








LLM Knowledge Graph Builder — First Release of 2025

Head of Product Innovation & Developer Strategy, Neo4j
9 min read
New features include community summaries, parallel retrievers, and expanded model support for better knowledge graph construction from text
Background
Many developers try to build retrieval-augmented generation (RAG) experiences to interact with information from unstructured data using only vector search and struggle to get to the results that they want. Looking only at text fragments without context only gets you so far. As usual in data engineering, there are more advanced patterns for preprocessing the data and extracting knowledge, one of which is GraphRAG. So when you get around using the data, you’ve surfaced the underlying concepts and can make use of them to connect the pieces and provide relevant context to a user’s questions.
We built, open-sourced, and hosted the LLM Knowledge Graph Builder to let you try out better ways of treating your unstructured data. We preprocess documents, transcripts, web articles, and more sources into chunks, compute text embeddings, and connect them (lexical graph).
But we don’t stop there. We also extract entities and their relationships, which is especially relevant if you ingest multiple documents because you can relate the pieces spread out over multiple sources (entity graph).
This combined knowledge graph then enables a set of different retrievers to fetch data (see below).
Since we launched the LLM Knowledge Graph Builder in June 2024, we’ve had an impressive amount of usage and great feedback from users. It’s now the fourth most popular source of user interaction on AuraDB Free, which makes us really happy.
We did a release in fall 2024, but there were too many AI events, which took most of my time to write a blog post. Over the past few months, the team worked on really nice features — some of which we want to introduce today in the first release of 2025.
What Does the LLM Knowledge Graph Builder Do?
For those of you who don’t know what the tool does, here’s a quick introduction.
If you have a number of text documents, web articles, Wikipedia pages, or similar unstructured information, wouldn’t it be great to surface all the knowledge hidden inside those in a structured way and then use those entities and their relationships to better chat with your data?
The LLM Knowledge Graph Builder:
- Imports your documents
- Splits them into chunks and links them up
- Generates text embeddings for vector search and connects the most similar ones
- Uses a variety of large language models (LLMs) to extract entities and their relationships
- Optionally using a graph schema you can provide
- Stores the nodes and relationships in Neo4j
- And when running against a graph data science-enabled Neo4j instance, it also performs topic clustering and summarization
Get a quick overview of the process and try it out at https://llm-graph-builder.neo4jlabs.com.
The only prerequisite is a publicly accessible Neo4j instance to store your data, which you can create on AuraDB Free (or Aura Pro Trial with Graph Data Science).
Under-the-Hood Blog Series
Over the next few weeks, we have a series of blog posts that explore different aspects of the LLM Knowledge Graph Builder and explain how they work under the hood, so you can benefit from our learnings and apply them to your own GenAI projects.
New Features
Let’s dive into the new features. The main ones are generating Community Summaries and new local and global retrievers for it, as well as running multiple retrievers in parallel for your questions and evaluating them. You can now also guide the extraction with custom prompt instructions.
Additionally, we have some user experience improvements to highlight.
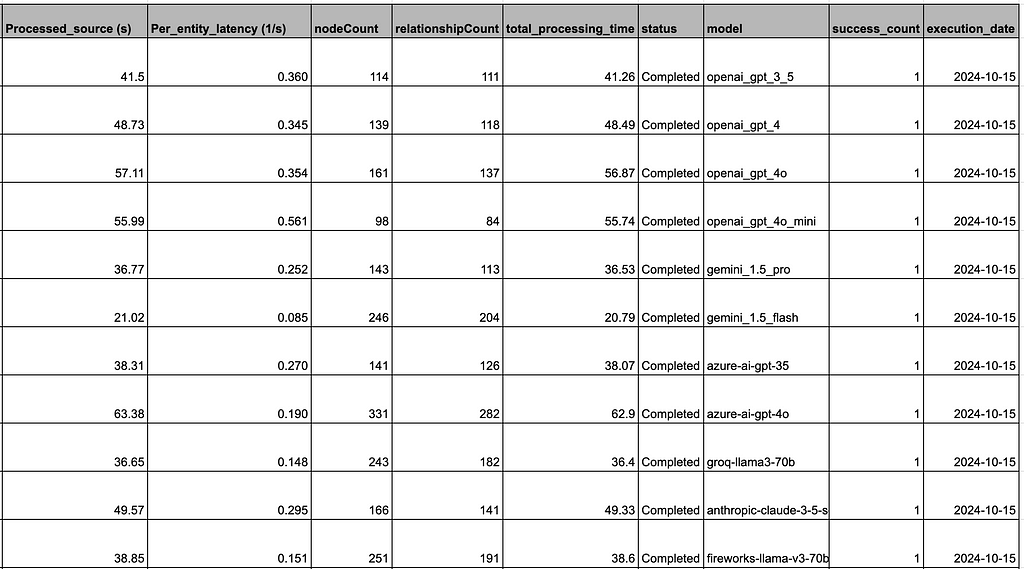
More Models
In development mode or in self-deployment, we tested and configured the LLM Knowledge Graph Builder with a plethora of new models, which we also hint at in the production version:
- OpenAI GPT-4o (and GPT-4o mini)
- Google Gemini 1.5 and 2.0 Pro and Flash
- Qwen 2.5
- Amazon Nova models
- Groq
- Llama 3.x
- Ollama models
- Claude 3.5 Sonnet
- DeepSeek and Microsoft Phi-4, coming soon
We also test the models internally for integration testing and to see how well they work for extraction.
Community Summaries
One way you can improve the richness of the graph representing your documents is by running graph algorithms to extract additional information hidden in the graph structure.
Microsoft did that last year with the “From local to global — Query Focused Summarization GraphRAG” paper. They used a hierarchical graph clustering algorithm (Leiden) on the extracted entity domain graph. This algorithm identifies clusters of closely related entities. An LLM then summarizes their content into community summary nodes, which represent the information in that set of entities and relationships. Due to the hierarchical results, this can be done on multiple levels going from very fine-grained to the highest level.
A more detailed blog post on evaluation will be available later in the series.
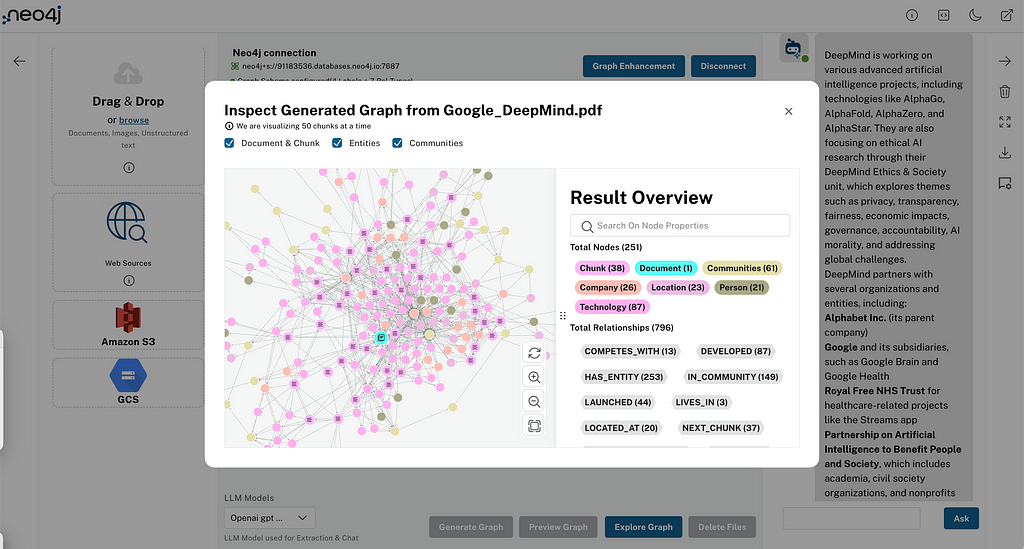
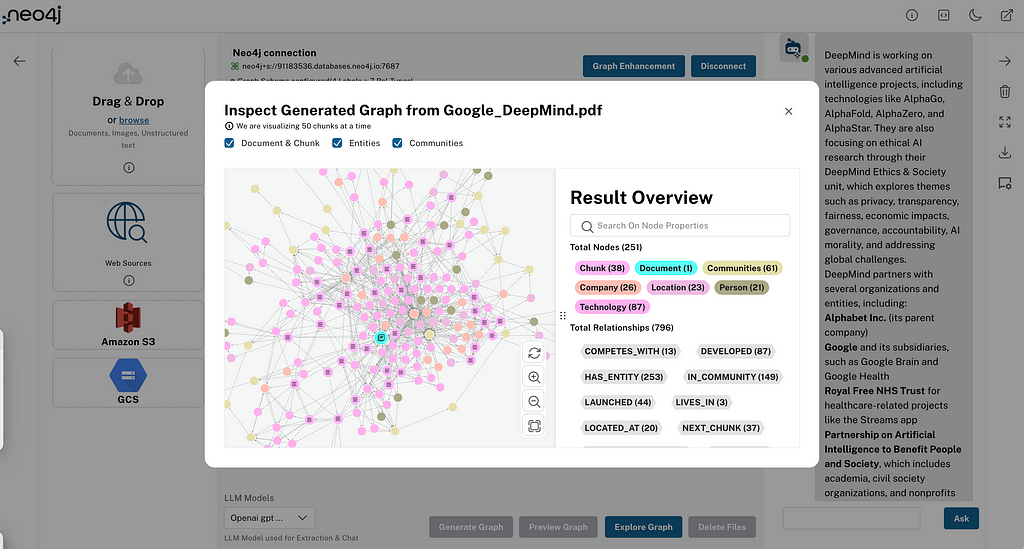
The extracted communities are visible in the graph visualization of your documents, so you can inspect them and their texts, and see which entities they are summarizing.
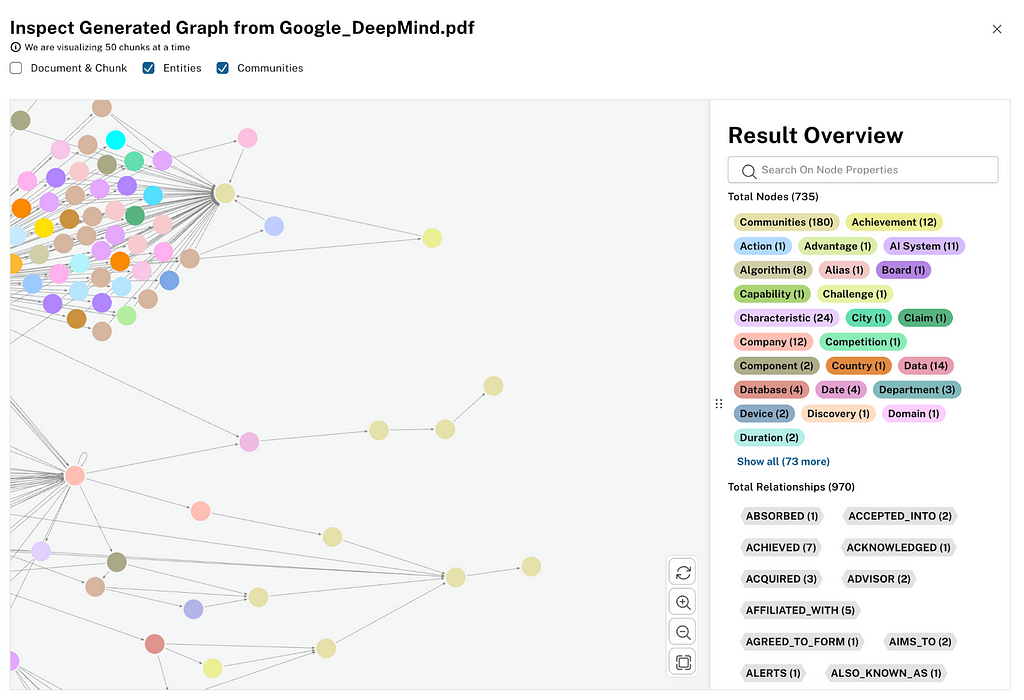
Those community summaries are then used in a global retriever to answer general questions about the documents, which aren’t specific to any one entity but identify topics across documents. So instead of the vertical sequence of content of each document, they represent themes spanning individual documents.
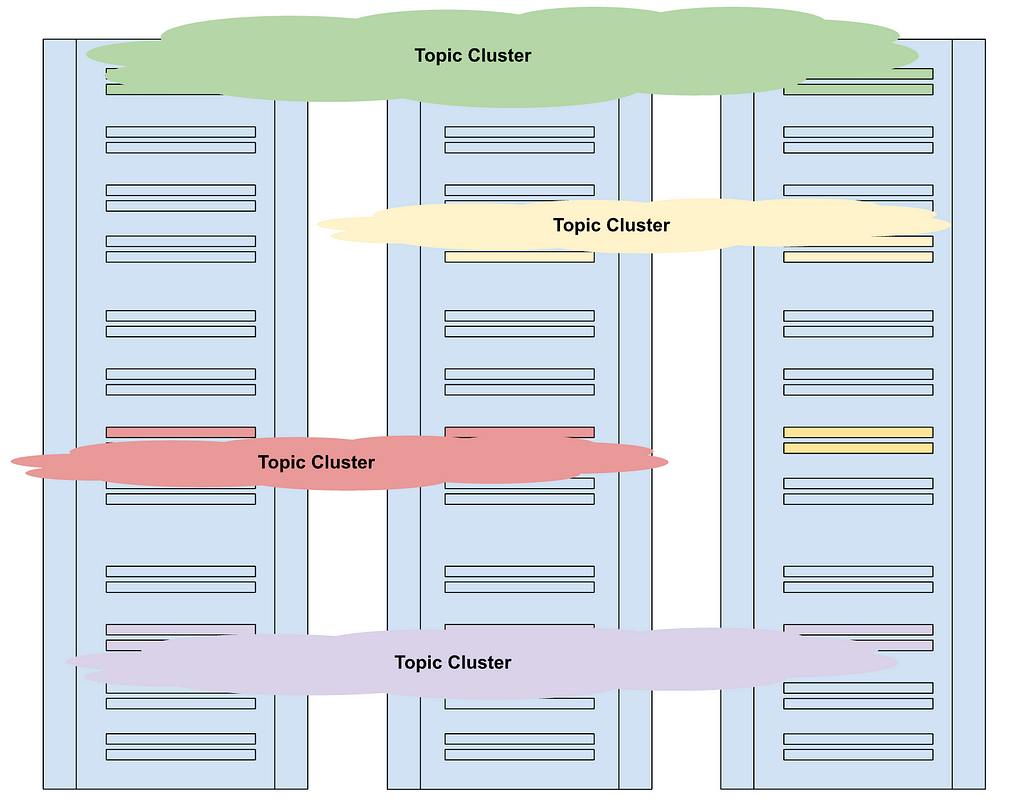
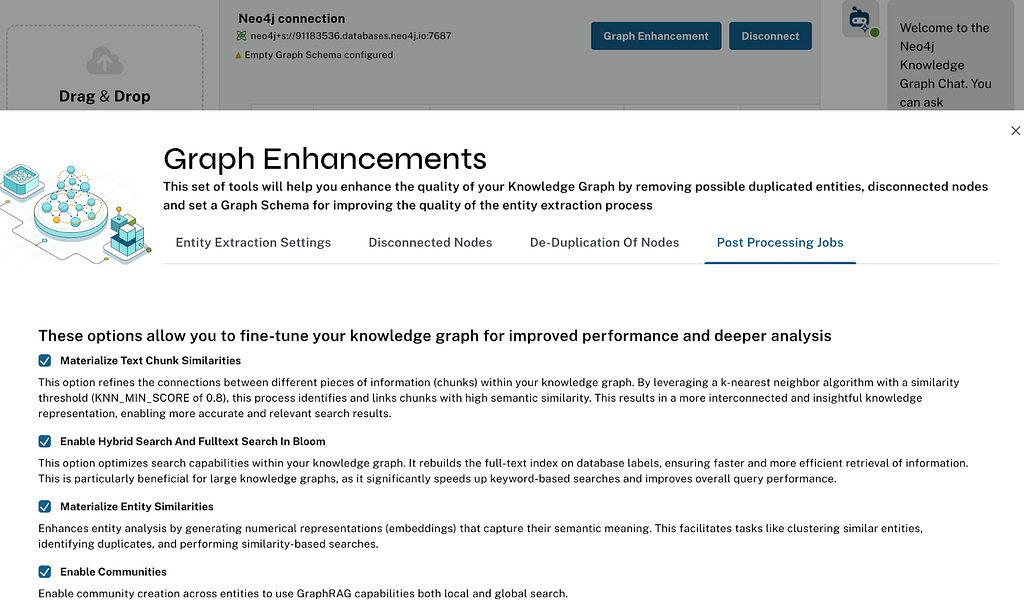
In LLM Knowledge Graph Builder, we implemented it using the same clustering algorithm, so if you run connect to a Neo4j instance that has graph data science enabled (AuraPro with GDS, AuraDS, Neo4j Sandbox, or self-hosted — which we show as ⚛ on top of the app), and enable the Community Summarization in the Graph Enhancements > Post Processing, we can run the algorithm and create the tree of summaries.
In our global community retriever, we took a slightly different approach from the paper, which just stuffs all the community summaries (of a certain level) into several LLM prompts to answer a question. We generate vector embeddings of the community summaries and use similarity and full-text search to find the most relevant ones for the question, which Microsoft Research recently also proposed, and use those to answer the questions.
Since we can now run multiple retrievers in parallel, you can see the difference for yourself. Check out the global and local entity retrievers comparison.

Both retrievers, like all the others, allow showing the retrieved contextual graph data (communities, entities, chunks) that went into generating the answer, supporting explainability.

Local Entity Retriever
The local entity retriever turns what is several thousand lines of Python code in the Microsoft paper implementation in about 50 lines of Cypher (one benefit of using an actual graph database), fetching the following:
- Entities with hybrid search (embedding and full-text)
- The relationships between them
- The most common relationships to entities outside the initial set
- The chunks and documents from where the entities were extracted
- The community summaries the entities are part of
// previous hybrid search on entities, then graph expansion
WITH collect(node) AS nodes,
avg(score) AS score,
collect({id: elementId(node), score: score}) AS metadata
RETURN score, nodes, metadata,
collect {
UNWIND nodes AS n
MATCH (n)<-[:HAS_ENTITY]->(c:Chunk)
WITH c, count(distinct n) AS freq
RETURN c
ORDER BY freq DESC
LIMIT 3
} AS chunks,
collect {
UNWIND nodes AS n
OPTIONAL MATCH (n)-[:IN_COMMUNITY]->(c:__Community__)
WITH c, c.community_rank AS rank, c.weight AS weight
RETURN c
ORDER BY rank, weight DESC
LIMIT 3
} AS communities,
collect {
UNWIND nodes AS n
UNWIND nodes AS m
MATCH (n)-[r]->(m)
RETURN DISTINCT r
} AS rels,
collect {
UNWIND nodes AS n
MATCH path = (n)-[r]-(m:__Entity__)
WHERE NOT m IN nodes
WITH m, collect(distinct r) AS rels, count(*) AS freq
ORDER BY freq DESC
LIMIT 10
WITH collect(m) AS outsideNodes, apoc.coll.flatten(collect(rels)) AS rels
RETURN { nodes: outsideNodes, rels: rels }
} AS outside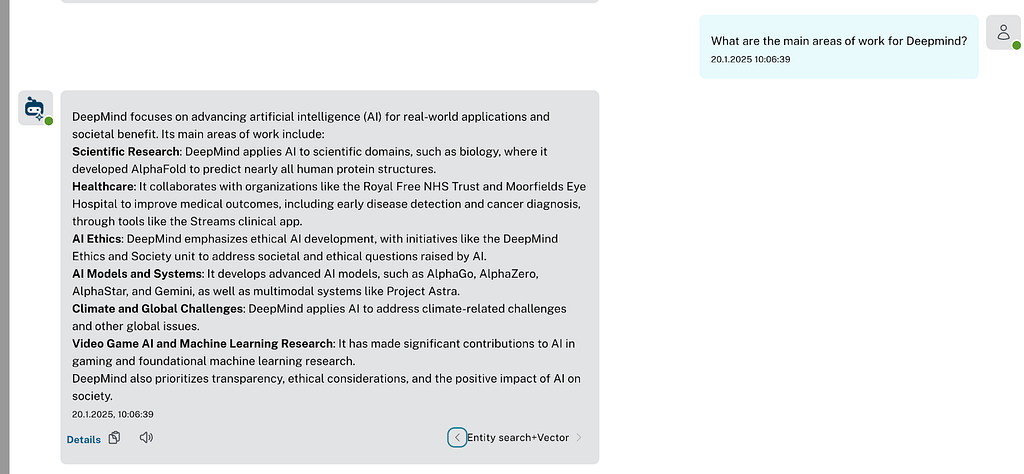
For the entity retriever, we can show not only text chunks but also the entities and their retrieved relationships.

Multi-Retrievers
As shown in the previous section, you can now select one or more retrievers run in parallel to generate an answer to your question and switch between the answer results directly to compare.

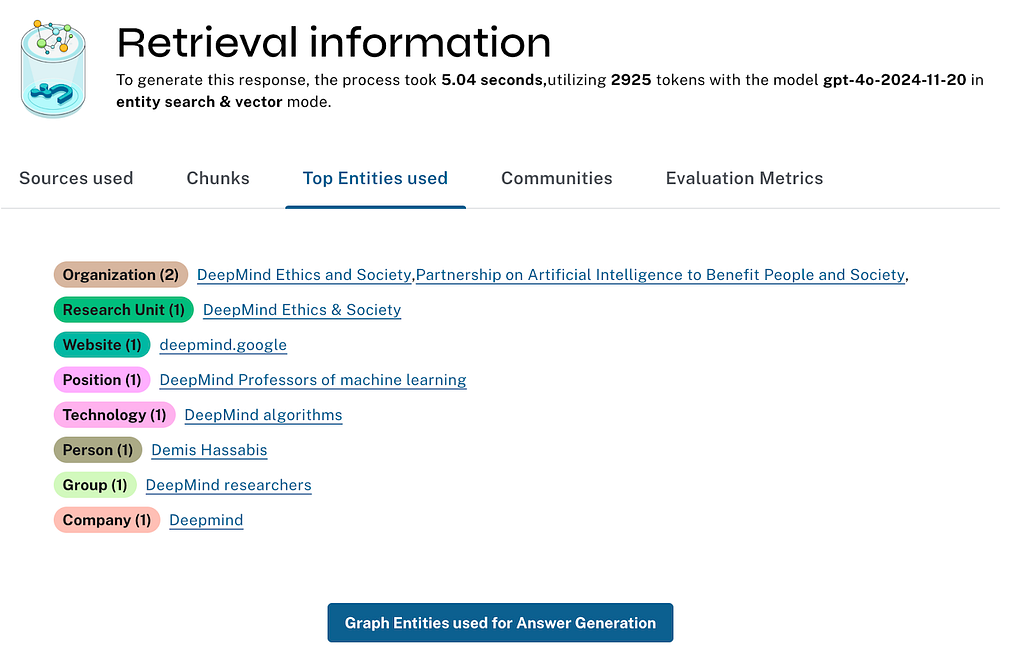
In the Details link after each answer, the retriever also provides the contextual facts retrieved from the database, which are then sent to the LLM, as well as additional information about the model, runtime, and token counts.
In development mode or for self-hosted, even more retrievers are available for you to test and compare.
To make this easier, the narrow right conversation sidebar can be maximized and even popped out into a full frame, which even becomes shareable. This is especially useful with read-only database connection setups, which we now also support for sharing your generated knowledge graph.
The underlying data of your conversation can be downloaded as a JSON file, so you can process it according to your own needs.
Retriever Evaluation
One reason for the parallel retriever evaluation was adding the ability to generate evaluation metrics.
We are using the RAGAs framework to run the evaluation. Currently, we compute the following metrics, some of which you need to provide a ground truth for:
- Relevancy — How well the answer addresses the user’s question
- Faithfulness — How accurately the answer reflects the provided information
- Context relevance — Determines the recall of entities present in generated answer and retrieved contexts
- Semantic relevance — How well the generated answer understands the meaning of the reference answer
- ROUGE — Similarity to ground-truth answer word by word
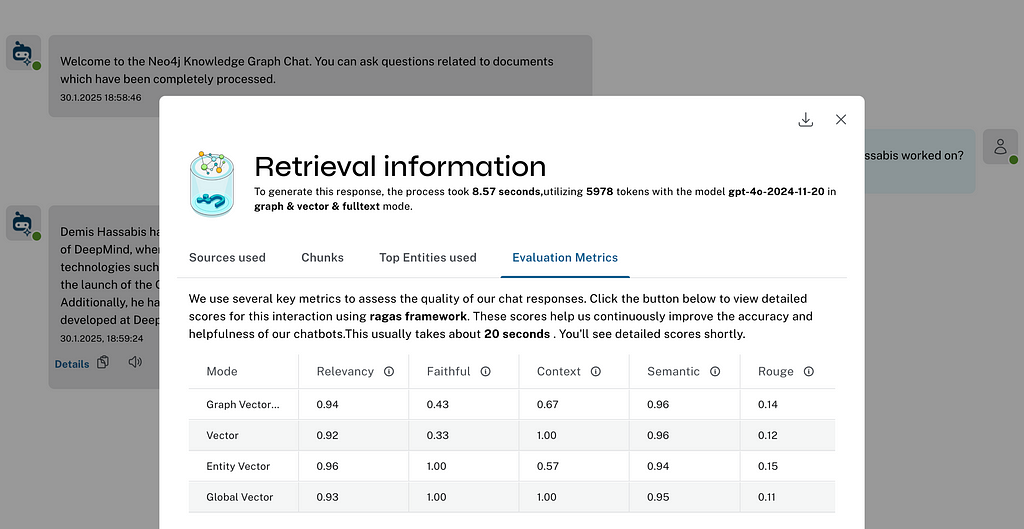
There will be a more detailed blog post on evaluation later in the series.
Guided Instructions for Extraction
In the latest version, we added the ability to guide the extraction more by allowing users to pass additional prompts to the LLM for extracting entities. So you can force it to only focus on certain parts of the document, on certain themes, or use specific additional instructions.
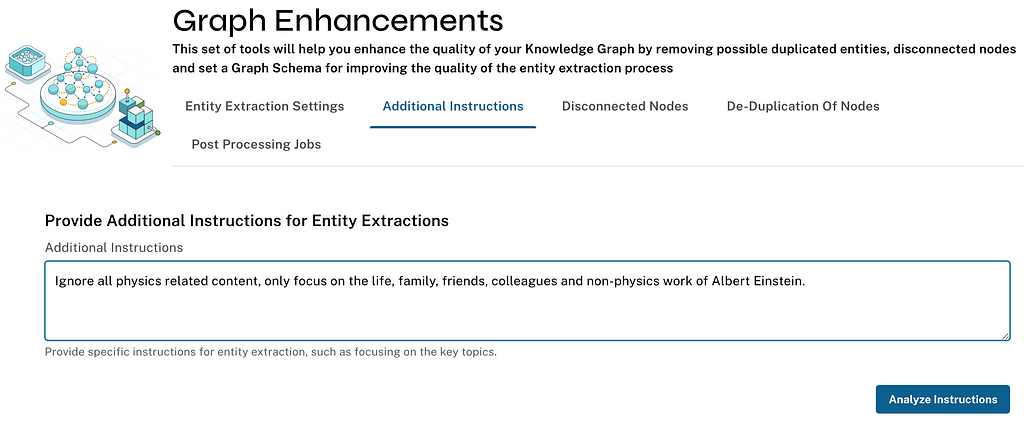
I tested it by extracting entities and relationships from several articles on Albert Einstein’s work but directing the LLM not to extract anything related to his physics work. And there it was — life, people, awards, peace activities, and other inventions, but not much on his tremendous contributions in physics.
User Experience Improvements
A quick list of the improvements:
- Allow read-only database access, then only retrieval is possible
- Pop out the chat experience into a separate window
- Improve graph visualization with local search and highlighting
Graph Consolidation
An experimental feature is automatic graph consolidation, intended for users who just quickly want to see an extracted knowledge graph from their data but don’t want to specify a graph schema upfront.
In those cases, the LLM often generates a load of entity types and relationships — counting into the thousands if you give it free rein. Our retrievers don’t mind because they use the graph topology, not the actual type, to traverse the graph (although they collect them together with the textual information).
That’s why we recommend providing a graph schema upfront for a more semantically constrained knowledge graph. But in cases where this didn’t happen, we can use an LLM to categorize a sorted list of node labels and relationship types into a smaller, more general set. Since we’re not 100-percent happy with the reduction, we didn’t enable it by default, but we would love your feedback. You can find it as one of the post-processing jobs in the graph enhancements.
Summary
Building an open source tool like this is a fulfilling experience — especially when we get as much feedback as we’ve gotten so far. We’ve addressed more than 400 GitHub issues, including internal planned tasks, and gotten more than 2,800 GitHub stars.
If you haven’t yet, please try it out and let us know what you think in the comments. We’d also be excited if you wrote about your experiences using the tool for different sets of documents of different domains.
Please share if you have questions or feedback. Also, please give us a star if you like the project.
Happy building!
LLM Knowledge Graph Builder — First Release of 2025 was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
The Developer’s Guide to GraphRAG
Combine a knowledge graph with RAG to build a contextual, explainable GenAI app. Get started by learning the three main patterns.
Share Article



Explore
Related Articles

