RAG tutorial: How to build a RAG system on a knowledge graph

Graph ML and GenAI Research, Neo4j
18 min read

Building a retrieval-augmented generation (RAG application for your LLM doesn’t have to be hard, especially when you follow the right steps. Whether you’re a developer exploring advanced GenAI workflows or an AI engineer seeking a better retrieval system for handling structured and unstructured data, this RAG tutorial is your go-to guide.
In this walkthrough, you’ll learn how to build a RAG app using knowledge graphs and vector search, combining the best of both structured and semantic retrieval. We’ll explain the basic RAG process, explore how knowledge graphs can supercharge your results, and show you how to implement a real-world example using Neo4j and LangChain.
Along the way, you’ll also learn about GraphRAG, a RAG implementation on a graph database. GraphRAG is a structured, explainable, and scalable upgrade from traditional RAG workflows.
This tutorial covers everything you need to know to get started, including:
- The major components of a typical RAG architecture
- A step-by-step guide to implementing RAG with a knowledge graph
- Code snippets you can use immediately
- Guidance on best practices and common pitfalls when building a RAG app
More in this guide:
What is retrieval-augmented generation (RAG)?
Before we dive into implementation, let’s clarify what a RAG system actually is — and why it’s become one of the most popular strategies for making large language models (LLMs) more accurate, transparent, and context-aware.
This section lays the foundation for the rest of the RAG tutorial. Vector databases, orchestration frameworks like LangChain, and graph-based techniques such as GraphRAG all rely on these same fundamentals to work effectively together.
What is the basic RAG process?
Retrieval-augmented generation is a technique that enhances Large Language Model (LLM) responses by retrieving source information from external data stores to augment generated responses.
This retrieval augmented generation (RAG) workflow involves three key stages: understanding queries, retrieving information, and generating responses. These steps remain consistent across use cases, from building a basic RAG app to scaling into a production-ready pipeline.
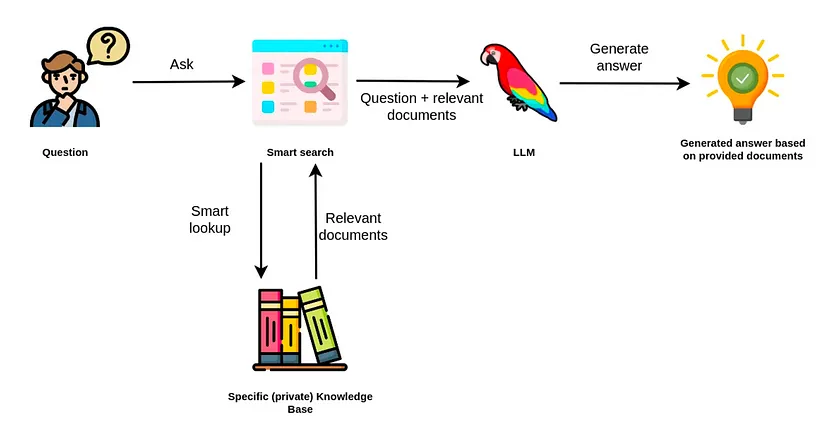
- Retrieval: The retrieval system uses embedding models to retrieve relevant information from external sources — such as documents, wikis, task systems, or databases — based on a user’s query. The retrieval process often uses semantic similarity (via vector search) or structured filtering to identify the most pertinent content. The system ranks and scores these results for relevance.
- Augmentation: The system combines the retrieved data with the original user input to form a richer prompt. This is called an augmented prompt. It can include multiple document chunks, metadata, and task-specific instructions — all aimed at grounding the LLM’s response in accurate, real-world information.
- Generation: In the final phase, the augmented prompt generates a response based on the retrieved context. A well-structured RAG pipeline can also include metadata, citations, or source traceability to increase user trust.
Why does RAG work?
LLMs like GPT-4 are powerful, but they’re only as good as their training data, which is static and limited. Retrieval augmented generation helps you move beyond those limitations by letting your model:
- Access real-time or domain-specific content
- Ground answers in verifiable, structured knowledge
- Reduce hallucinations and improve factual accuracy
- Adapt quickly to new datasets without retraining the model
By retrieving relevant external context at query time, RAG enables the model to generate responses that are both more current and better aligned with the specifics of your domain or context. Instead of relying solely on what the model “knows” (i.e., the training data), RAG supplements its outputs with grounded, purpose-fit information, which makes it especially valuable for high-stakes or dynamic use cases.
Core components of a RAG system
To build a RAG LLM application, you need a retrieval system, embedding models, and a generation pipeline. Here’s what the typical RAG architecture looks like:
- User Query: A user submits a natural language question (e.g., “What’s the status of the new billing system rollout?”).
- Embedding & Vector Search: The query is transformed into an embedding using embedding models, which allow the retrieval system to compare queries against precomputed document vectors. The retrieval system then compares it against precomputed embeddings stored in a vector database to find the most relevant matches.
- Document Retrieval: The system returns the top-k most relevant chunks of content based on vector similarity (usually cosine similarity).
- Prompt Construction: These documents are stitched together with the original query to create an augmented prompt. This prompt may use techniques like “stuff,” “map-reduce,” or “refine.”
- LLM Response Generation: The prompt is passed to an LLM (e.g., GPT-4 or Claude), which generates a grounded, context-aware response.
What is the best way to implement RAG?
Now that you understand the basic RAG process, you might be wondering how you can make it even better. A stronger RAG system doesn’t just retrieve relevant information; it integrates structured data, embedding models, and retrieval system logic to deliver more accurate, explainable, and scalable results.
Most RAG systems today use a vector database as the grounding data source. A vector database can work well for retrieving chunks of unstructured text, like help articles, emails, documentation, and PDFs. But when you want to add data that’s strewn across documents, or has structured elements, the GraphRAG approach is the best way to strengthen a RAG pipeline.
By combining vector search with a knowledge graph, your retrieval system can capture both semantic meaning and structured relationships, making retrieval augmented generation RAG far more accurate and trustworthy.
Introducing GraphRAG
GraphRAG is a graph-enhanced approach to RAG that integrates:
- Vector search (for semantic similarity)
- Graph search (for relational and structured queries)
- A unified retriever-agent framework using LangChain and other LLM tools
Note: While GraphRAG uses LangChain for orchestration, it is not a LangChain feature. It’s an architectural pattern designed around Neo4j’s graph database that brings together structured graph reasoning and unstructured text retrieval, enabling LLMs to generate more accurate and explainable responses.
Unlike vector-only RAG, this hybrid design provides both semantic understanding (via vector similarity) and symbolic reasoning (via knowledge graphs). The result is a retrieval system that is more accurate, explainable, and scalable—yet just as easy to implement as traditional vector-only pipelines.
GraphRAG architecture overview
Let’s take a look at what the GraphRAG architecture looks like:
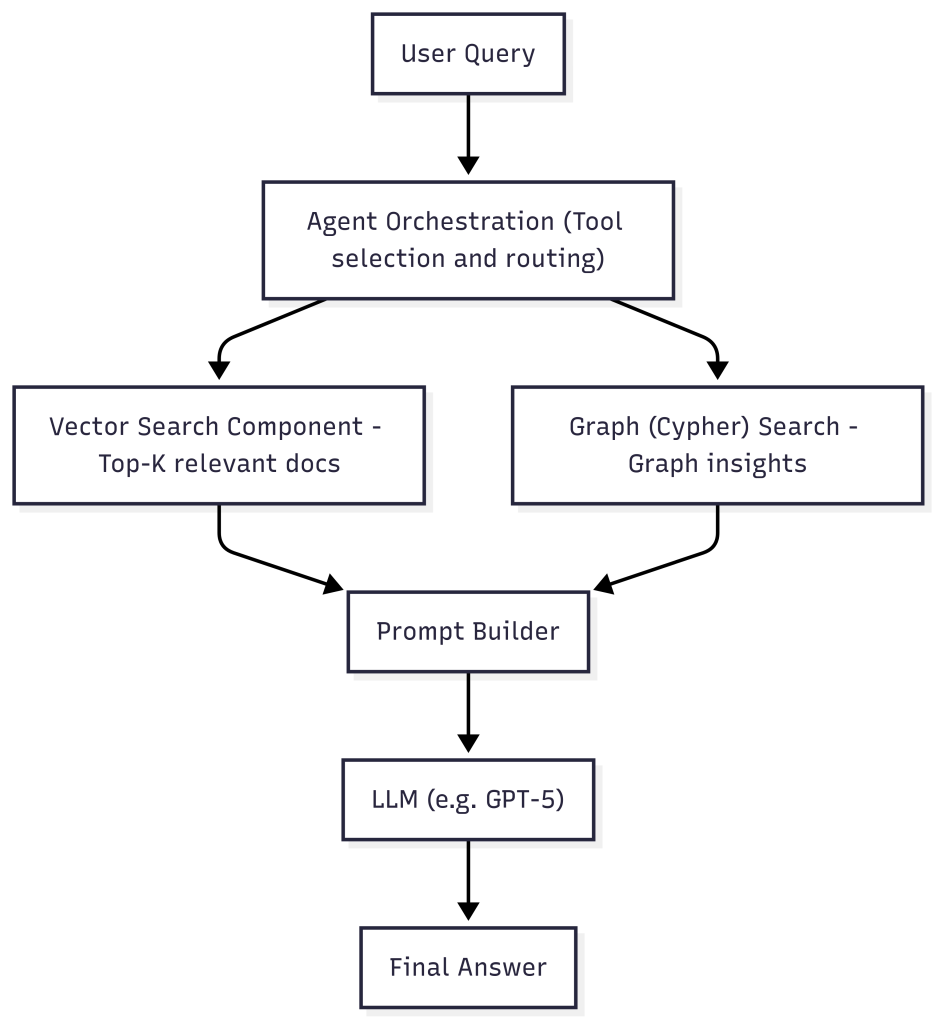
This combination of a knowledge graph and vector search is particularly effective when your application requires:
- Reasoning over complex architectures (e.g., microservices, IT assets, workflows)
- Querying both structured metadata and unstructured documentation
- Combining multiple sources into one coherent system
Why Go beyond vector-only RAG?
Vector search excels at finding semantically similar content, but it struggles with:
- Aggregation: e.g., “How many unresolved tickets are assigned to Team A?”
- Explainability: It’s difficult to trace why a particular document was retrieved.
- Fine-grained control: All retrieval is based on nearest-neighbor matching, with little room for business logic or reasoning.
Beyond vector search, knowledge graphs bring additional strengths that make your data GenAI-ready:
- Store data as nodes and relationships, not text blobs
- Support structured queries using Cypher or SPARQL
- Combine structured and unstructured data in one system
- Provide explainability: you can follow the relationships that support an answer
Think of it this way: A vector database is like a “semantic search engine” — great at finding passages that sound similar to your question, but not always great at showing how things are connected.
A knowledge graph, by contrast, is like a semantic map: it doesn’t just tell you what’s relevant, it shows you how concepts, entities, and data points relate to one another. That means you can ask complex questions like “Which services are at risk if X fails?” or “Who owns all unresolved tickets in Region A?” and get grounded, structured answers with explainable paths.
Many baseline RAG systems rely solely on vector search over text embeddings for information retrieval. To capture the semantic meaning of content, source documents are often chunked into fragments and embedded. However, this can lead to incomplete or fragmented answers. For example, if a user asks a question about a specific product feature, a vector-only RAG system might retrieve chunks that mention the product but miss crucial supporting details from elsewhere in the documentation.
Due to the black-box nature of vector similarity, these systems often lack transparency — developers and users can’t always see why something was retrieved or how it contributes to the generated answer. This is especially problematic in regulated environments like finance, healthcare, or legal, where traceability and accuracy matter most.
GraphRAG addresses these limitations by incorporating structured domain knowledge. By tapping into the semantic relationships inside a knowledge graph, GraphRAG enhances retrieval accuracy, supports reasoning, and delivers more trustworthy results while still maintaining the flexibility of vector search.
The developer’s guide to GraphRAG
Combine a knowledge graph with RAG to build a contextual, explainable GenAI app. Get started by learning the three main patterns.
A step-by-step tutorial for implementing GraphRAG
Ready to build your own RAG application? In this hands-on tutorial, we’ll walk you through how to set up a working GraphRAG system using:
- Neo4j as the knowledge graph and vector store
- LangChain, an LLM application framework, to coordinate retrieval and generation steps
- OpenAI for embeddings and generative responses
Even if you’re new to Neo4j or knowledge graphs, don’t worry, we’ll keep things simple and practical. In this example, you’ll build a chatbot that can answer both unstructured and structured questions about a synthetic DevOps environment.
Prerequisites
Before we dive in, make sure you have:
- A Neo4j Aura instance or Neo4j Desktop running (version 5.11+)
- An OpenAI API key
- Python installed (with
langchain,neo4j,openai, etc.)
Neo4j environment setup
First, you’ll need to set up a Neo4j 5.11 instance or greater to follow along with the examples. The easiest way is to start a free cloud instance of the Neo4j database on Neo4j Aura. Or, you can set up a local instance of the Neo4j database by downloading the Neo4j Desktop application and creating a local database instance.
from langchain_neo4j import Neo4jGraph
url = "neo4j+s://databases.neo4j.io"
username = "neo4j"
password = ""
graph = Neo4jGraph(
url=url,
username=username,
password=password
)
Preparing the dataset
Knowledge graphs excel at connecting information from multiple data sources. When developing a DevOps RAG application, you can fetch information from cloud services, task management tools, and more.
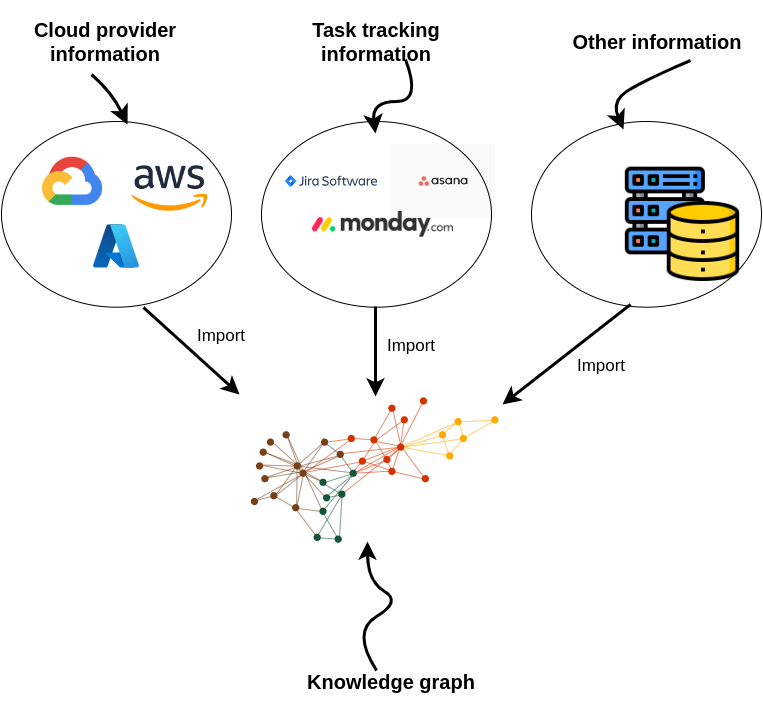
Since this kind of microservice and task information is not public, we created a synthetic dataset with ChatGPT. It’s a small dataset with only 100 nodes, but that’s a big enough sample for this tutorial. Use this code to import the sample graph into Neo4j:
import requests
url = “https”gist.githubusercontent.com/tomasonjo/08dc8ba0e19d592c4c3cde40dd6abcc3/raw/da88822
import_query = requests.get(url).json()[query’]
graph.query(
import_query
)
You should see a similar visualization of the graph in the Neo4j Browser:
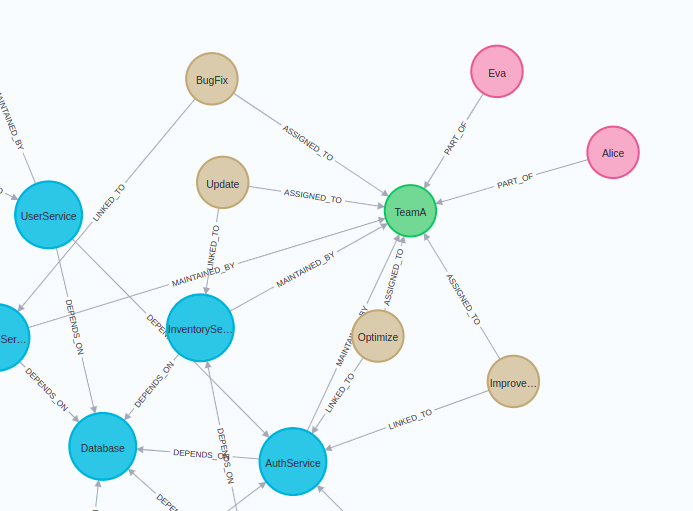
Blue nodes describe microservices. These microservices may have dependencies on one another. The relationships show that one microservice’s ability to function or provide an outcome may be reliant on another’s operation.
The brown nodes represent tasks that directly link to these microservices. This visualization of the graph shows how microservices are set up, how their tasks depend on one another, and the teams associated with each.
Neo4j vector index
We’ll begin by implementing a vector index search to find relevant tasks by their name and description. If you’re unfamiliar with vector similarity search, here’s a quick refresher. The key idea is to calculate the text embedding values for each task based on its description and name. Then, at query time, find the most similar tasks to the user input using a similarity metric like cosine distance.
The information retrieved from the vector index can then be used as context for the LLM so it can generate accurate, up-to-date answers.
The tasks are already stored in our knowledge graph, but we still need to calculate their embeddings and build a vector index. We’ll do this using the from_existing_graph method:
os.environ[‘OPENAI_API_KEY’] = “OPEN_API_KEY”
vector_index = Neo4jVector.from_existing_graph(
OPENAIEmbeddings(),
url=url,
username=password,
index_name=’tasks’,
node_label=”Task”,
text_node_properties=[‘name’, ‘description’, ‘status’],
embedding_node_property= ‘embedding’,
)
In this example, we used the following graph-specific parameters for the from_existing_graph method.
index_name: name of the vector index.node_label: node label of relevant nodes.text_node_properties: properties to be used to calculate embeddings and retrieve from the vector index.embedding_node_property: Which property to store the embedding values in.
Now that the vector index is initiated, we can use it like any other vector index in LangChain:
respond=vector_index.similarity_search(
“How will RecommendationService be updated?”
)
print(response[0].page_content)
# name: BugFix
# description: Add a new feature to RecommendationService to provide …
# status: In Progress
You’ll see that we construct a response of a map or dictionary-like string with defined properties in the text_node_properties parameter.
Now we can easily create a chatbot response by wrapping the vector index into a RetrievalQA module:
vector_qu = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
chain_type=”stuff”,
retriever=vector_index.as_retriever()
)
vector.qa.run(
“How will recommendation service be updated?”
)
# The RecommendationService is currently being updated to include a new feature
# that will provide more personalized and accurate product recommendations to
# users. This update involves leveraging user behavior and preference data to
# enhance the recommendation algorithm. The status of this update is currently
# in progress.
A limitation of vector indexes is that they can’t aggregate information like you can with a structured query language like Cypher. Consider this example:
vector_qa.run(
“How many open tickets are there?”
)
# There are 4 open tickets.
The response seems valid, in part because the LLM uses assertive language. Yet, the response directly correlates to the number of retrieved documents from the vector index, which is four by default. When the vector index retrieves four open tickets, the LLM concludes there are no additional open tickets. You can then validate this result with a Cypher statement.
graph.query(
“MATCH (t:Task {status: ‘Open’}) RETURN count (*)”
)
# [{‘count(*)*: 5}]
Our toy graph has five open tasks. Vector similarity search works well for sifting through relevant information in unstructured text, yet it struggles with analyzing and aggregating structured information. Using Neo4j, this problem is easily solved with Cypher, a structured query language for graph databases.
Graph Cypher search
Cypher is a structured query language designed to interact with graph databases. It offers a visual way of matching patterns and relationships and relies on the following ASCII–art type of syntax:
(:Person {name: “Oskar”}]-[:LIVES_IN]->(:Country {name:"Slovenia"}]
This pattern describes a node with the label Person and the name property Oskar that has a LIVES_IN relationship with the Country node of Slovenia.
The neat thing about LangChain is that it provides a GraphCypherQAChain, which generates the Cypher queries for you, so you don’t have to learn Cypher syntax to retrieve information from a graph database like Neo4j.
The following code will refresh the graph schema and instantiate the Cypher chain.
from langchain.chains import GraphCypherQAChain
graph. refresh_schema()
cypher_chain = GraphCypherQAchain.from_llm(
cypher_llm = ChatOpenAI(temperature=0, model_name= ‘gpt-4’),
qa_llm = ChatOpenAI(temperature=0), graph=graph, verbose=True,
)
Cypher generation isn’t trivial, so we recommend using GPT-4 to handle the queries and leaning on GPT-3.5-Turbo to generate the final answers.
Now, you can ask the same question about the number of open tickets.
cypher_chain.run(
“How many open tickets there are?”
)
The result is the following:

You can also ask the chain to aggregate the data using various grouping keys:
cypher_chain.run(
“Which team has the most open tasks?”
)
The result is the following:

You might say these aggregations are not graph-based operations, and that’s correct. We can, of course, perform more graph-based operations like traversing the dependency graph of microservices.
cypher_chain.run(
“Which services depend on Database directly?”
)
The result is the following:

Of course, you can also ask the chain to produce variable-length path traversals by asking questions like:
cypher_chain.run(
“Which services depend on Database indirectly?”
)
The result is the following:

The overlap in mentioned services comes from the structure of the dependency graph, not from an invalid Cypher statement.
Challenges and best practices of building a RAG application
Even though RAG systems are powerful, you might run into problems as you build them in the real world. Below, we break down some of the most common issues you’ll face, along with expert tips and best practices to overcome them.
This usually happens when the retrieved context doesn’t fully answer the user’s question, or when the LLM prioritizes fluency over factuality.
Best Practices:
• Improve retrieval quality: Optimize embedding models and retrieval system logic to retrieve relevant information more consistently. Refine chunking strategies (e.g., overlap chunks, adjust window sizes) as part of this process.
• Score & filter context: Use metadata or ranking heuristics to ensure only the most relevant chunks are passed to the LLM.
• Use GraphRAG: Structured graph queries (e.g., via Cypher) allow exact answers when vector search falls short.
This often happens when embeddings fail to capture the true meaning of your query or documents. That can result from generic embeddings, noisy source text, or missing filters during retrieval.
Best Practices:
• Use domain-specific embeddings: OpenAI, Cohere, or even fine-tuned models, depending on your context.
• Pre-clean your text: Remove boilerplate, headers, and navigation content from source documents.
• Use node-level filters in Neo4j: For example, restrict to Task nodes with a certain status.
Most basic RAG systems only support unstructured data via vector search. If you want to ask questions like “How many tasks are open?” or “Which services depend on X?”, you’ll need structure.
Best Practices:
• Use a knowledge graph with native vector search. In Neo4j, you can build a knowledge graph with vector search and can apply structured query tools.
• Use the LangChain-Neo4j package for structured questions and vector search for semantic ones.
• Wrap both in an agent: This lets the system choose the best retrieval method based on the question type.
This is where tool routing comes into play. LangChain supports agents that can decide which retriever to invoke.
Best Practices:
• Describe each tool clearly in the agent’s Tool(s) definitions.
• Use descriptive prompts in your agent to nudge it toward the right tool.
• Fine-tune or customize tool selection logic if necessary.
Many vector search libraries return a fixed number of top-k results, even when the semantic match is weak.
Best Practices:
• Increase k cautiously and filter based on the similarity threshold.
• Combine vector scores with business logic or metadata constraints.
• Complement with Cypher queries to validate or cross-reference results.
Since you’re working with both retrieval and generation, isolate problems by testing them separately.
Best Practices:
• Log all intermediate steps: query embeddings, retrieved docs, prompt construction, and final response.
• Use synthetic queries with known answers to validate retrieval.
• Ask your system, “Why did you say that?”This helps debug hallucinations and verify grounding.
Retrieval can be fast, but LLM calls (especially to GPT-4) can introduce lag.
Best Practices:
• Cache query results and embedding calculations
• Use lightweight models (like GPT-3.5) for retrieval and GPT-4 for final answers
• Consider batching or asynchronous calls when serving multiple users
These best practices help you build faster, more reliable RAG apps, whether for internal tools, chatbots, or enterprise search.
The future of RAG is structured
As you move from experiments to production, you’ll find that retrieval is what makes LLMs scalable, adaptable, and trustworthy.
If you want RAG systems that are:
- Accurate and grounded in real data
- Flexible across use cases
- Transparent and explainable
- Future-proof for enterprise scale
…then adding structure—via a knowledge graph—is the next logical step.
GraphRAG represents the evolution of retrieval-augmented generation RAG, which makes retrieval systems more accurate by combining semantic vector search with structured graph reasoning. It is emerging as a powerful next step in retrieval-augmented generation, combining structured and unstructured data to improve reasoning, retrieval precision, and response quality.
The question isn’t just how to build a RAG system. It’s how to build one that actually works for your business logic, your users, and your data reality.
With tools like Neo4j, LangChain, and OpenAI, you can balance flexibility with performance instead of trading one for the other.
Ready to build your own GraphRAG app?
Start with the tutorial above and try running your own questions through the DevOps example. From there, plug in your own data — support tickets, product specs, sales content, or workflows — and see what a smarter RAG system can unlock.
Essential GraphRAG
Unlock the full potential of RAG with knowledge graphs. Get the definitive guide from Manning, free for a limited time.

How to build a knowledge graph
Learn the basics of graph data modeling, how to query, and top use cases that use highly interconnected data.
Additional resources
To deepen your understanding or get hands-on with other aspects of RAG and knowledge graphs, check out the following:
Share Article



Explore
Related Articles




1 of 3: The difference between a graph, a knowledge graph, and a context graph

2 of 3: Why graphs, knowledge graphs, and context graphs matter to customers
