

From zero to deployment with Neo4j’s Paradise Papers dataset.
Making the leap from a relational database to a graph database for an existing project is not easy. Questions arise:
What happens to the existing data? If the data is migrated, will the whole system have to be rewritten? What if we like our existing stack but still want the benefits of a graph database? Should we try a microservice? Will there be overhead? Will the overhead be worth it?
Thankfully for Django developers, the Neo4j ecosystem provides a quick and painless way to spin up a test implementation
The Paradise Papers Search App, based on the Paradise Papers dataset, is conveniently available on Neo4j Sandbox. By following along with the steps of this post, you will be able to spin up a small Django application to explore the Paradise Papers dataset either locally or on Heroku.
neo4j-examples/paradise-papers-django
About the Paradise Papers search app
Background
The ICIJ published a fraction of the Paradise Papers data as part of their Power Players visualization at the same time as the reported stories. Some time later, Neo4j added a version of the Paradise Papers dataset, with 163,414 nodes and 364,456 relationships, to the sandboxes available on Neo4j Sandbox.
Paradise Papers Archives – ICIJ
Data model
The model includes:
- A company, trust or fund created in a low-tax, offshore jurisdiction by an agent ( Entity )
- People or companies who play a role in an offshore entity (Officer)
- Addresses (Address)
- Law firms or middlemen (Intermediary) that asks an offshore service provider to create an offshore firm for a client
Each of these carries different properties, including name, address, country, status, start and end date, validity information, and more.
Relationships between the elements capture the roles people or other companies play in the offshore entities (often shell companies), we see many OFFICER_OF relationships for directors, shareholders, beneficiaries, etc.
Other relationships capture similar addresses or the responsibility of creating a shell company by a law firm (INTERMEDIARY_OF).
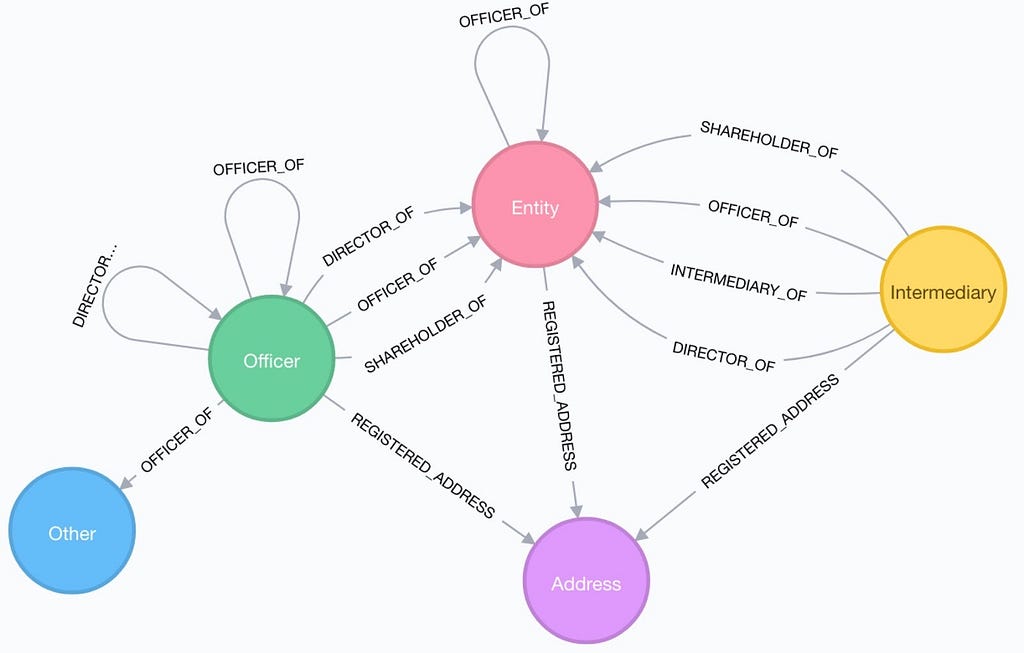
For a detailed description of the data model, check out An In-Depth Graph Analysis of the Paradise Papers.
Paradise Papers: an in-depth graph analysis
Django-Neomodel
The Paradise Papers app uses Django-Neomodel, a Django module allows you to use the Neo4j database with Django using neomodel.
Who uses Django, and why? Many python developers (or their employers) prefer to use an ORM such as Django as it allows them to focus on the business logic, the “money query,” or other more complex features of their product while the object mapper handles the relationship between the database, the Python models, and other aspects of web development.
Django’s introspection-generated admin portal is another benefit, avoiding the boilerplate code for administrator pages.
What about neomodel? Similar to Django, neomodel, an object mapper, allows Python developers to focus on solving problems for their users by thinking in terms of domain objects and less in terms of writing Cypher statements.
Neomodel documentation – neomodel 3.3.2 documentation
Neomodel uses the concepts of StructuredNode and StructuredRel to formalize the relationship between domain objects, Python classes and Neo4j nodes and relationships. (Read more about extending StructuredNodes)
But would anyone use neomodel with an existing ORM? If an ORM-based product would like to leverage Neo4j as well, the Django-neomodel plugin would allow them to add Neo4j-based functionality to their existing application.
The example app: Paradise Papers search
The Paradise Papers search app allows users to search and filter for Entities, Officers, Intermediaries, and Addresses, providing results in a list. It is not intended to be a fully-fledged app (although it can be considered such), but is rather an example of how a Python developer could integrate Neo4j into a Django application.
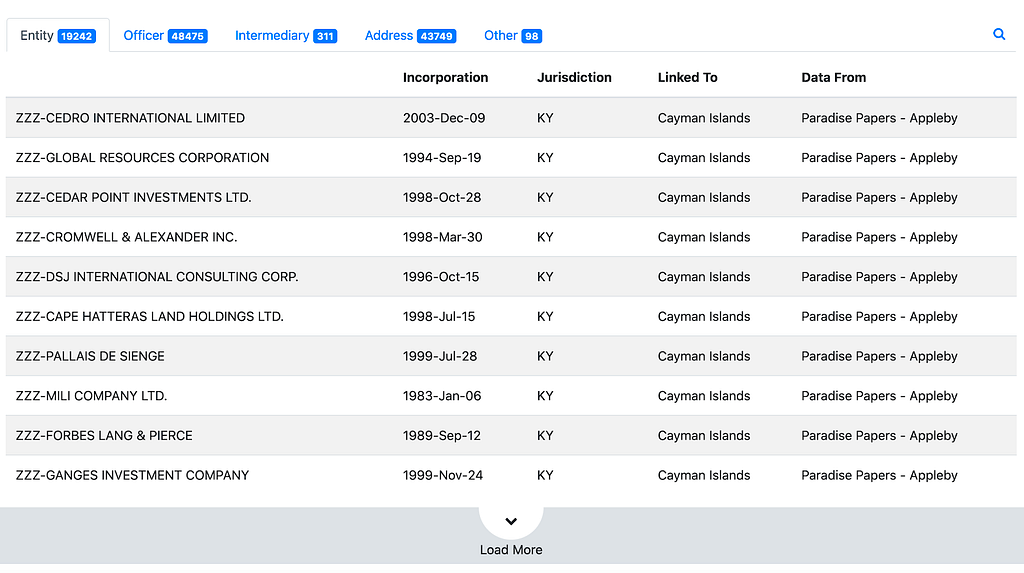
Upon clicking a list item, the user can see some details about the item, in addition to Entities, Officers, Intermediaries, or Addresses that might be connected to the item.
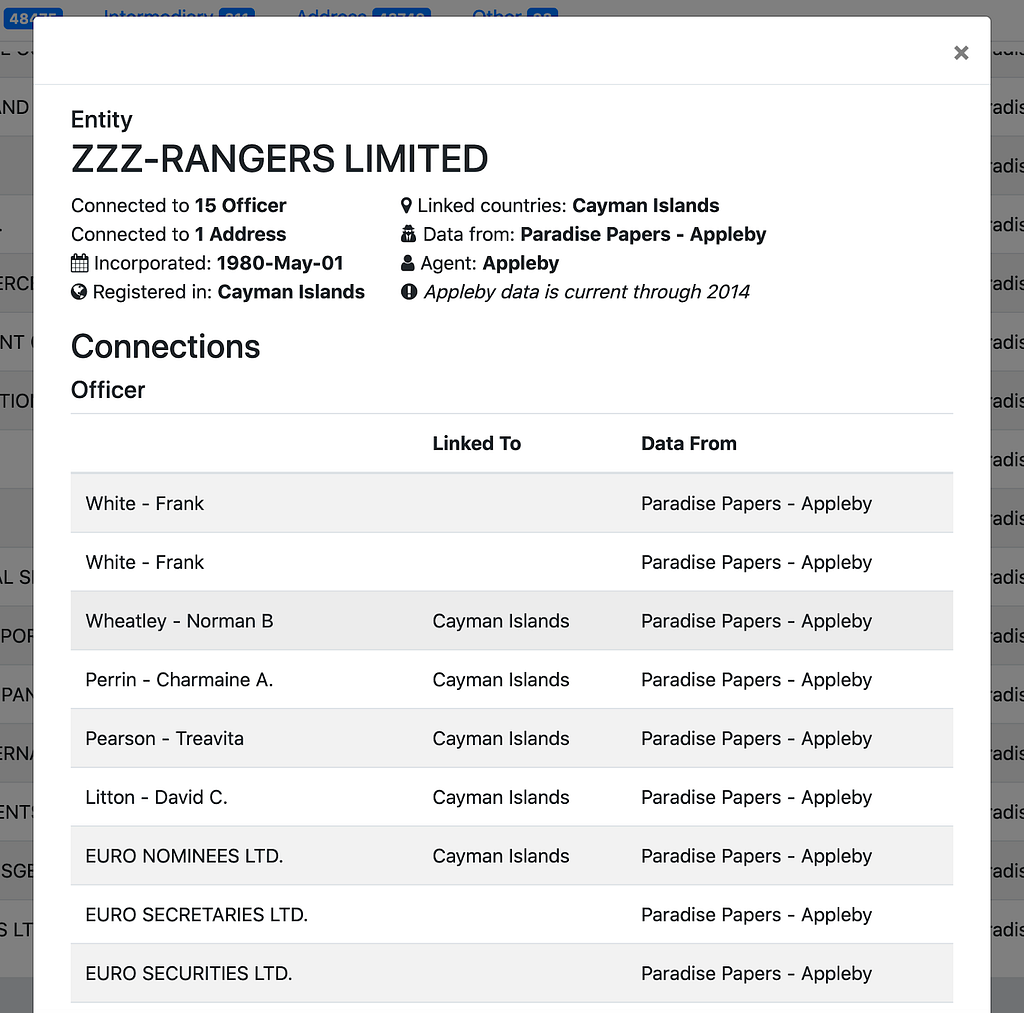
The “StructuredNodes entity
In the entity.py file, you will find a class Entity corresponding to Entity nodes in the Neo4j database.

A bit below the Entity definition, take a look at the example serializers. In this example, serializing the Officers, Intermediaries, Addresses, Entities, and Others that have relationships with a particular Entity:
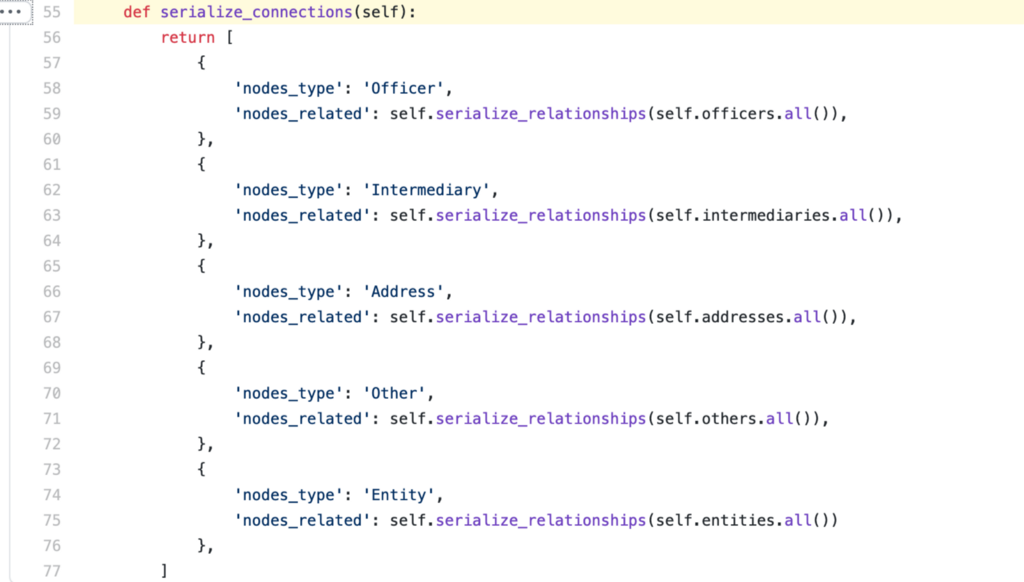
Address
Similarly, you can find the Address StructuredNode in address.py

Intermediaries, officers, and “other”
Intermediaries, Officers, and “Other” StructuredNodes can be found in the models directory of the repo.
Read more in the paradise-papers-django tutorial
Local app: Sandbox database
First step, set up your local environment.
Clone the repo:
neo4j-examples/paradise-papers-django
git clone [email protected]:neo4j-examples/paradise-papers-django.git
In a virtual environment, install the requirements:
pip install -r requirements.txt
Next, you’ll need to point your app to a sandbox instance of the Neo4j database. In Neo4j Sandbox, create an account and select Paradise Papers by ICIJ.
Check out the graph in the browser by clicking the “Open” button. You will find a informative Graph Guide detailing the dataset:
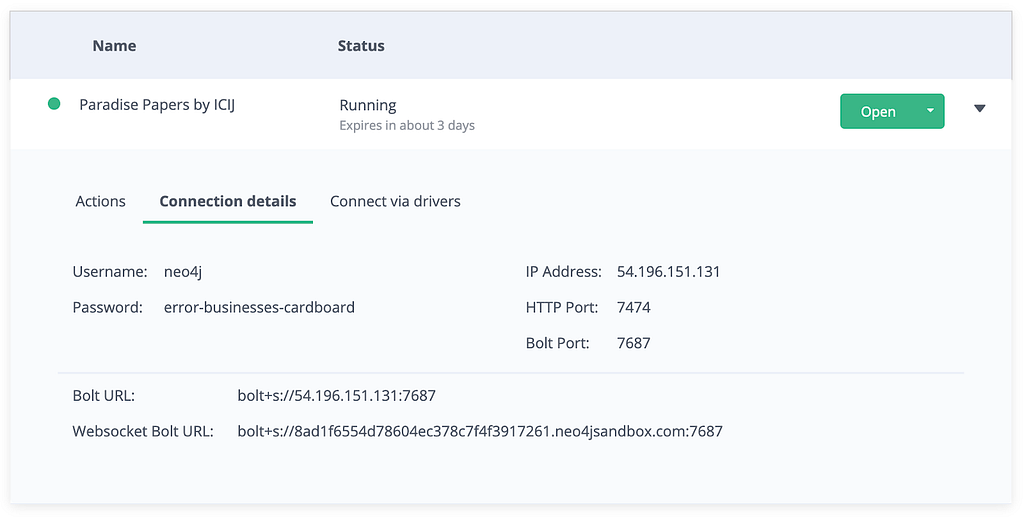
Back in the Sandbox UI, tap Connection details to find the database’s bolt URL, Username, and Password.
Since the Paradise Papers Search App uses Django Neomodel, which is built on the official Python driver, it is a good idea to double-check the suggested implementation under Connect via drivers > Python.
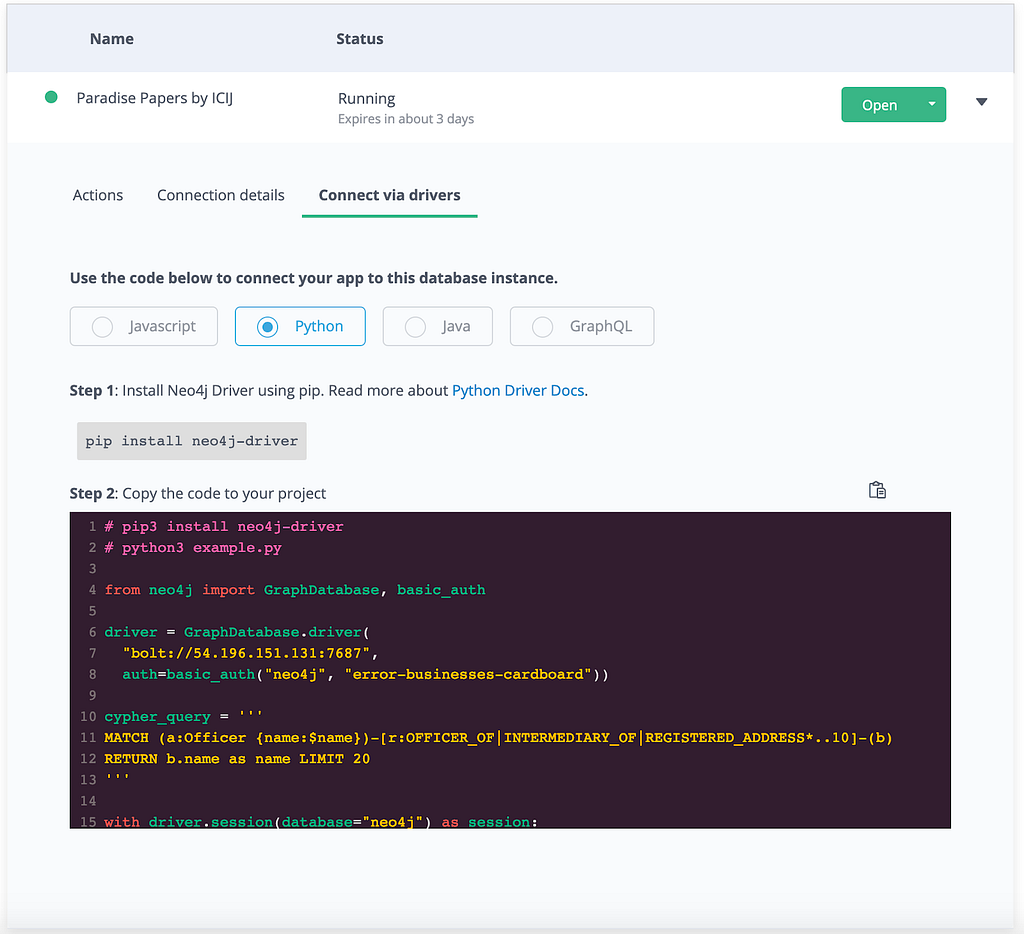
In your local environment, set the DATABASE_URL environment variable using the credentials found in the Sandbox admin:
export DATABASE_URL=bolt://<username>:<password>@<ip>:7687
Run the app!
python manage.py runserver
— settings=paradise_papers_search.settings.dev
Start searching at https://127.0.0.1:8000/
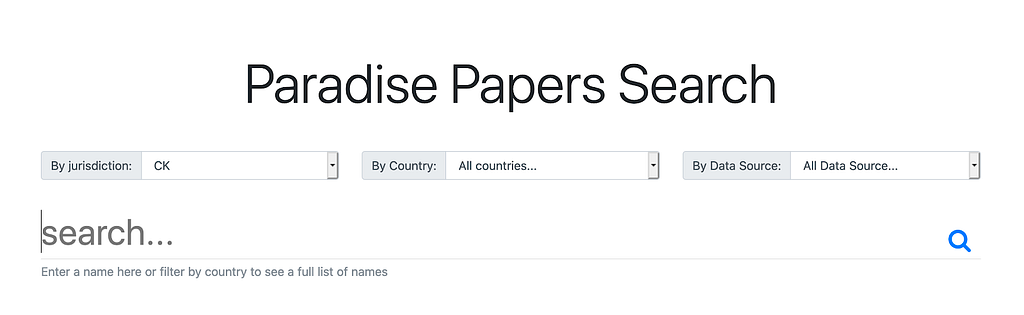
Local setup, local data
Sandbox comes with an expiration date, so if you want to do some additional experimentation, you will have to get the data and import it to your local database. We have made the sandbox datasets, browser guides and code examples available as GitHub repositories, that you can import into your Neo4j installation.
neo4j-graph-examples/icij-paradise-papers
Fortunately, Neo4j Desktop now supports that out of the box. If you have not yet done so, please download and install Neo4j Desktop.
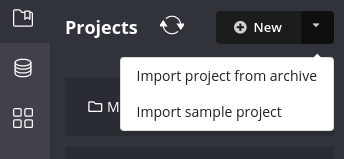
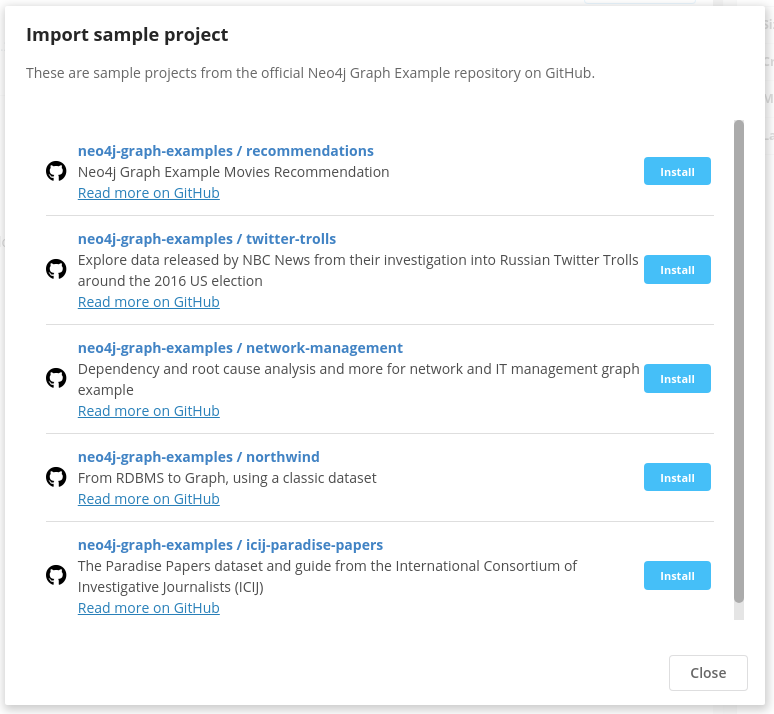
Import the repository into desktop, via the New -> Import sample project. And pick the icij-paradise-papers from the list. That should prompt you for the database import and create a database and project for you.
Back in your app, update the database environment variables to reflect this new database.
export DATABASE_URL=bolt://neo4j:<password>@localhost:7687
Deploy to Heroku
An app deployed locally is okay, but what about deployment?
Create a new Heroku app, (for example, paradise-papers)
Go to the app’s settings and add the following config vars:
ALLOWED_HOST : paradise-papers.herokuapp.com
(change to your app name)
DATABASE_URL: the credentials from your sandbox database
Over in your local terminal inside the repository, add the Heroku app as a remote, then push to Heroku:
git remote add heroku https://git.heroku.com/paradise-papers.git
git push heroku master
View your app at the URL you specified in the configuration.
Use a Neo4j Aura database
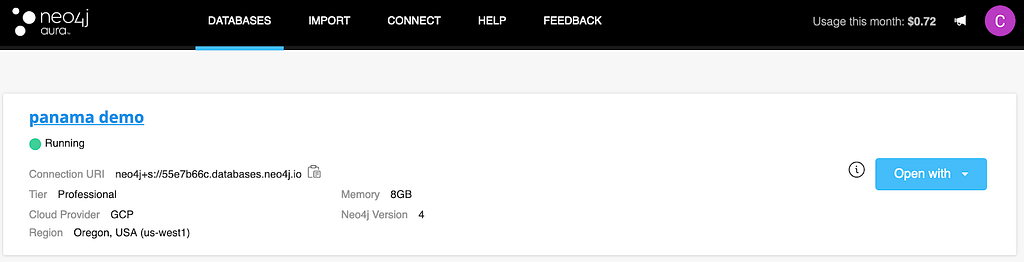
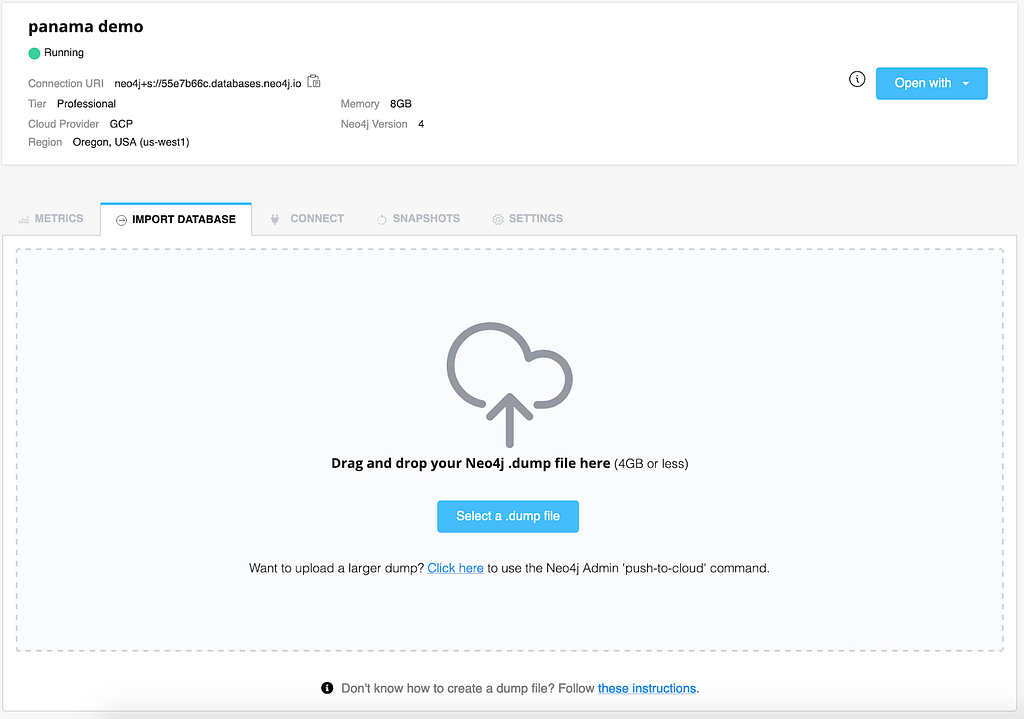
Now that you’ve seen the app in action locally and on a remote server, if you want someone else to be able to visit the app without your computer running, you may want to use a database on Neo4j Aura.
After creating an Aura account, you can import by following the wizard on the Aura console. You can drag and drop your dump-file onto the browser to seed your database.
Next steps
After testing out the ICIJ Panama Papers database, you may want to test out using some of the data native to your Django application. Test out converting your relational data set using the Neo4j ETL Tool.
Looking for more details on how Neo4j was used in the Panama Papers investigation? Check out our full coverage here:
- An In-Depth Graph Analysis of the Paradise Papers
- How the ICIJ Used Neo4j to Unravel the Panama Papers
- Analyzing the Panama Papers with Neo4j: Data Models, Queries & More
- The Panama Papers: Why It Couldn’t Have Happened Ten Years Ago
Resources
- neo4j-contrib/neomodel
- neo4j-contrib/django-neomodel
- neo4j/neo4j-python-driver
- Getting Started with Neomodel
About the authors
Cristina and Alisson work at The SilverLogic, a software development company based in Boca Raton.
Alisson is a software engineer at The SilverLogic. Passionate about plants, he is the driving force behind Que Planta, a GraphQL-based social network for plants.
Neo4j for Django Developers was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles



SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3


