

Welcome back to part two in the five part 4.3 Technical Blog Series. This week, it is the turn of the Relationship Chain Locks — or if you caught the 4.3 update during Emil’s NODES Keynote, “How to avoid a lot of locking when you update the Rock!”

- Relationship / Relationship Property Indexes
- Relationship Chain Locks (this blog)
- Deploying on Kubernetes with Helm Charts
- Server Side Routing
- Read Scaling for Analytics
I am going to cover why you need Relationship Chain Locks in your graph database solution, the conditions under which Neo4j uses them (this isn’t something you configure or invoke), how it all works under the hood, and a speed test vs prior versions of Neo4j. Plus, if you are interested, a bonus under the hood in-depth explanation of the feature.
What are Relationship Chain Locks and when do you need them?

Imagine you have a popular social media network like Instagram, and you want to add a new follower to a celebrity like Dwayne “The Rock” Johnson and his 232 million followers. Then you need to lock the Rock and the people who want to be added as followers. That is a lot of locking when you have nodes like the Rock. When a pattern of nodes connected to hundreds/thousands or millions of other nodes emerge in a graph they can be referred to as dense nodes (nodes with dense relationships) or super nodes (check out Dave Allen’s blog on Graph Modeling with Super Nodes).
In order to perform an update, a lock is required to ensure you don’t get data corruption — which could occur if someone else wants to follow the Rock at the same time — say one of his posts goes viral! So locks are good, they help ensure data integrity. The trouble is that waiting (AKA lock contention) is required when your multi-threaded application needs to perform updates on the same nodes/relationships. The more nodes/relationships and load you have, the more likely you are to need to wait for a lock to be released in order to perform an update.
Prior to 4.3, Neo4j obtained a lock on the Rock to add/delete a relationship flowing to/from the Rock — and with 232 million followers that can mean a lot of locking to update the Rock.
Don’t block the rock with Neo4j 4.3

So how does the latest version of Neo4j avoid blocking the Rock when adding/deleting relationship types and directions? The quick answer is… the storage engine implements new locking algorithms that are used to acquire and release the graph locks across internal elements in the store. For an in-depth explanation, refer to the section “Bonus — so how does it work?”
So when can additions/deletions of a specific type and direction be handled concurrently? The new algorithm is applied when nodes reach 50+ relationships — the point at which they are considered super nodes. Note this is not reversible; once a node is treated as a super or dense node it will remain so even if the relationship count drops to 48. A relaxed locking algorithm has been implemented as well. This is used when there are 10+ relationships of a given type and direction in any one group.
Why not just do this all the time? Well, you don’t get something for nothing and while only a few microseconds are added by this mechanism it would have a disproportionate impact on nodes with only a few relationships.
This means your code, Cypher commands, import scripts, etc. will run a lot faster when you have super nodes in your graph. Please note, if you have been putting hacks in your scripts to try and work around lock contention you should remove them before you upgrade to 4.3. It is worth noting that no store migration is required when you upgrade to 4.3.
So, let’s rock!
I am going to test this out by creating a graph with 100 super nodes (with a Person label) that represent some celebrities, and then create 100,000 nodes that follow one of the celebrities at random — not quite the Trillion relationship graph you saw at NODES but with nearly 1000 relationships the nodes are sufficiently dense to put a 4 GB Docker instance running on my laptop through its paces. If you want to follow along, here is my code to create the container and test out the relationship locking.
#neo4j-the-rock.sh — script to create the docker instance
#We need APOC so make sure to move the plugin aligned version from /labs to /plugins
export HERE=`pwd`
export CONTAINER=`docker run
— name neo4j-the-rock
— detach
— publish=7474:7474
— publish=7687:7687
— volume=$HERE/data:/data
— volume=$HERE/import:/var/lib/neo4j/import
— volume=$HERE/plugins:/plugins
— ulimit=nofile=40000:40000
— env=NEO4J_dbms_memory_heap_max__size=4G
— env=NEO4J_dbms_memory_pagecache_size=2G
— env=NEO4J_ACCEPT_LICENSE_AGREEMENT=yes
— env=NEO4J_AUTH=neo4j/**e*******
neo4j:4.3.1-enterprise`
Using Cypher, let’s generate the celebrities.
// Create a list of 100 entries and iterate through the list passing the number in as an id for the person node.
UNWIND range(1,100) as id create (p:Person {id:id}) return p;
Next, create a node that has a relationship [:FOLLOWS] to a random “celebrity node” using APOC’s periodic iterate which will process the 100,000 follower nodes in batches of 5.
call apoc.periodic.iterate(“UNWIND range(1,100000) as id RETURN id”,
“MATCH (p1:Person) WHERE id(p1)=toInteger(rand()*100)
CREATE (p1)-[:FOLLOWS]->(p2 {id: id})”,
{batchSize:5, parallel:true});
The table results page shows these batches all executed successfully, and the results “Started streaming 1 record after 20 ms and completed after 2862 ms.” which is about 2.9s.
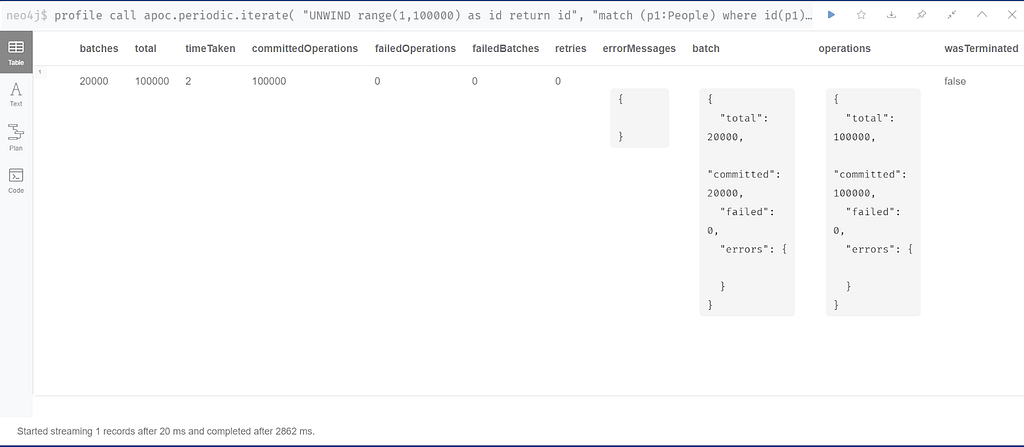
From the following query we can see that people are following one of the “celebrity” nodes i.e. one of the first 100.
MATCH (n)-[r:FOLLOWS]->(p {id:1}) RETURN n,p LIMIT 10
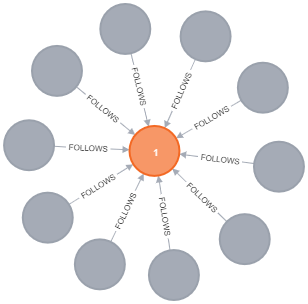
If we drop the limit, the results show how dense these nodes are (note that Browser’s defaults limit the results to 300, so this is about one third of the actual [:FOLLOWS] that were created.

Neo4j 4.3 is 6.5x faster than previous versions
To swap out the version of Neo4j running in the Docker container, substitute neo4j:4.3.1-enterprise for neo4j:3.5-enterprise and neo4j:4.2.8-enterprise in the Docker scripts (refer to end of the blog post). The results for Neo4j 3.5.18 and 4.2.8 are pretty consistent at 19263 ms and 19224 ms respectively**, which pegs Neo4j 4.3 6.5x faster in this scenario***.
**Note the 0.2% difference isn’t significant, and is down to variations in running the test on my laptop rather than any real performance difference between versions. And while the SLOTTED runtime in 4.2.8 would usually perform faster than PROCEDURE in 3.5, the lock contention is the limiting factor which is why they complete in the same amount of time.
***Using a 4GB Docker instance, results will vary depending on the system and nodes/relationships being updated and use of indexes.
Bonus: so how does it work?
I provided a very lightweight explanation of how the feature works, but as you would expect, the reality is far more complex. So for those of you who are interested I thought it was worth diving into a bit more detail.
The locking takes advantage of the abstraction, provided in previous releases of Neo4J, between the user’s view of the graph (as seen in Browser or Bloom) to one where nodes are connected by groups of relationship chains in the data stores on disk. This level of abstraction can be seen in the image below on the right that shows the internal structure of the graph.
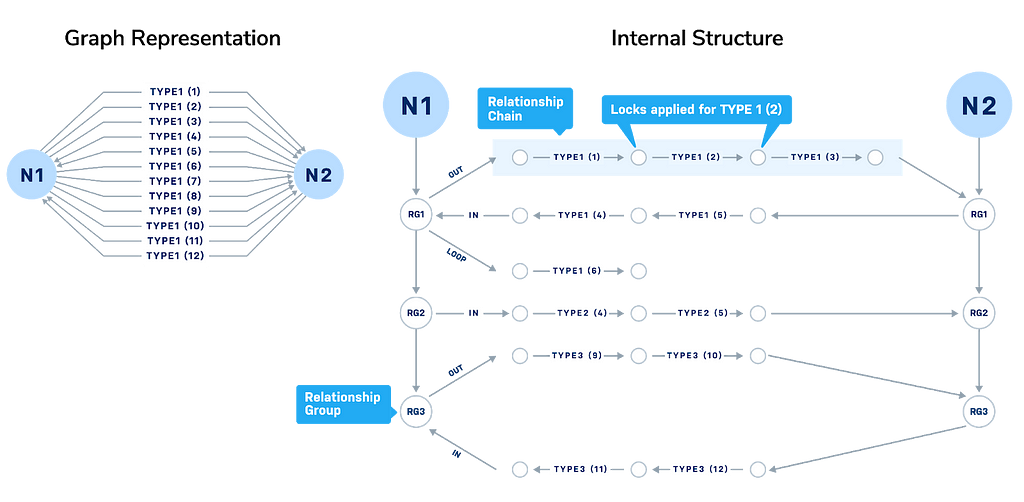
The nodes N1, N2 are stored in the file neostore.nodestore on disk in the directory datadatabase$database_name. Th≥ ese are connected by Relationships Groups RG01, RG02, RG03 and stored in the neostore.relationshipgroupstore. Think of the RGnn as “nodes” that define a group of relationships that are created for each [:RELATIONSHIP_TYPE]. For each relationship group there are up to three sets of records in the neostore.relationshiptypestore that describe the chains of linked relationships for OUT-bound, IN-bound and LOOPed relationships — these chains consist of “nodes’’ that connect relationships in a chain. Neo4j can now obtain and release locks on these “nodes” when it needs to update a relationship or node in the graph.
Valdemar Roxling, the lead developer for this feature, explained that the most challenging part was avoiding deadlocks — where one set of locks is waiting on another set of locks that are waiting on the first set of locks to be released. The key is to take the locks in the correct order, with strict rules in the sorting algorithm — attempting to explain any more would cause my head to explode and reveal our IP ;).
I will leave it there. Thanks for reading and an even bigger thanks to Valdemar for his work on this feature and helping me with the blog. Stay tuned for the next blog on Helm Charts and running Neo4j on Kubernetes.
The Docker scripts (continued)
#Note 3.5 uses dbms_memory_heap_maxSize and NOT #dbms_memory_heap_max_size
export CONTAINER=`docker run
— name neo4j-the-rock
— detach
— publish=7474:7474
— publish=7687:7687
— volume=$HERE/data:/data
— volume=$HERE/import:/var/lib/neo4j/import
— volume=$HERE/plugins:/plugins
— ulimit=nofile=40000:40000
— env=NEO4J_dbms_memory_heap_maxSize=4G
— env=NEO4J_dbms_memory_pagecache_size=2G
— env=NEO4J_ACCEPT_LICENSE_AGREEMENT=yes
— env=NEO4J_AUTH=neo4j/**e*******
neo4j:3.5-enterprise`
Cypher version: CYPHER 3.5, planner: PROCEDURE, runtime:
3.5 Started streaming 1 records after 19260 ms and completed after 19263 ms.
export CONTAINER=`docker run
— name neo4j-the-rock
— detach
— publish=7474:7474
— publish=7687:7687
— volume=$HERE/data:/data
— volume=$HERE/import:/var/lib/neo4j/import
— volume=$HERE/plugins:/plugins
— ulimit=nofile=40000:40000
— env=NEO4J_dbms_memory_heap_max__size=4G
— env=NEO4J_dbms_memory_pagecache_size=2G
— env=NEO4J_ACCEPT_LICENSE_AGREEMENT=yes
— env=NEO4J_AUTH=neo4j/**e*******
neo4j:4.2.8-enterprise`
Cypher version: CYPHER 4.2, planner: COST, runtime: SLOTTED
4.2 Started streaming 1 records after 33 ms and completed after 19224 ms.
Relationship Chain Locks: Don’t Block the Rock! was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles



SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3


