Let’s write a stored procedure in Neo4j – Part I

Consulting Engineer, PS
18 min read


I am frequently asked by Neo4j customers how to improve query performance on large graphs.
Achieving good performance depends on:
- An effective model for the data
- Efficiently designed queries
The Neo4j Java API
Neo4j offers two main ways of querying a graph – through the Cypher query language and via a Java API. A solid model and well-designed Cypher query is sufficient in the majority of cases, but for those cases where we want the finest level of control, the Java API provides a powerful and intuitive interface.
Sometimes, even here at Neo4j, people get the sense that writing a Stored Procedure is some arcane process that must be executed by an engineering wizard or super-coder.
Well, I am here to show you that this is hardly the case!
We will work through a simple, yet powerful example and you will see that there’s not much more to it than any other Java program. The Java API has been around longer than Cypher; it was the original Neo4j query interface (well before my time…) When I was learning about graph databases, I found the imperative constructs of the Java API more familiar and easier to grasp than the declarative format of Cypher. I suspect this is true for other experienced programmers new to graph technology.
The Java API is great but let me make a couple disclaimers:
- If you can get good results with Cypher queries, it is usually better to design your application that way. There are a few reasons for this but a compelling one is that Stored Procedures are compiled and require a database restart if they are modified. Thus, Cypher queries have an advantage in portability and flexibility.
-
The Java API can’t save you from a bad model. You may be able to get some results faster, but for an effective graph application you need an efficient model. The design must consider the model and query framework in conjunction to be successful.
An example stored procedure
Okay, now that that is out of the way, let’s start banging out some code!
Journey/event models
We’re going to look at a problem that graph databases are terrific at, but that requires the Java API to truly perform at scale. I’m talking about the “Patient Journey” use case which I wrote about here.
An individual’s interactions with some larger domain are represented as sequential events connected to each other. In the linked example, the individuals are patients and the events are their interactions with the medical domain (prescriptions, operations, doctor visits, etc).
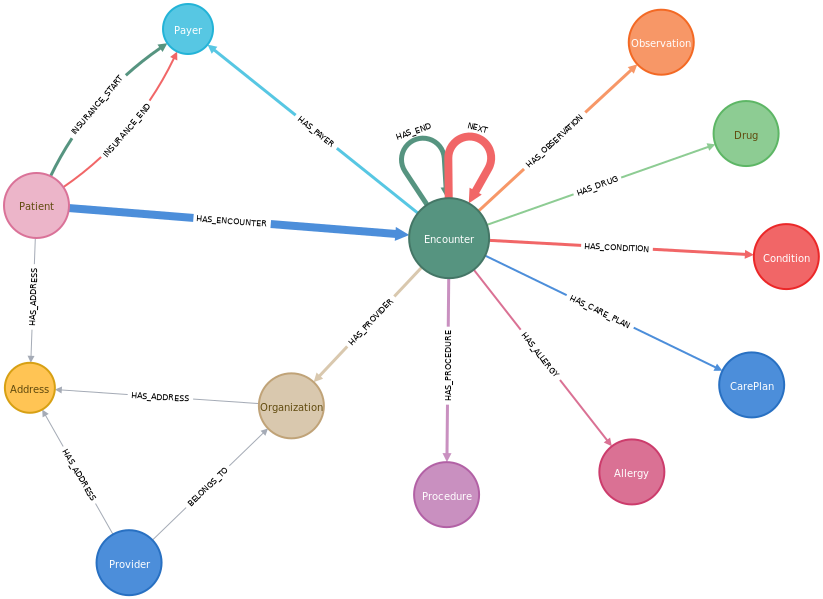
Another example would be a “customer journey&rdquo,; where the individuals are shoppers and the events are things like purchases, returns and so on.
The model allows us to observe behaviors across large populations without losing the context of the actions of an individual. Even as the number of individual events climbs into the billions, we don’t need to resort to sampling or summarizing results.
The Java API is key here as it gives us the ability to narrow in on the individual’s event path, retaining the bare minimum of information needed to answer the question.
A simplified patient journey model
For the purposes of this demonstration, we will be looking at a considerably simplified version of the Patient Journey model. This will let us focus on the basics of building a stored procedure without getting too bogged down in complexity.
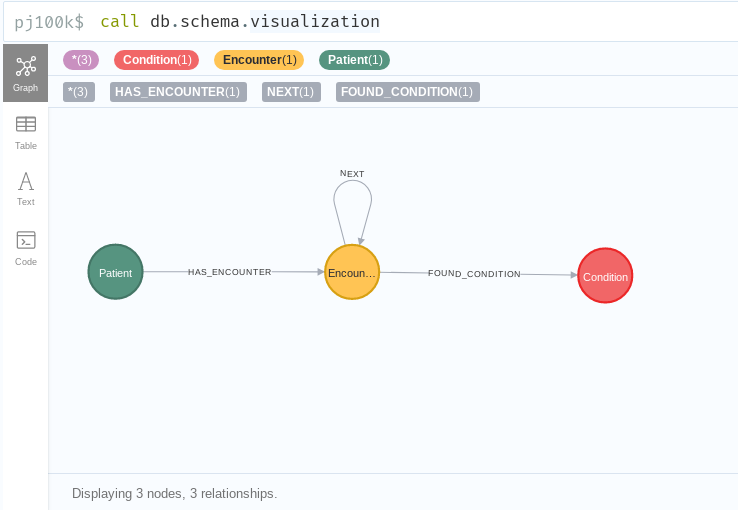
We’ve reduced our model to just three types of nodes and three types of relationship. We’ve eliminated any doctor or billing details and the only events we are recording are Conditions(i.e. diagnoses).
Moreover, we are no longer modeling a start and end of an Encounter; we are treating it as a single moment in time. However, we are still representing a patient journey that reflects events in sequential order. That is enough to build the foundation of a journey traversal procedure.
To follow along, you can create a sample graph using the program here.
The program generates 100,000 simulated Patients with Conditions using Synthea and transforms the data so that it can be loaded into Neo4j using the neo4j-admin import utility.
Designing a stored procedure
The stored procedure we are building will show us patterns that occur after a Patient is diagnosed with a particular Condition. The user of the procedure will provide two input parameters:
- the id of the
Condition - the number of subsequent
Conditions
We will aggregate on the patterns so that we can see which occur most frequently. The output will be:
- the pattern — a list of subsequent
Conditions - the number of times the pattern occurred
Here’s an example invocation of the procedure we will build:
CALL org.mholford.neo4j.findJourneys('55822004', 3)
YIELD path,count
RETURN path, count
ORDER BY count DESC LIMIT 10
The query asks for the most common patterns of three subsequent Conditions for patients diagnosed with hyperlipidemia (‘55822004’). (To avoid skewing the results, we will ignore patients with fewer than three subsequent Conditions.)
Before we start coding, let me say a few words about how Stored Procedures work in Neo4j.
Whereas in many relational databases there is some sort of procedural language that provides imperative, lower level control over database operations. Examples include Oracle’s PL-SQL and T-SQL for SQLServer.
In Neo4j, this is done directly in Java via the plugin architecture. While this gives us the convenience of programming in Java with all of its powerful tools, it necessitates a deployment step before our code can run.
We package our stored procedure code in a jar file which gets specially “compiled” so that it can run safely within Neo4j’s kernel. This process is conveniently automated via Maven and, as with Heidegger’s broken hammer, we only notice it when it’s not working.
Solution strategy
We should also lay out the steps of how our procedure will solve the problem of finding the most common patterns:
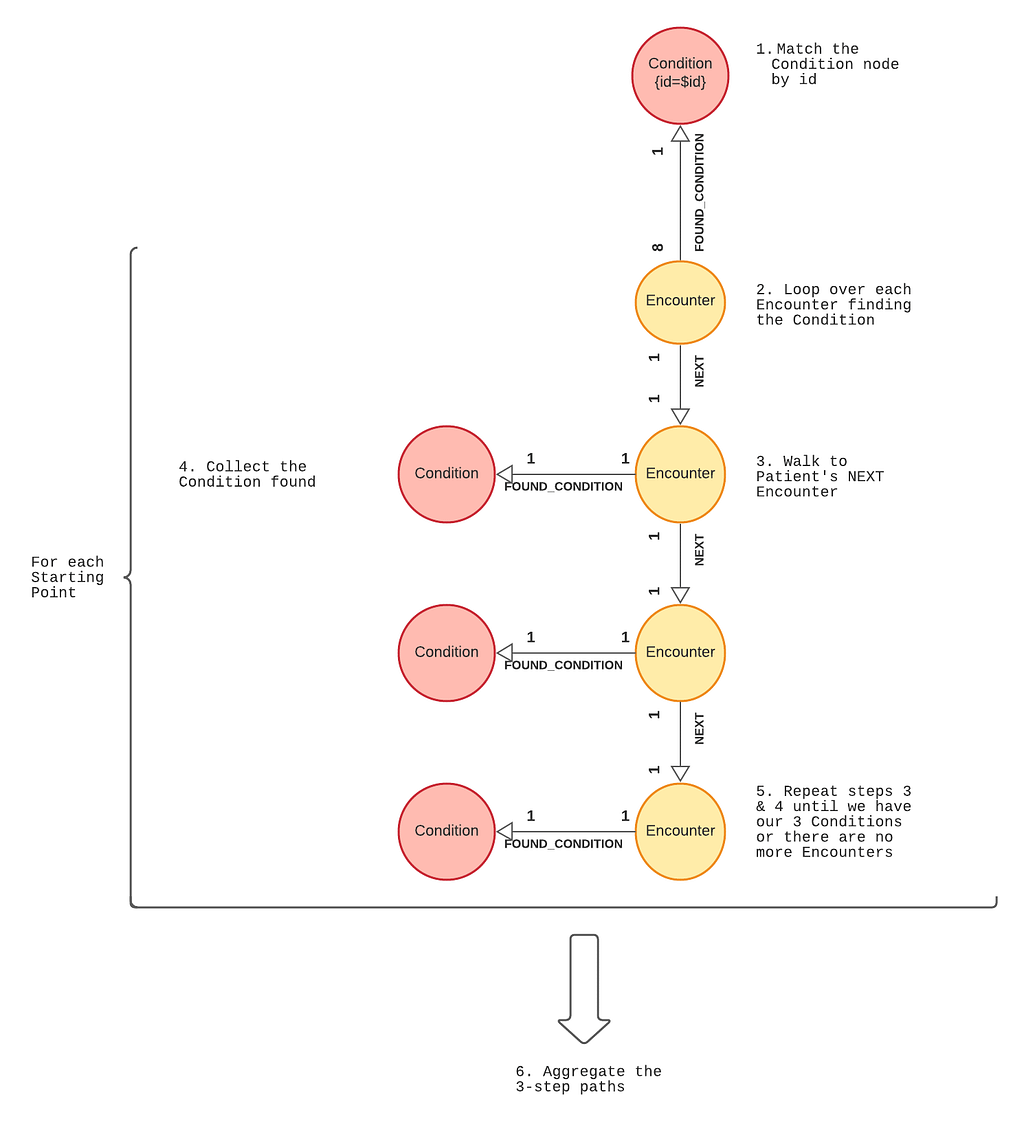
- We find the
Conditionnode by matching the specified startCondition against the index ofConditionnodes - We loop over all the
FOUND_CONDITIONrelationships that connect theConditionnode toEncounters -
For each
Encounter, we hop to the nextEncounterby walking theNEXTrelationship - We walk the
FOUND_CONDITIONrelationship to see whatConditionwas found for thisEncounter - We repeat steps 3 & 4 twice more to get 3 subsequent
Conditionsin all. If there aren’t 3 more, we exclude the result - We now have a list of 3-step paths which we can aggregate and get frequencies from
Building blocks — Maven
We can get started by either cloning the github project for this demo or by starting a new project from the pom.xml file. Here are a few highlights from the pom.
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j</artifactId>
<version>${neo4j.version}</version>
<scope>provided</scope>
</dependency>
This gets the main neo4j dependency.
Be sure to specify the provided scope – our plugin will be running within a Neo4j instance, so we don’t need to build a lot of those classes into our jar.
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>procedure-compiler</artifactId>
<version>${neo4j.version}</version>
<optional>true</optional>
</dependency>
This handles the procedure compilation I mentioned earlier. It’s flagged as optional but it’s convenient to include because it can flag certain problems with our procedure before we fully deploy it.
<dependency>
<groupId>org.neo4j.test</groupId>
<artifactId>neo4j-harness</artifactId>
<version>${neo4j.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>${neo4j-java-driver.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
Here are our testing dependencies. I’m using old-school JUnit 4 for this demo since it’s good enough for our purposes. Our tests will make use of the Neo4j test harness, an awe-inspiring piece of software that stands up a temporary in-memory instance of Neo4j we can test against. We will be issuing Cypher statements (to call the procedure) in our tests. So we need the Neo4j Java driver in our test scope.
(A quick note about ${neo4j.version} and ${neo4j-java-driver.version}. I would recommend using the latest stable version of each. At the time of writing this is 4.3.4. There were some changes in how Stored Procedures are handled between Neo4j 3.x and 4.x. I am presenting the current (4.x) methodology here.)
Here’s the fun part:
<build>
<pluginManagement>
<plugins>
<plugin>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</pluginManagement>
</build>
This stanza calls on Maven’s Shade plugin to create a “shaded” jar file which includes both our code and whatever non-provided/test dependencies we include. This jar (in a coarser age, we called it a “fat jar” or “uber jar”) gets copied into the plugins folder of our Neo4j installation. Upon restart of the server, our procedure will be available to the kernel so that we can run it via a Cypher call.
A Java stored procedure class
Now let’s start writing the class that will execute our Stored Procedure. In your new project, create a package (org.mholford.neo4j in our example; adjust as you like). In this package, create a class JourneyProcedure (actual name doesn’t matter). I’m going to step you through the code line-by-line. You can type as we go, or following along with the file from github. I will assume that you are familiar with Java concepts and have some coding experience.
public class JourneyProcedure {
@Context
public Transaction txn;
@Context
public Log log;
There are a couple things to notice here:
- First is the
@Contextannotation before our two fields. This means that the object gets passed (injected) in from the context of the executing Neo4j kernel.
At the time our procedure gets executed, a freshTransactionobject and a reference to the Neo4j log are made available to our procedure. TheTransactionobject is the implicit surrounding transaction that gets created around any Cypher call. (Remember that our Stored Procedure gets executed via Cypher).
It is possible to create, commit and rollback other transactions within a Stored Procedure; I will demonstrate this in a later blog. TheLogobject is a handle to Neo4j’s logging subsystem; it’s a wrapper aroundslf4jlogging library (part of the4jfamily… just kidding). There are a couple other@Contextobjects we’ll see in later blogs and it’s even possible to define your own. - The second thing is that these fields must have
publicaccess; otherwise the procedure compiler will fail. We do not need to supply a constructor for theJourneyProcedureclass; Java’s implicit no-arg constructor is sufficient.
Stored procedure signature and results
Moving on..
@Procedure(name="org.mholford.neo4j.findJourneys")
@Description("Finds the next numSteps of a patients journey after
the provided condition")
public Stream<JourneyResult> findJourneys(
@Name("startCondition") String condition,
@Name("numSteps") long numSteps) {
The @Procedure annotation is how the Neo4j kernel identifies the entry point for our Stored Procedure. When we say CALL org.mholford.neo4j.findJourneys , it finds this procedure and passes it the parameters provided. The @Name annotation lets us refer to these parameters by name when we’re calling the procedure. The @Description annotation is optional but it provides documentary metadata for Neo4j tools such as Browser.
Be sure to notice that we’re defining the datatype of numSteps as a long . Does that mean we’re expecting to support journeys with more than 2,147,483,647 steps?? Well, no; although theoretically we could… The reason is that Cypher has its own datatypes which govern how it represents data. As such, it defines only one integer type which corresponds to Java long(There are no short or inttypes). This page from our documentation explains Neo4j’s native types and how they correspond to Java primitives and classes.Our procedure returns a Stream of a custom data class objects (DTO) we are calling JourneyResult . This is another requirement of the procedure compiler. It must return a Stream of objects whose fields are of types that correspond directly with Cypher native types. Keep a bookmark for that page I linked above! We’ll see some other subtle gotchas with these later in the series. Here’s the definition of our JourneyResult class:
public class JourneyResult {
public long count;
public List<String> path;
public JourneyResult(List<String> path, long count) {
this.path = path;
this.count = count;
}
}
Our result has two fields: a list of Strings which represents the path of the journey (i.e. the 3 Conditions encountered) and the count of how many Patients had that journey. Note that here again we must use long as our integer type. Finally, note that the fields must have public access. “Encapsulation? What’s that?”, asks the Neo4j procedure compiler. (If, like me, you were taught to view public fields with suspicion, don’t worry. This requirement is just on the portions of code that interface directly with the procedure compiler. Within our program, we can encapsulate to our hearts’ content).
The first step
Alright, let’s start the journey:
var conditionNode = txn.findNode(Label.label(CONDITION_LBL),
ID_PROP, startCondition);
Here, we are using the Transaction object to find the node for our start Condition . We use constants for our string variables because it’s good practice. Those are defined earlier in the class:
private static String CONDITION_LBL = "Condition";
private static String ID_PROP = "id";
(Oh by the way, you can only define static fields or fields that are injected via @Context for the Stored Procedure class. This has to do with how the procedure compiler instantiates the class. The limitation does not hold for classes called by the Stored Procedure class. We’ll see examples of this later in the series.)
Traversing the graph
So now we have reached the first step- we have the node for the start Condition . I’ll parcel out the remaining tasks to helper functions to keep our procedure method compact and readable:
var journeys = getJourneysFrom(startNode, numSteps);
var journeyResults = collectPaths(journeys);
return journeyResults.stream();
The getJourneysFrom method will collect all journeys from the start Condition and return them as a list of list of strings. Then thecollectPaths method will aggregate these into a list of JourneyResult . Finally, we return a Stream over these.
Let’s fill in getJourneysFrom :
private List<List<String>> getJourneysFrom(Node n, long numSteps) {
var journeys = new ArrayList<List<String>>();
n.getRelationships(Direction.INCOMING,
RelationshipType.withName(FOUND_CONDITION_REL)).
forEach(r -> {
var startPoint = r.getStartNode(n);
var journey = computeJourney(startPoint);
if (journey != null) {
journeys.add(journey);
}
});
return journeys;
}
What’s going on here? We start by creating an empty list to hold our journeys.
Then we find all the incoming relationships of type FOUND_CONDITION and iterate over them. For of these start points, we call the computeJourney function to get the subsequent Conditions . We add it to the list if the journey is not null. We add the null check because not all of the start points will have 3 or more subsequent Conditions . We can have computeJourney return null in those cases.
So let us define the computeJourney method:
private List<String> computeJourney(Node n, long numSteps) {
var output = new ArrayList<String>();
var next = n.getSingleRelationship(
RelationshipType.withName(NEXT_REL),
Direction.OUTGOING);
while (output.size() < numSteps && next != null) {
n = next.getOtherNode(n);
var nextConditionRel = n.getSingleRelationship(
RelationshipType.withName(FOUND_CONDITION_REL),
Direction.OUTGOING);
var nextCondition = nextConditionRel.getOtherNode(n);
var conditionName = (String)
nextCondition.getProperty(NAME_PROP);
output.add(conditionName);
next = n.getSingleRelationship(
RelationshipType.withName(NEXT_REL),
Direction.OUTGOING);
}
return output.size() == numSteps ? output : null;
}
We need to keep a running list of the Conditions as we walk through this patient’s Encounters . From our starting point, n , we ask for the outgoing NEXT relationship. We check that this node exists and if so we hop from it to the Condition node attached to it. We put this logic in a while loop, and reuse the n and next variables. The loop exits either when we have the desired number of subsequent Conditions or there are no more Encounters . At this point, we return the steps if there are enough; otherwise, null.
Collecting the results
Now that we have our journeys, we just need to aggregate and count them and we’re done! The collectPaths method takes care of this:
private List<JourneyResult> collectPaths(List<List<String>> paths) {
var results = new ArrayList<JourneyResult>();
var pathMap = new HashMap<List<String>, Integer>();
for (var path : paths) {
if (!pathMap.containsKey(path)) {
pathMap.put(path, 0);
}
int newValue = pathMap.get(path) + 1;
pathMap.put(path, newValue);
}
for (var e : pathMap.entrySet()) {
results.add(new JourneyResult(e.getKey(), e.getValue()));
}
return results;
}
We create a map of paths to counts. Then we loop over all our input paths. For each, we either create a new entry in the map or if it’s already there, increment its count by 1. I’m spelling it out in a fairly long-winded way here so that you can see the logic. There is probably a one-or-two-liner using Java 8 streams that does this- I’ll leave that as an exercise for the reader.
Et voila…
Wow! We’re done! That wasn’t too bad was it? We can run the procedure by executing mvn clean package in the root directory of our project. Your IDE probably has options for this too. Copy the resulting jar file into the plugins folder of your Neo4j installation, restart the instance and you are good to go!
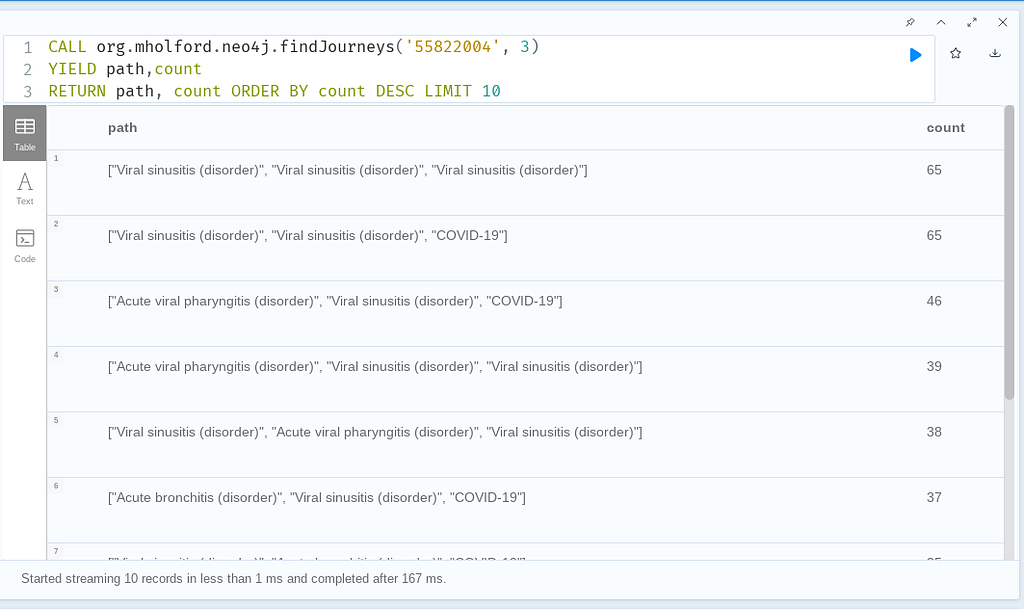
(Note: If you run the procedure on the sample dataset, you will notice that some Conditions are a bit over-represented in the Synthea data, which seems to reflect some dystopian future. Examples include chronic sinusitis, acute viral pharyngitis and COVID-19. Among my 100,000 synthetic patients, it showed over 87,000 Covid cases. Yikes! Stay safe out there folks…)
Well, that’s all for now! In our next installment, I will show you how to write tests for a stored procedure and how we can exploit Java tooling (e.g. live debugging, thread dumps, JFR) to help troubleshoot issues. We’ll also add more event types to our model and enable more options for the user. Hope you had as much fun as I did! Please check out all the code at our github repo here.
Happy coding!
Let’s Write a Stored Procedure in Neo4j — Part I was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



