below):
- Cypher Templates is like having different similar toys that consist of one piece. There’s not much freedom.
- Dynamic Cypher Generation is like playing with building bricks. There is more freedom in how to put them together, but it is still quite fail-proof.
- Text2Cypher is like painting. There is a lot of freedom, but you can also fail easily.

The above patterns also encounter the same challenge: When extracting the entities from the user question, the entity aliases need to match the existing values in the database or the query will fail to return any results. You can mitigate this problem by providing an enhanced schema or by using a full-text index search on the database as in LangChain Templates: Neo4j Advanced RAG (Neo4j Cypher FT).
The Text2Cypher pattern is the most flexible, but also the most unreliable. However, there’s a lot of work under way to improve its reliability. Approaches include:
- Fine-tuning LLMs on natural language to Cypher translations (e.g., Llama3 Fine-Tuned on Text2Cypher)
- Optimizing the use of few-shot examples (e.g., Neo4j Live: Enhancing text2cypher with In-Context Learning & Fine-Tuning or Improving LLM-based KGQA for multi-hop Question Answering with implicit reasoning in few-shot examples)
- Self-healing generation — if the generated query cannot execute on the database, return the query with the obtained exception message to the LLM that gets another chance at generating a better query (e.g., Generating Cypher Queries With ChatGPT 4 on Any Graph Schema)
The choice of the language model also plays a role in how good the results are since every language model has its own unique strengths and weaknesses. I will elaborate on this topic more during my talk (LLM Query Benchmarks: Cypher vs SQL) at this year’s NODES conference, a 24-hour free online event for everything knowledge graph-related.
Advanced GraphRAG patterns—Retrieval patterns on a lexical graph and domain graph combined
There are many scenarios in which you end up with a combination of a Lexical Graph and a Domain Graph. On the one extreme, you already have a Domain Graph and enrich it by adding unstructured documents, or on the other extreme, you only have unstructured documents you want to extract entities from to create a Domain Graph. There are many scenarios in between, like using text properties for vector search. In all scenarios, you can use additional GraphRAG retrieval patterns to further improve your retrieved results.
Graph-enhanced vector search
Name: Graph-Enhanced Vector Search
Also known as: Graph + Vector, Augmented Vector Search
Context: The biggest problem with basic GraphRAG patterns is finding all relevant context necessary to answer a question. The context can be spread across many chunks not being found by the search. Relating the real-world entities from the chunks to each other and retrieving these relationships together with a vector search provides additional context about these entities that the chunks refer to. They can also be used to relate chunks to each other through the entity network.
Required pre-processing: Use an LLM to execute entity and relationship extraction on the chunks. Import the retrieved triples into the graph.
Required graph pattern: Lexical Graph with Extracted Entities
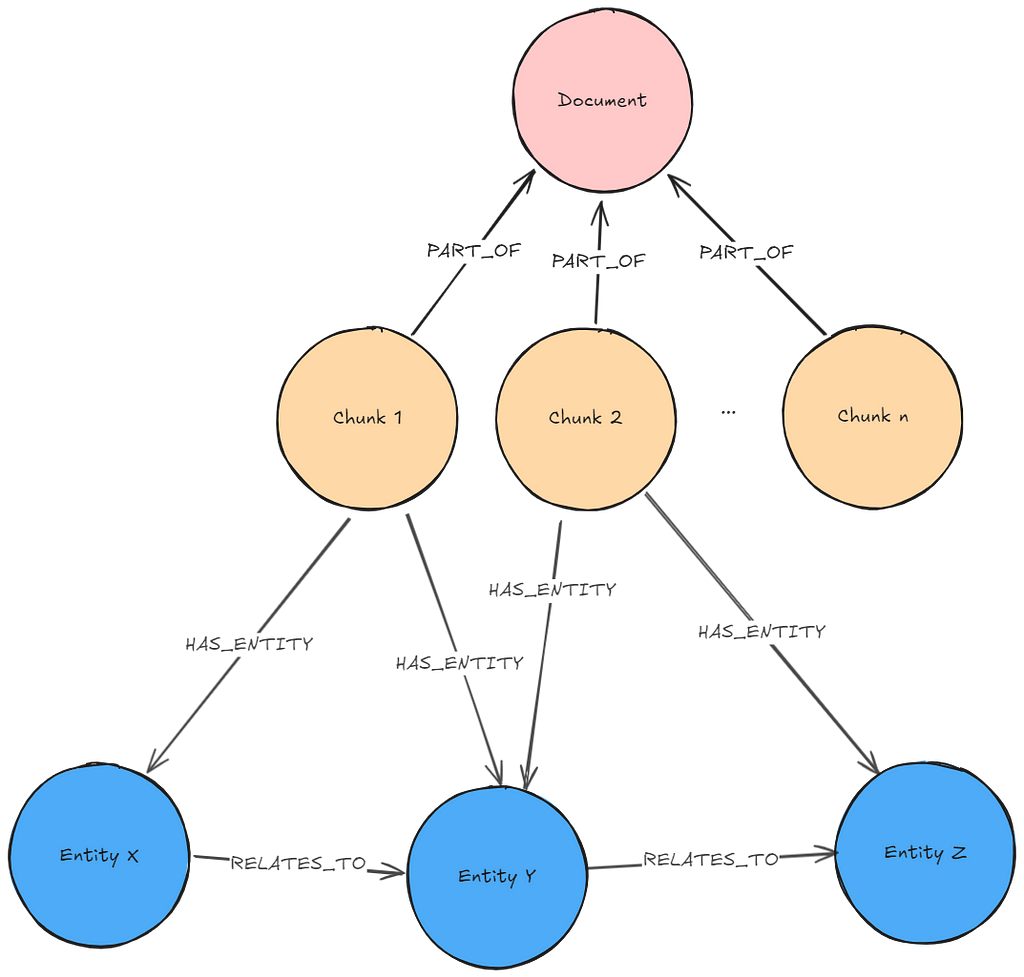
Description: The user question embeds using the same embedder used to create chunk embeddings. A vector similarity search executes on the chunk embeddings to find k (number previously configured by developer/user) most similar chunks. A traversal of the Domain Graph starting at the found chunks executes to retrieve more context.
Usage: This pattern is useful for retrieving more enriched context than the results of executing only a vector search. The additional traversal retrieves the interaction of entities within the provided data, which reveals richer information than the retrieval of specific text chunks and subsequently provides higher-quality inputs for generating the answer. Naturally, the pre-processing for this GraphRAG pattern entails more effort and expense (cost and time). Furthermore, the amount of information returned by the graph traversal adds significantly to the size of the context processed by the LLM.
Retrieval query:
retrieval_query = """
MATCH (node)-[:PART_OF]->(d:Document)
CALL { WITH node
MATCH (node)-[:__HAS_ENTITY__]->(e)
MATCH path=(e)(()-[rels:!HAS_ENTITY&!PART_OF]-()){0,2}(:!Chunk&!Document)
…
RETURN …}
RETURN …
"""Resources: Going Meta — Ep 23: Advanced RAG patterns with Knowledge Graphs
GraphRAG Pattern Catalog: graphrag.com: Graph-Enhanced Vector Search
Example implementation: Neo4j’s Knowledge Graph Builder
There are some variations of this retriever:
- Entity disambiguation — A naive Entity Extraction Pipeline will pull out any entities from texts. However, multiple entities might actually be referred to differently in the text but mean the same real-world entity. To keep the graph clean, an entity disambiguation step can be executed, where these entities are merged. Possible ways of doing this are described in Implementing ‘From Local to Global’ GraphRAG with Neo4j and LangChain: Constructing the Graph and Entity Linking and Relationship Extraction With Relik in LlamaIndex.
- Question-guided/Schema-defined extraction — Instead of letting the LLM extract any kinds of entities and relationships, provide a set of questions or a fixed schema to guide the LLM to extract only the domain knowledge that is relevant for the application. This approach will narrow down the scope and the volume of the extraction (e.g., Introducing WhyHow.AI Open-Source Knowledge Graph Schema Library — Start Experimenting Faster).
- Entity embeddings — When extracting the entities and the relationships using an LLM, we can instruct the LLM to also create/extract entity and relationship descriptions. These can be embedded and subsequently be used for the initial vector search and other guidance during traversal.
- Ontology-driven traversal — Instead of hard-coding a traversal into your application code, you can provide an ontology for the traversal. This approach is explained in Going meta — Ep 24: KG+LLMs: Ontology driven RAG patterns.
Global community summary retriever
Name: Global Community Summary Retriever
Also known as: Microsoft GraphRAG, Global Retriever
Context: Certain questions that can be asked on a whole dataset don’t just relate to things present in some chunks but rather search for an overall message that is overarching in the dataset. The previously mentioned patterns aren’t suited to answer these kinds of “global” questions.
Required pre-processing: In addition to extracting entities and their relationships, we need to form hierarchical communities within the Domain Graph. This can be done by using the Leiden algorithm. For every community, an LLM summarizes the entity and relationship information into Community Summaries.
Required graph pattern: Lexical Graph with Extracted Entities and Community Summaries
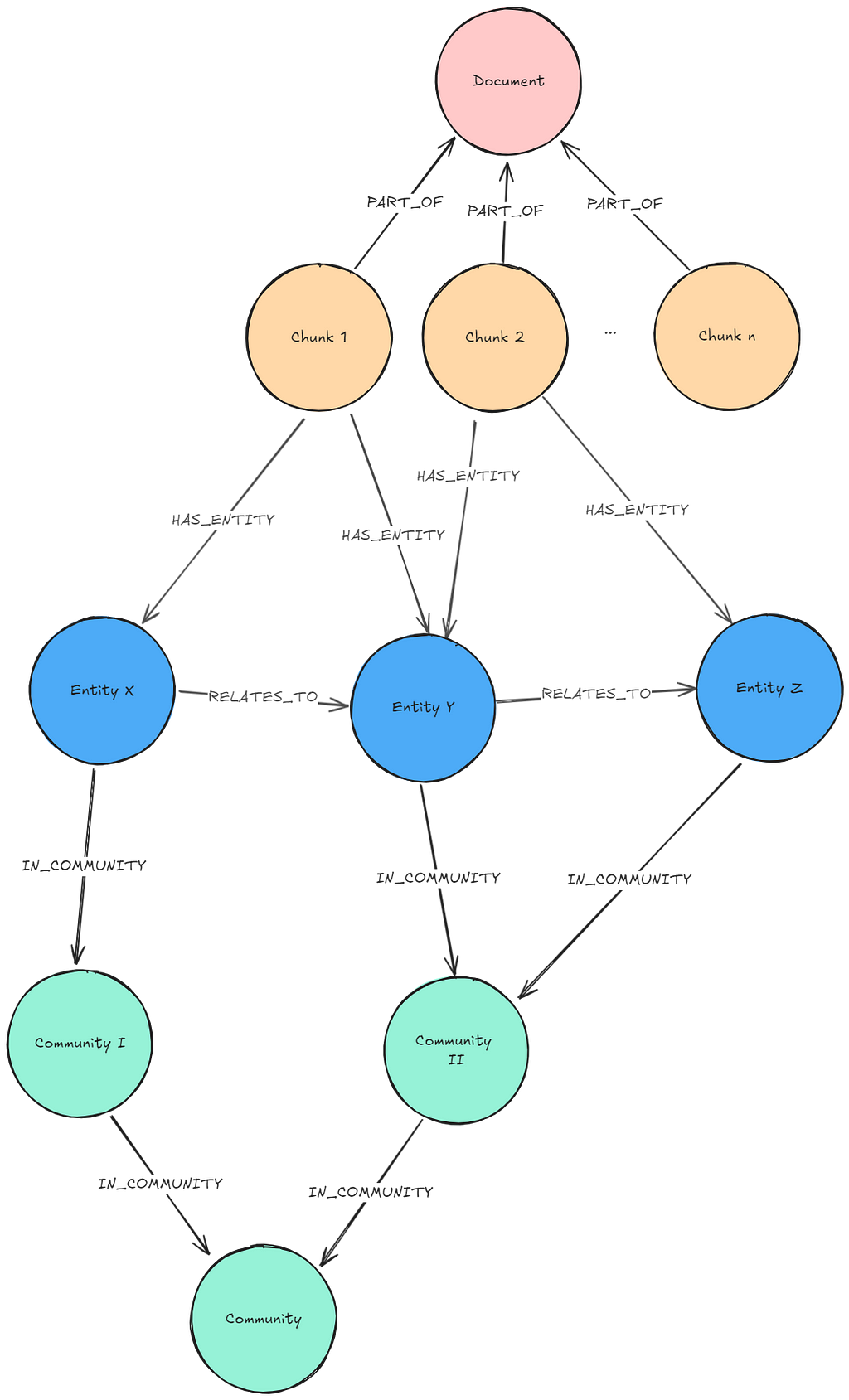
Description: Given the user question and a given community level, the Community Summaries are retrieved and given to the LLM.
Usage: This pattern is useful for questions that have a global character. Examples would be summarizing the content of the whole database or looking for topic structures across the whole data. The effort of setting up the required graph pattern is quite high since there are a lot of steps to be taken: entity and relationship extraction, community detection, and community summarizations. We must consider which of these tasks shall be executed by LLMs and which tasks can be handled differently to keep the pre-processing cost acceptable.
Retrieval query: This approach does not use Neo4j Vector to fetch similar vector nodes. It fetches all Community Summaries of a given level. Here is an example query:
community_summaries = """
MATCH (c:__Community__)
WHERE c.level = $level
RETURN c.full_content AS output
"""Resources: From Local to Global:A Graph RAG Approach to Query-Focused Summarization, Implementing ‘From Local to Global’ GraphRAG with Neo4j and LangChain: Constructing the Graph, Integrating Microsoft GraphRAG into Neo4j
GraphRAG Pattern Catalog: graphrag.com: Global Community Summary Retriever
Example implementation: Microsoft GraphRAG
There are several variations in which you could use the Lexical Graph with extracted entities, communities, and community summaries:
- A Local Retriever could start by executing a vector search on the entity embeddings and traversing to related entities, chunks, or communities (e.g., see Integrating Microsoft GraphRAG into Neo4j).
- Depending on the question, we could also execute a vector similarity search on embeddings of the Community Summaries first to identify which subgraph is relevant for the question, then traverse from the communities to its entities and chunks to retrieve information.
Summary
While we’ve explored a variety of GraphRAG patterns, this is just the beginning of an exciting journey. The current list captures the early stages of the GraphRAG evolution. As we move forward, new patterns will undoubtedly emerge, bringing fresh insights and possibilities.
Each RAG pattern is tailored to answer specific types of questions, requiring unique graph patterns and pre-processing steps. Finding the perfect GraphRAG pattern for your application isn’t straightforward — it demands experimentation with different retrieval patterns and a proper evaluation of the results. It is very likely that one single pattern will not serve every purpose well, which is why an agentic approach that adapts to various queries will almost always be necessary. The patterns presented here, all target Once Retrieval strategies where the context for an answer to a user question is provided, querying the database only once. More complex questions might require an Iterative or a Multi-Stage Retrieval paradigm combining the use of different patterns (see Graph Retrieval-Augmented Generation: A Survey for more details on Retrieval Paradigms).
The journey to discovering the ideal GraphRAG pattern is an exciting one, filled with trial, error, and innovation. Let’s embark on this journey together. Check out the open source GraphRAG Pattern Catalog and contribute to it. Are there other patterns you encountered that aren’t listed yet? If you have any feedback or suggestions, or want to share applications, feel free to open an issue. If you want to discuss GraphRAG patterns, join the GraphRAG Discord channel.
Stay curious and keep experimenting — who knows what groundbreaking patterns you’ll uncover next!
Contributors: Michael Hunger & Andreas Kollegger
Essential GraphRAG
Unlock the full potential of RAG with knowledge graphs. Get the definitive guide from Manning, free for a limited time.

GraphRAG Field Guide: Navigating the World of Advanced RAG Patterns was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

15 best graph visualization tools for your Neo4j graph database

GraphRAG and agentic architecture: Practical experimentation with Neo4j and NeoConverse
