Try Neo4j’s next-gen graph-native store format

Principal Database Product Manager at Neo4j
5 min read

The latest version of Neo4j 5 Enterprise Edition (v.5.14) includes the beta release of our highly anticipated new storage engine that introduces Block format, a generational leap in graph-native storage.

We developed the new format using Neo4j’s decades of experience with graph data.
Block format lays out the data on disk in a structure that significantly increases the efficiency of Neo4j’s page cache and prevents data fragmentation. Individual pages contain more related data, which means fewer IOPS to retrieve the data required by a query. Since that data resides on fewer pages, processing the query requires less memory. And as the storage is more compact, it fits more likely in continuous CPU caches. The larger the graph the more significant the benefits of Block format.
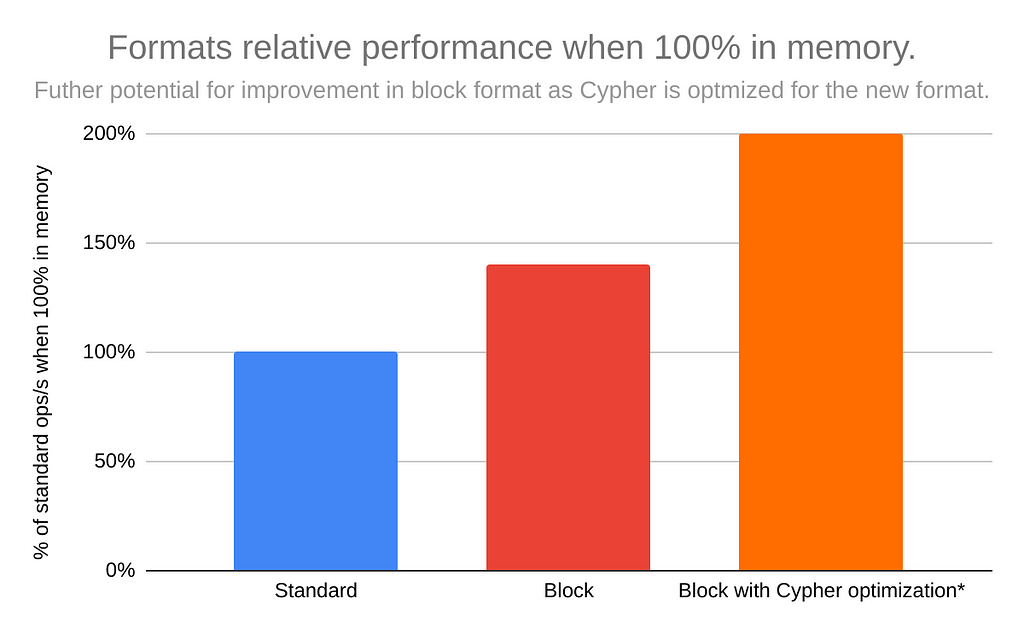
Compared to the existing Record format, our previous format, Block format has roughly 40% better performance when the whole graph is in memory. That lead increases to 70% when only a third of the graph can fit in memory.
The beta version of the Block format is available now in Neo4j Enterprise Edition v5.14, with the GA release expected early in 2024.
Here’s how you can give it a try on your local instance:
Create a new database — Use the following Cypher to create a new database in block format: CREATE DATABASE blockdb OPTIONS {storeFormat: 'block'}
Migrate an existing database — From the command line, use neo4j-admin migration: neo4j-admin database migrate --to-format="block" mydb. If you’re working with a cluster, the database must be re-seeded after migration.
Copy an existing database — From the command line, use neo4j-admin copy: neo4j-admin database copy --to-format="block" mydb blockdb
Create from CSV — From the command line, use neo4j-admin import: neo4j-admin database import ... --format=block blockdb
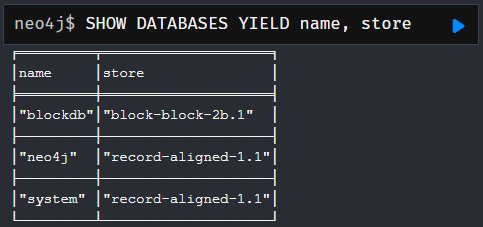
You can confirm a graph’s store format by running the following Cypher: SHOW DATABASES YIELD name, store and that’s it — from an application’s perspective, Neo4j will work exactly as before, just faster!
Performance tests
Our internal micro-benchmarks show that some operations improve by an order of magnitude, and others remain unaffected. The benefit you will see will depend on the mixture of operations that make up your workload, YMMV.
But rather than picking a tailored workload to create the most dramatic headline — here’s how we approached it:
We used an internal suite of performance tests that represents the extensive range of workloads we support in Neo4j. The performance test suite executes Cypher read queries that exercise 100% of the graph, while the write queries exercise about 25% of the graph.
We compared the performance to Record format across three scenarios with different amounts of memory available to the database data:
- 100% of the data fit in memory
- 71% fit in memory
- 36% fit in memory
As expected, Block format’s performance remains high even as available memory for the page-cache size is reduced.
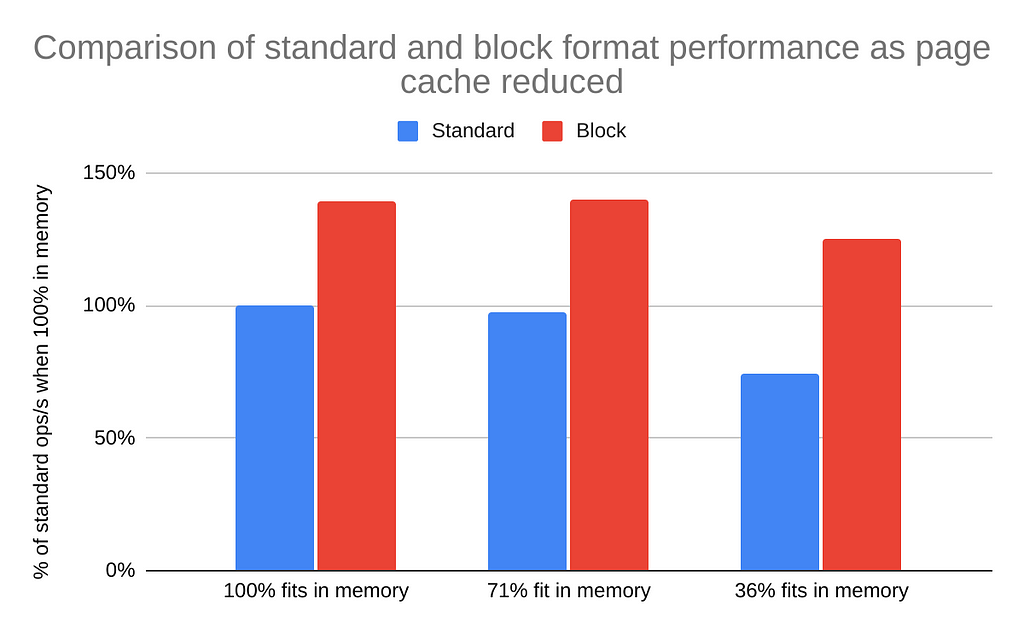
The results above are based on a 180GB graph running on a server with 256GB of total RAM. The memory constraints were simulated using tools that reserve memory, making it unavailable to Neo4j and the OS page cache.
We’re in the process of running the same performance tests on a 1.8TB graph. Early results show Block format’s advantage over Record format grows substantially as the graph increases in size, which is great news for you and us.
Roadmap
Block format is the culmination of extensive R&D, and we’re excited to make it publicly available for beta testing. For the last few months, we’ve successfully run thousands of Neo4j Aura Free databases using block format. If you haven’t noticed (except for better performance), that’s good news.
Block format replaces all previous formats on Neo4j v5 — Standard, Aligned, and High Limit. It performs better than Aligned and supports the same scale as High Limit. With the GA release, new databases on Neo4j Aura will default to Block format, and the defaults for self-managed Neo4j packages will be updated similarly.
We plan to support the legacy formats throughout the v5 and v6 lifecycles.
Even after the GA release, we hope to see further improvements. For example, the Cypher planner isn’t yet fully optimized to take advantage of the Block format’s neat tricks. If we can make the Cypher planner as efficient for Block format as it is for legacy formats, we should see a further 40% improvement.
Current limitations
Converting an existing database must be done offline and can be time-consuming for large databases. A 180GB database took 15 minutes on a machine with 44 Core CPU, 512 GB RAM, and 2TB SSD. We’re looking into reports of databases that contain mostly dense nodes taking much longer.
The Block format beta currently doesn’t support incremental bulk import.
Final thoughts
Neo4j continues to lead the way with its graph-native database. When we started our key goal was to create a next-generation storage engine capable of handling databases too large to fit in memory while providing consistent high performance as the databases grow.
The result is a more efficient and scalable implementation of Neo4j’s graph-native storage informed by our more than a decade of experience supporting real-world production graph workloads. Block format raises the bar on what can be achieved with today’s hardware and software.
This is another leap in performance for Neo4j, and it comes just a month after we released Parallel Runtime. Neo4j v5 is an incredible upgrade for anyone still using Neo4j v4.4, with massive performance gains and features like Vector Search Indexes, Change Data Capture, Quantified Graph Patterns, Differential Backups, and Rolling Upgrades.
Let us know what you think of Block Format in the comments or raise issues on GitHub.
Try Neo4j’s next-gen graph-native store format was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles



Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher


