
Hybrid Retrieval for GraphRAG Applications Using the GraphRAG Python Package

Senior Software Engineer, AI
7 min read
Introduction
In this third installment of our series on the Neo4j GraphRAG Python package, we explore how to use full-text indexes to enhance GraphRAG applications. We’ll show how combining a full-text index with a vector index can improve the performance of the retrieval process by retrieving information that might be missed by vector retrieval alone. Additionally, we’ll walk through building a GraphRAG application that leverages both a full-text index and a vector index using the Neo4j GraphRAG Python library.
Setup
First, make sure you have installed the Neo4j GraphRAG package, the Neo4j Python driver, and the OpenAI Python package:
pip install neo4j neo4j-graphrag openaiWe’ll use some of the pre-configured Neo4j demo database used in the previous blogs (see The GraphRAG Python Package and Enriching Vector Search With Graph Traversal Using the GraphRAG Python Package). This database simulates a movie recommendation knowledge graph. For more information about the database, read the setup section of The GraphRAG Python Package.
You can access the database through a web browser at https://demo.neo4jlabs.com:7473/browser/ using “recommendations” as both the username and password. Use the following snippet to connect to the database in your application:
from neo4j import GraphDatabase
# Demo database credentials
URI = "neo4j+s://demo.neo4jlabs.com"
AUTH = ("recommendations", "recommendations")
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)Additionally, make sure to export your OpenAI key:
import os
os.environ["OPENAI_API_KEY"] = "sk-…"The Limitations of Vector Search
Vector search is often a fundamental component of a RAG application. It enables an application to find information in a database ssemantically similar in meaning to a user’s query and provide that information as relevant context for an LLM to generate a response. In previous series posts, we used vector search in a GraphRAG application to return movies with plots that closely match user queries in meaning and answer their questions about movies. If a user asks, “What’s the name of the movie about the dinosaur theme park?” vector search would retrieve the movie Jurassic Park. This is because the plot, “During a preview tour, a theme park suffers a major power breakdown that allows its cloned dinosaur exhibits to run amok,” is similar in meaning to the user query.
However, semantic similarity is not always the best measure for retrieving the most relevant information for every query. For example, when searching for domain-specific terms that lack broad semantic meaning or have different meanings in a wider context, vector search may fail to retrieve relevant information or may return irrelevant information. This occurs because these terms might not be well-represented in the training data of the embedding model used for vector search. Semantic similarity is also not a reliable measurement when a user query includes strings like names or dates that need to be matched exactly for accurate results. An example of this is when using a VectorRetriever to ask for the name of a movie set in a specific place and date, such as a movie set in 1375 in Imperial China:
from neo4j import GraphDatabase
from neo4j-graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j-graphrag.retrievers import VectorRetriever
driver = GraphDatabase.driver(URI, auth=AUTH)
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = VectorRetriever(
driver,
index_name="moviePlotsEmbedding",
embedder=embedder,
return_properties=["title", "plot"],
)
query_text = "What is the name of the movie set in 1375 in Imperial China?"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)To accurately match this, the VectorRetriever matching algorithm would need to find an exact date reference to 1375 within a movie’s plot description, which it’s unable to do. Consequently, the VectorRetriever fails to return the correct movie for this query (Musa the Warrior). Instead, it retrieves movies set in or related to China, but none of them are set in 1375.
items = [
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China (Wong Fei Hung)', 'plot': "Set in late 19th century Canton this martial arts film depicts the stance taken by the legendary martial arts hero Wong Fei-Hung (1847-1924) against foreign forces' (English, French and ..."}",
metadata={"score": 0.9209008812904358, "nodeLabels": None, "id": None},
),
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China II (Wong Fei-hung Ji Yi: Naam yi dong ji keung)', 'plot': 'In the sequel to the Tsui Hark classic, Wong Fei-Hung faces The White Lotus society, a fanatical cult seeking to drive the Europeans out of China through violence, even attacking Chinese ...'}",
metadata={"score": 0.9179003834724426, "nodeLabels": None, "id": None},
),
RetrieverResultItem(
content="{'title': 'Red Cliff Part II (Chi Bi Xia: Jue Zhan Tian Xia)', 'plot': 'In this sequel to Red Cliff, Chancellor Cao Cao convinces Emperor Xian of the Han to initiate a battle against the two Kingdoms of Shu and Wu, who have become allied forces, against all ...'}",
metadata={"score": 0.91493159532547, "nodeLabels": None, "id": None},
),
]
metadata = {"__retriever": "VectorRetriever"}Full-Text Indexes
Fortunately, there is a solution to this issue: full-text indexes. Unlike vector indexes, which match strings based on semantic similarity, full-text indexes match pieces of text based on lexical similarity, meaning they compare the exact wording or text structure. For example, consider the sentences “The bat flew” and “The bat broke.” These sentences are lexically similar, as they differ by only one word, but they are semantically distinct. The first describes an animal flying, while the second describes an object breaking. Full-text indexes enable us to match strings such as dates and names exactly.
The Hybrid Retriever
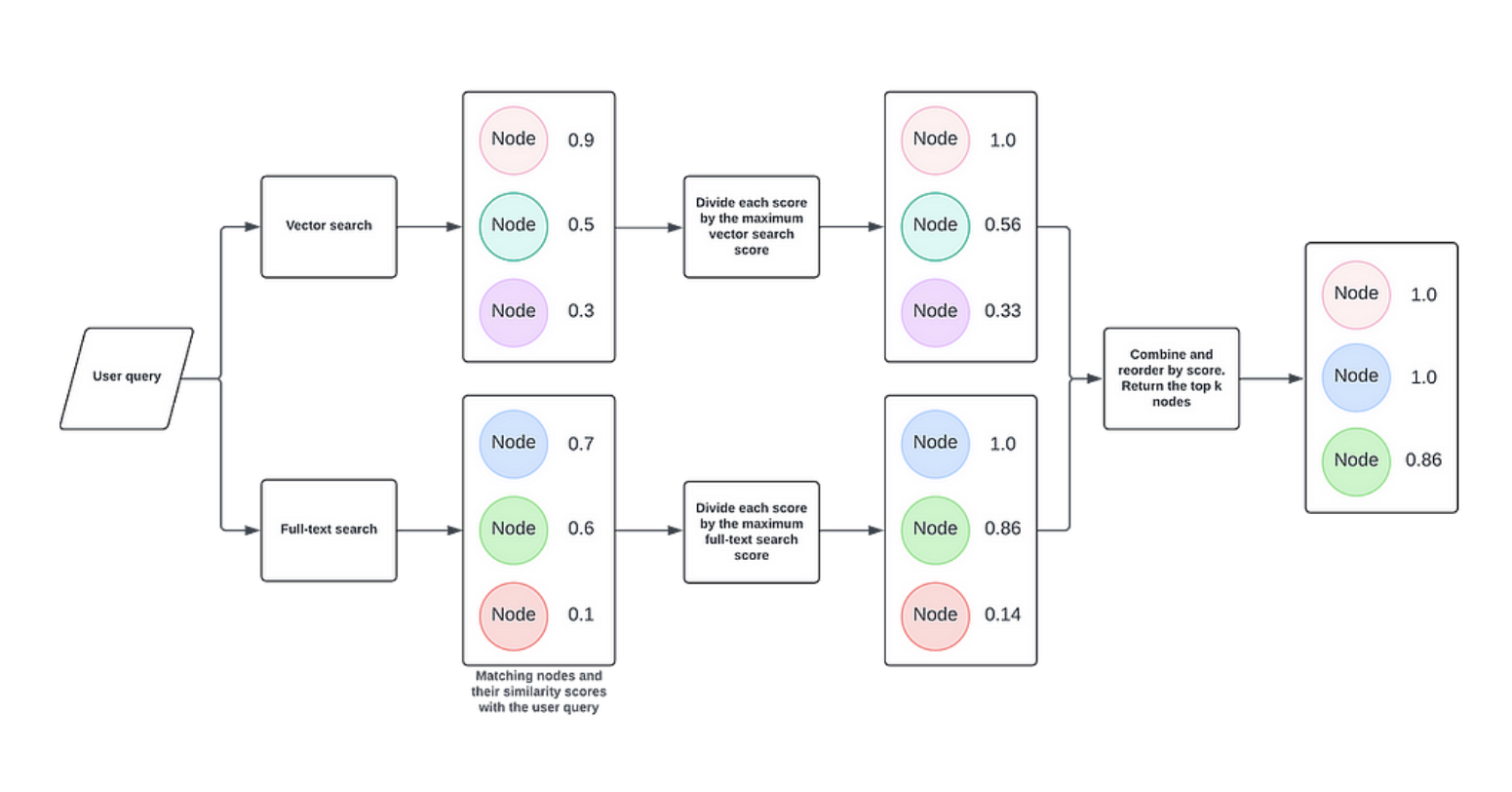
We can use full-text indexes for our GraphRAG applications by using the HybridRetriever class from the Neo4j GraphRAG Python library. This retriever leverages both a vector index and a full-text index in a process known as hybrid search. It uses the user query to search both indexes, retrieving nodes and their corresponding scores. After normalizing the scores from each set of results, it merges them, ranks the combined results by score, and returns the top matches.
from neo4j import GraphDatabase
from neo4j-graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j-graphrag.retrievers import HybridRetriever
driver = GraphDatabase.driver(URI, auth=AUTH)
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = HybridRetriever(
driver=driver,
vector_index_name="moviePlotsEmbedding",
fulltext_index_name="movieFulltext",
embedder=embedder,
return_properties=["title", "plot"],
)
query_text = "What is the name of the movie set in 1375 in Imperial China?"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)Here, we again use the vector index for movie plots (moviePlotsEmbedding), as well as the full-text index, for the combined title and plot of each movie (movieFulltext). Using this retriever returns the correct movie:
items = [
RetrieverResultItem(
content="{'title': 'Musa the Warrior (Musa)', 'plot': '1375. Nine Koryo warriors, envoys exiled by Imperial China, battle to protect a Chinese Ming Princess from Mongolian troops.'}",
metadata={"score": 1.0},
),
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China (Wong Fei Hung)', 'plot': "Set in late 19th century Canton this martial arts film depicts the stance taken by the legendary martial arts hero Wong Fei-Hung (1847-1924) against foreign forces' (English, French and ..."}",
metadata={"score": 1.0},
),
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China II (Wong Fei-hung Ji Yi: Naam yi dong ji keung)', 'plot': 'In the sequel to the Tsui Hark classic, Wong Fei-Hung faces The White Lotus society, a fanatical cult seeking to drive the Europeans out of China through violence, even attacking Chinese ...'}",
metadata={"score": 0.9967417798386851},
),
]
metadata = {"__retriever": "HybridRetriever"}To turn this into a full GraphRAG pipeline, we simply add the following code:
from neo4j-graphrag.llm import OpenAILLM
from neo4j-graphrag.generation import GraphRAG
# LLM
# Note: the OPENAI_API_KEY must be in the env vars
llm = OpenAILLM(model_name="gpt-4o", model_params={"temperature": 0})
# Initialize the RAG pipeline
rag = GraphRAG(retriever=retriever, llm=llm)
# Query the graph
query_text = "What is the name of the movie set in 1375 in Imperial China?"
response = rag.search(query_text=query_text, retriever_config={"top_k": 3})
print(response.answer)Which returns us the answer we expect:
The name of the movie set in 1375 in Imperial China is "Musa the Warrior (Musa)."Summary
We’ve demonstrated how to use the HybridRetriever class from the neo4j-graphrag package to build a GraphRAG application. We showed how this class combines vector and full-text search to retrieve the correct context for user queries, which might not be possible with vector search alone.
We invite you to use the neo4j-graphrag-python package in your projects and share your insights via comments or on our GraphRAG Discord channel.
The package code is open source, and you can find it on GitHub. Feel free to open issues there.
Hybrid Retrieval for GraphRAG Applications Using the Neo4j GraphRAG Python Package was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Managing Risk in a Manufacturing Plant With Neo4j Aura Graph Analytics
