


Introducing the Neo4j Text2Cypher (2024) Dataset

Machine Learning Engineer, Neo4j
4 min read

Authors: Makbule Gulcin Ozsoy, Leila Messallem, Jon Besga
We’re excited to share the Neo4j Text2Cypher (2024) Dataset with you. It’s designed to help train and benchmark Text2Cypher models with ease.
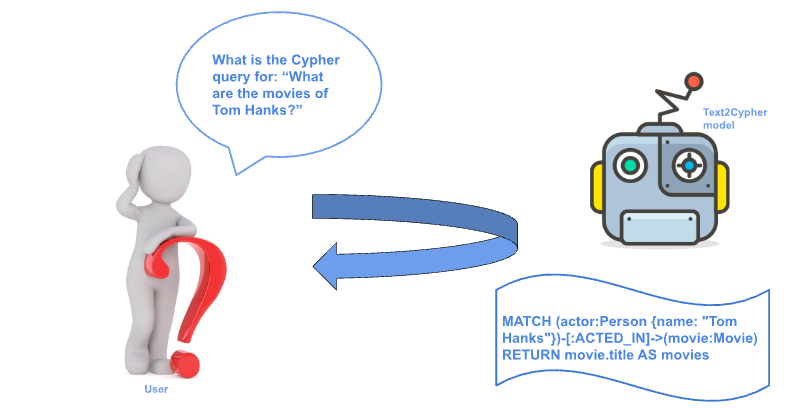
A common use of machine learning is translating natural language into programming or domain-specific languages (DSL). A great example of this is the Text2Cypher task, where plain language questions are seamlessly converted into Cypher query language (see Figure 1). This process can be powered by large language models (LLMs) or supervised fine-tuned models, which rely on datasets that pair natural language with Cypher translations.
While several Text2Cypher datasets exist, many are prepared separately, making them hard to use together. That’s where the Neo4j Text2Cypher (2024) Dataset comes in! It brings together instances from publicly available datasets, cleaning and organizing them for smoother use.
Dataset Preparation
We followed a step-by-step approach to prepare the final dataset:
- Identified and gathered publicly available datasets
- Combined and cleaned the data
- Created training and test splits
Step 1 — Exploration and Analysis of Input Datasets
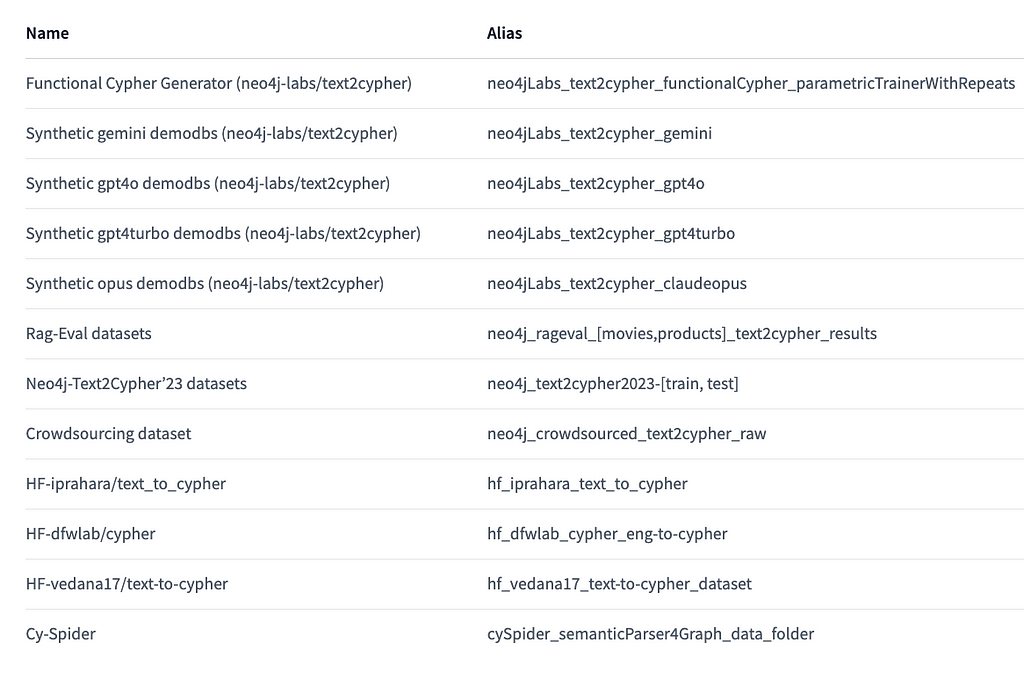
We identified 25 publicly available datasets, including Neo4j resources (e.g., Neo4jLabs), HuggingFace datasets, and academic papers. We then chose 16 based on their license, accessibility, and data fields. The selected datasets:
- Neo4jLabs datasets (text2cypher): Named with the suffix ‘neo4jLabs’
- Neo4j Internal projects’ datasets: Named with the suffix ‘neo4j’
- HuggingFace datasets (text_to_cypher, cypher, text-to-cypher): Named with the suffix ‘hf’
- Academic papers — CySpider (SemanticParser4Graph): Text2Sql or Text2Sql2Cypher datasets, named with the suffix ‘cySpider’
Step 2 — Collection and Combination of Data
We combined the datasets into a single format, where each row reformatted to include fields “question”, “schema”, “cypher”, “data_source”, “database_reference_alias”, and “instance_id”, as described in the table below.

The combined dataset is cleaned in two steps:
- Manual updates — We manually check queries, fix errors by removing or updating unwanted characters (e.g., backticks), and delete irrelevant entries (e.g., “Lorem ipsum …”). We also remove duplicates based on fields [“question”, “cypher”].
- Syntax validation — We check each cypher query for syntax errors, and remove any rows with incorrect queries.
Step 3 — Splitting Data
The final step is preparing for the train/test split. We identified three dataset groups:
- Train-specific datasets — Files with ‘train’ in the name, used for training
- Test-specific datasets — Files with ‘test’ or ‘dev’ in the name, used for testing or validation
- Remaining datasets — Files with no specified use
We assigned Train-specific datasets to the training split and Test-specific datasets to the test split. The remaining datasets were split 90:10 for training and testing. Each split was shuffled to prevent overfitting from sequence or repetitive questions.
Dataset Summary
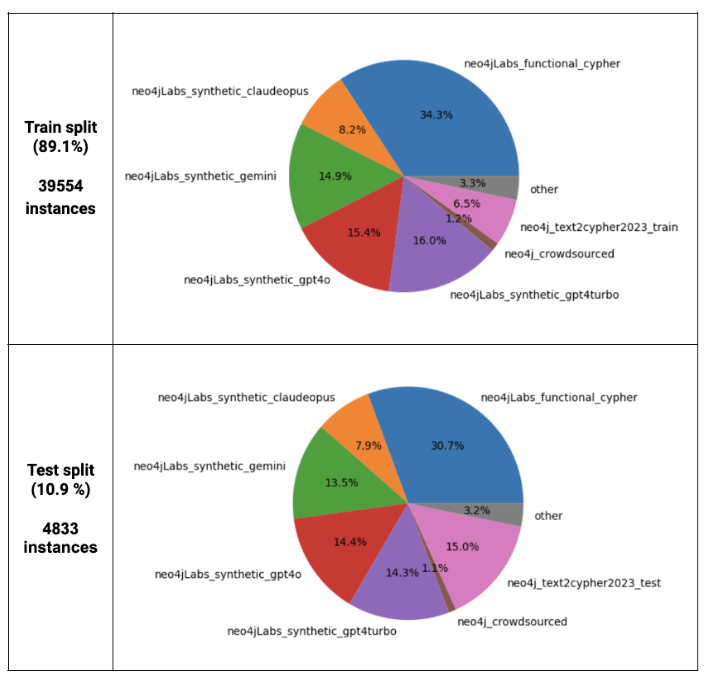
The data preparation resulted in 44,387 instances, with 39,554 instances in the training split and 4,833 instances in the test split. The train and test splits consist 89 percent and 11 percent of the overall data, respectively. Their distribution across data sources is similar, as shown below.
Not every instance in the training and test sets has database access indicated by the ‘database_reference_alias’ field, but for those that do, the potential is huge! Here’s a brief overview of instances with database access to support your exploration:
- Training Set
– Rows with database access: 22,093
– 55.85 percent of the training set - Test Set
– Rows with database access: 2,471
– 51.12 percent of the test set
The databases available in the ‘database_reference_alias’ field are detailed in Crowdsourcing Text2Cypher dataset. Dive into the dedicated application (Text2Cypher Crowdsourcing App and Neo4j Browser Demo) and see the data firsthand.
Summary
Machine learning is frequently used to natural language into programming or domain-specific languages, like turning plain text into Cypher query language. LLMs or supervised models rely on datasets that pair natural language with Cypher translations.
Existing Text2Cypher datasets can be fragmented, but the new Neo4j-Text2Cypher(2024) Dataset solves this by combining, cleaning, and organizing public data. It includes 44,387 instances — 39,554 for training and 4,833 for testing.
You can access it on HuggingFace. Stay tuned for insights on applying this dataset to various models in future blog posts!
Introducing the Neo4j Text2Cypher (2024) Dataset was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

