Put data modeling on the table

Software Developer, Tikal – Fullstack as a Service
8 min read

Data modeling is out of date. This conclusion became apparent when I tried locating new data modeling books, research studies, and recent developments in data modeling. It makes me wonder whether the question we should all be asking is whether we even have the right way to model data?
A data model’s main purpose is to ensure data is understood, stored, and retrieved from databases consistently and in accordance with business rules. Additionally, the visualizations of data models allow different individuals and teams to communicate with each other more efficiently. Effective visualization fosters high-level cognitive abilities, including classification, unification, knowledge completion, and reasoning.
Who is the data modeler?
We embrace modeling, but not in order to file some diagram in a dusty corporate repository.
– Agile Manifesto
Have you ever had the feeling of playing a game of Chinese Whispers while you’re trying to figure out what the original requirement was? The data model is intended to prevent this. By creating intuitive visualizations, we can share knowledge and improve communication between engineers, QAs, product managers, data analysts, DevOps, technical writers…
Agile isn’t an excuse for poor design. Yes, we need to move fast, adapt to changes, and provide flexible systems. We cannot afford the whole, long design phase like we did in the past. Yet our task is even more difficult – we must build a puzzle without knowing how the whole picture fits together.
Software engineers/DevOps/product managers took responsibility for modeling as the design phase began to break up into chunks. For the model to be an effective communication tool for both technical and non-technical persons, it must be clear and understandable.
Relational databases – with their rigid schemas and complex modeling process – aren’t a good fit for rapid change. Schema migration is literally no one’s favorite database activity. Once the database goes live and is in production, we just don’t want to change it. This is what the agile support data model is meant to remedy – it supports ongoing evolution while maintaining the integrity of your data.
Relational schema abstraction leaks
For years, relational data models have been the standard. What if normalized relational schema models can’t represent logical entities efficiently?
Normalizing the schema reduces redundancies and eliminates anomalies. Writing to the database efficiently is dependent on this. The normalized schema is structured in such a way that there is no redundancy or duplication. When some piece of data changes, you only need to change it in one place, with no need to ensure the change is applied across many copies of the data in many different locations. However, many simple read queries require expensive JOIN operations.
Impedance mismatch is a term, adopted from the electronic industry, that describes the mismatch between objects and tables. An object-oriented model connects objects by inheritance or composition, while a relational model is just a collection of tables connected by foreign keys. We are using ORM as a middleware to translate and abstract the differences between the layers to close this gap.
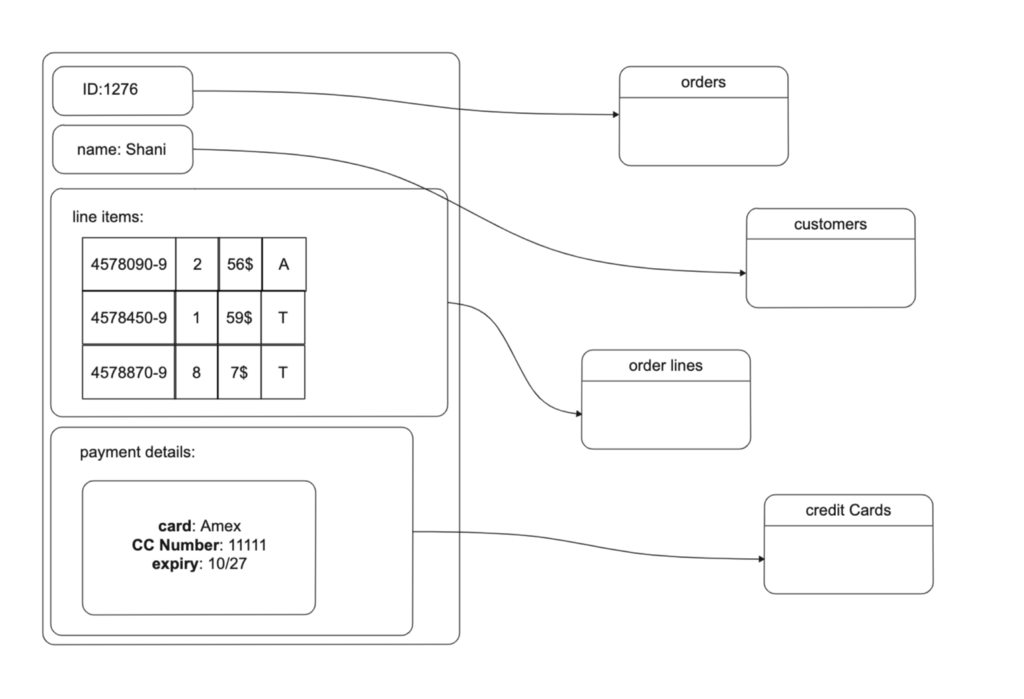
Application layer objects are actually written to multiple tables in the relational database. Every time an object is needed, a JOIN table creates the original object. In this split and merge way, an ORM layer abstracts the data structure of the database.
Object-relational mapping (ORM) frameworks like Hibernate reduce the amount of boilerplate code required for this translation layer, but they can’t completely hide the differences between the two models.
Data is in a relationship, and it’s complicated
What are the methods for storing relationships of different types within normalized databases?
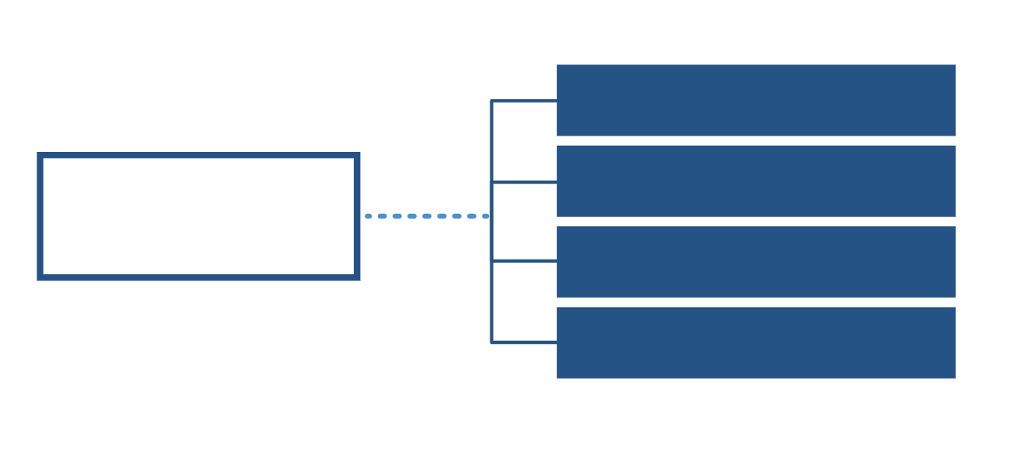
One-to-many/many-to-one relations are stored in separate tables. Each identifier of the “one” entity is stored in the “many” table for each row that belongs to the entity.
One-to-many, and sometimes many to one, are often implemented by embedding or nesting the “many”, in schemas other than relational. While nesting objects allows reading and writing to be done in one operation, thus solving the impedance mismatch problem, the RDBMS supports for nesting objects are poor.

Many-to-many relationships add complexity and confusion to the relational model and the application development process. The key to resolving many to many relationships is to separate the two entities and create two one-to-many relationships between them with a third intersect entity. The intersect entity usually contains attributes from both connecting entities.
There’s no doubt that we can use RDBMS to implement almost any case, but is that really the general approach? If hierarchical, nested objects are stored, the depth of nested objects is missed. If a reach, connected domain object is being used, it will struggle to navigate these relationships effectively.
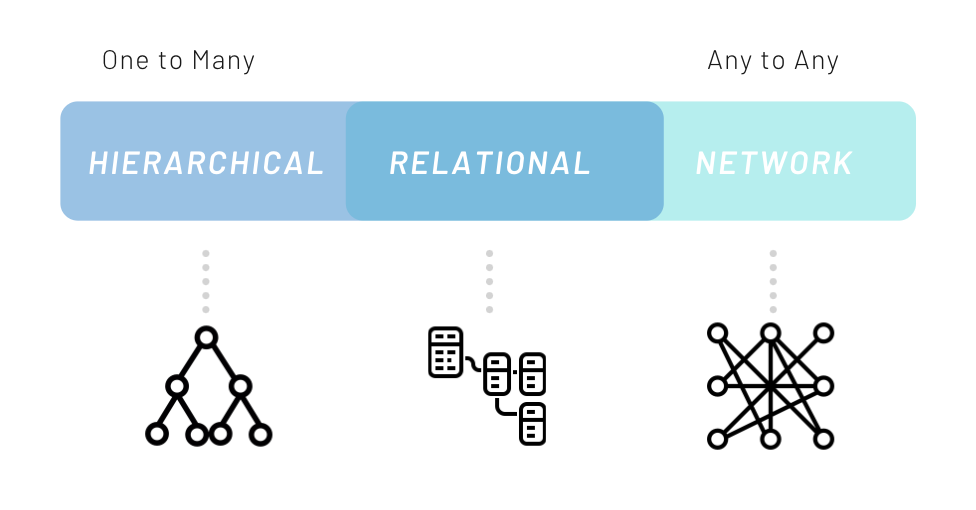
Graph model can do it
As time goes on, more and more domains become more complex, relationships among entities are stronger, and the world generally becomes more interconnected. Only a database that natively embraces relationships can store, process, and query connections efficiently. A graph database stores connections alongside the data in the model.
In a graph database, the relationships between the data are just as important as the data itself. It is intended to hold data without constricting it to a pre-defined model. Instead, the data is stored like we first draw it out, showing how each entity connects with or is related to others.
For highly interconnected data, the hierarchical/document model is awkward, the relational model is acceptable, and graph models are the most natural.
Whiteboard-friendly modeling
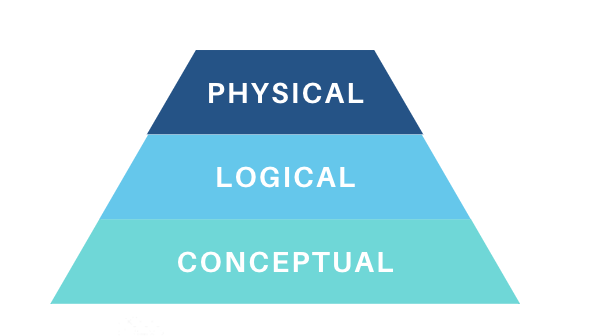
Data modeling building blocks are the three independent schemas: Conceptual, Logical, and Physical (which in many cases, is just the DB schema).
Conceptual data model
A concept map is a tool that visualizes relationships between concepts. Concept mapping arose from the field of learning psychology and has proven to be useful to identify gaps and loopholes, and enhances the learning of science subjects.
While UML and entity-relationship diagrams failed as business-side tools, concept mapping is readily accepted in its place. Concept mapping allows both businessmen and technical experts to communicate intuitively and visually. Furthermore, current knowledge about early learning emphasizes concept maps.
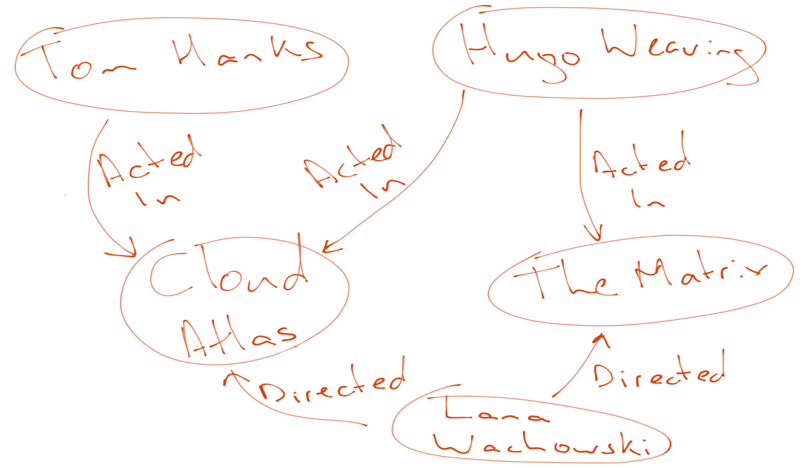
Logical data model
What graph databases do very well is represent connected data. Representing any model is about communicating these two perspectives:
- Structure (connectedness)
- Meaning (definitions)
Together they explain the context very well. Nodes represent entity types, which I prefer to call types of business objects. Edges, better known as relationships, represent the connectedness and, because of their names, bring semantic clarity and context to the nodes. Concept maps exploit the experiences from educational psychology to speed up learning in the design phase. That is why the labeled property graph model is the best general-purpose data model paradigm currently available. Expressed as a property graph, the metamodel of property graphs used for solution data modeling looks like the following model:

Property graphs are similar to concept maps in that there is no normative style (e.g. like there is in UML). So feel free to find your own style. If you communicate well with your readers, you have accomplished the necessary.
“The limits of my language mean the limits of my world.”
– Ludwig Wittgenstein
In his book Designing Data-Intensive, Martin Kleppmann states: “Data models are perhaps the most important part of developing software because they have such a profound effect not only on how it is written but also on how we think about the problem.”
There has been a strong focus on relational modeling and normalization for years. As I wrote, however, there’s something wrong with that approach. The normalized tables collection does not fit with what we planned on the board. The relationships between entities do not clear for anyone other than business analysts/data modelers (Crow’s Foot notation – anyone?)
Graph schema does not modify the data model to fit a normalized table structure. The graph data model stays exactly as it was drawn on the whiteboard. This is where the graph data model gets its name for being “whiteboard-friendly.” Additionally, it embraced schema changes as a fact and prepared for them, instead of striving to avoid them.
I suggest talking about graph schemas as intuitive, learning-effective, communication-friendly, and aligning from the moment we draw on the board to the storage layer.
“All models are wrong, but some are useful.”
– George Box
References:
[1] Martin, Designing Data-Intensive Applications (2017), O’Reilly Media, Inc.
[2] F, Thomas. Graph Data Modeling for NoSQL and SQL (2016), Technics Publications.
Put Data Modeling on the Table was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



