


High-Fidelity Load Preview – Now Available for Neo4j Data Importer
6 min read


In our previous release, we introduced the “Preview” feature that helps users visualize graph data before committing data to their database.
Importing Your Data Into Neo4j Just Got Even Easier
Our initial approach was to scan the first few rows of relationship files, and then create source and target nodes along with the corresponding relationship on each row. It’s straightforward and trivial to demonstrate how data is connected.
However, this approach has several drawbacks as node files are not scanned, thereby limiting the fidelity. Here are a few limitations we had to work through:
- Relationship rows don’t usually contain node properties information, so columns mapped to IDs in the relationships are usually the only available node properties.
- The graph preview doesn’t always reveal the actual graph structure since relationships and their linked nodes are not guaranteed to exist. For example, if an associated node file is empty, the preview approach still loads corresponding nodes and relationships from relationship files.
- Unconnected nodes cannot be previewed because there are no corresponding relationship file mappings.
In the latest release, we created an enhanced approach to substantially improve the preview fidelity. You can preview the graph at any stage of the modeling/mapping process. The improved preview process is as follows:
- At the beginning of the preview, the graph model is validated.
All entities that are not fully mapped are disregarded in the subsequent steps.
- For each fully mapped relationship, the mapped files are scanned. Then the first few rows of relationship data are buffered.
- For each fully mapped node, the first few rows of the mapped files are scanned and compared with the buffered relationship. Only rows with from/to ID values that appeared in the buffered relationships are loaded. In this way, the preview approach maximizes the graph’s connectivity rather than creating many isolated nodes in the preview.
- After adding the nodes, relationships in the buffer are attached to the loaded nodes.
- Finally, disconnected nodes are loaded, either isolated nodes in the model or as ones that don’t yet have a fully mapped relationship. In addition, nodes with no matched rows found in step three will be treated as solo nodes and will be loaded as well.
Using the enhanced workflow drastically improves the preview accuracy. All steps above utilize the same transaction instance of neo4j-driver. This way the whole data loading process is under an identical context, which can be deduplicated and constructed as a connected graph. Once finished, the operation will be rolled back so that the data is not committed to the database.
Here’s an example to demonstrate how we did it.
If you want to follow these steps with your own Neo4j instance, you can create a free, empty Neo4j AuraDB database and click the “Import” button to use Data Importer.
Neo4j Aura – Fully Managed Cloud Solution
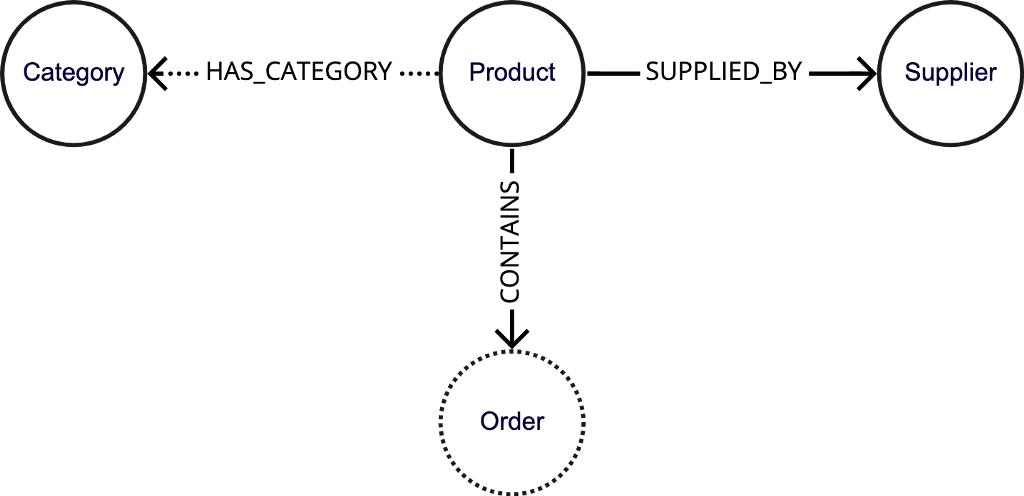
Suppose the user is utilizing Data Importer to model the Northwind graph (zip file to load as model and data), and some graph entities, like the HAS_CATEGORY relationship and the Order node, have not yet been fully mapped. In the Data Importer graph modeling canvas, these graph entities with incomplete mappings are drawn with dashed outlines as shown below.
To better visualize the preview process, the flowchart below demonstrates how Data Importer previews the Northwind graph example.
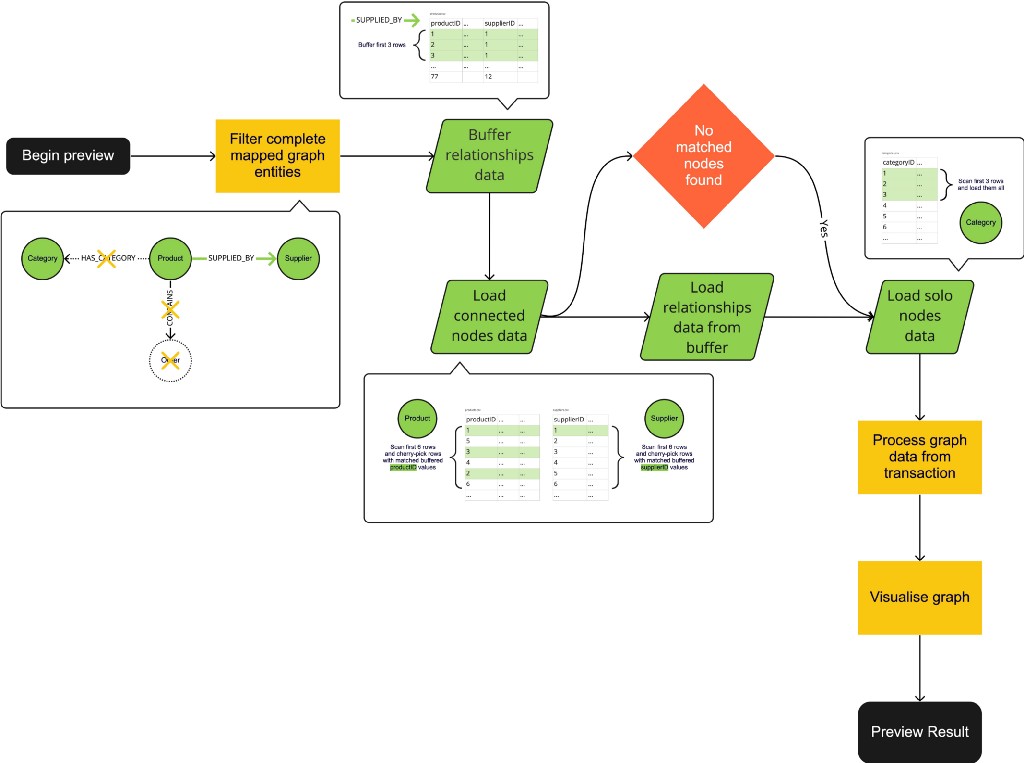
Assume we’re going to scan the first three relationship rows for each relationship file and the first six node rows for each node file and pick up to three matched rows in the preview. Using our new workflow, here’s how it would go:
- The graph model will be filtered. Only
Category,Product, andSuppliernodes andSUPPLIED_BYrelationship will be taken into account. - The corresponding file
products.csvmapped inSUPPLIED_BYrelationship will be scanned and the first 3 rows, which contain columns mapped to IDs ofProductandSuppliernodes are buffered. ProductandSuppliernodes will be loaded by scanning corresponding mapped filesproducts.csvandsuppliers.csvfor the first 6 rows. productID in rows with value1,2, or3will be cherry-picked fromproducts.csv, andsupplierIDin rows with value 1 will be cherry-picked fromsuppliers.csv.SUPPLIED_BYrelationship will be loaded by buffered data fromproducts.csvin step two. As a result,ProductandSuppliernodes are connected.- The
Categorynode doesn’t have any fully mapped relationships, so it will be loaded by picking all the first three rows without comparison with buffered relationship data. - Graph data is built via the
transactioninstance, and it will be fetched and processed for graph visualization. Then thetransactionwill be rolled back.
The preview result in this example is shown below:
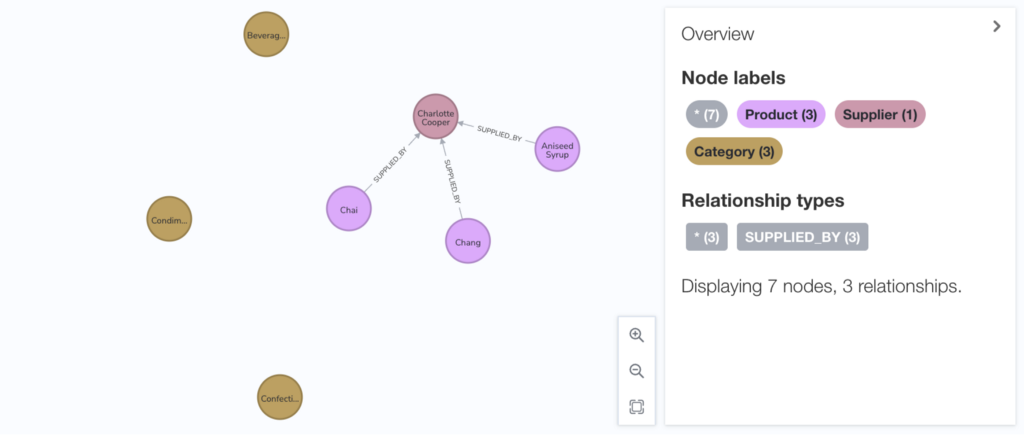
In practice, we actually preview up to 300 relationships in total and scan up to 50,000 rows in each node file to preview at accurately as possible. This is more time-consuming than our the previous approach, so we introduced a progress bar to indicate the progress of data loading while you’re waiting for the result. We think it’s worth the wait for Preview’s improved accuracy.
Improving the preview logic to more faithfully simulate the load process makes errors a lot easier to catch before committing to a load.
Additionally, we now support the previewing of properties. Through these preview improvements, we’re making it easier than ever for users to catch any mapping problems with the highest fidelity preview we’ve ever made.
Please try out the new feature and let us know if it is helpful for you. You can submit feedback and feature requests here. So far, we’ve gotten really great feedback and suggestions.

Try it out now in your Neo4j Aura console.
High-Fidelity Load Preview — Now Available for Neo4j Data Importer was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.




