The power of the path – Part 1

Pre-Sales Engineer, Neo4j
9 min read
In the Neo4j Database, the Path is the data type that represents the Graph Structure. The Path is different than the classic data types from other database types. Working with Paths gives you extra possibilities, this is the beginning of a series of posts about the Cypher Path. First, we start with explaining the Path.
The path data type
Cypher has several types representing data in the database like property value types (String, number, etc) and the Node and the Relationship. The Path type is not a specific Entity to be stored in the database but a type to capture the structure of nodes and relationships as a result of a query.
The Path can be obtained by assigning a pattern to an identifier like MATCH p= for example:

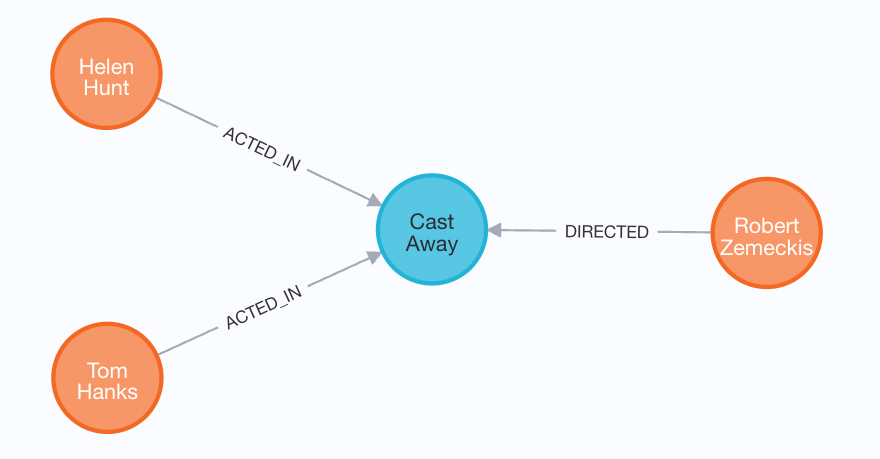
The Neo4j browser can handle the Path data type and displays the results of this query as follows:
The Neo4j browser is showing the ‘sub-graph’ as a result of this query hiding the fact that the result of this query has multiple records with a path in it. For every occurrence of the pattern you will get a record with a path returned by this query.
Path structure
Now we have seen a query returning paths what is the actual structure of a path? The internal structure of the path is an array of nodes and relationships in the way the relationship directions are specified in the cypher statement. For the query above the Paths returned have the following structure:
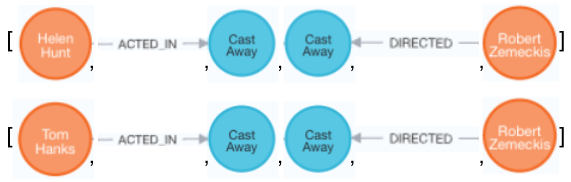
For each relationship the start and end nodes are given in the order as specified in the pattern.
Path functions
Now we explained the structure of a Path, how can we ‘work’ with it? The following functions are available:
length(path)
The length of a Path is the number of relationships in the path. In the example above it is:
length(p) = 2
nodes(path)
This function returns an array of nodes in the path in the order they are traversed:
nodes(p)=[{Node (Person Tom Hanks)} , {Node (Movie Cast Away)} , {Node (Person Robert Zemeckis)} ]
Note that we don’t have the ‘duplicate’ {Node (Movie Cast Away)} anymore.
relationships(path)
This function returns an array of relationships in the path in the order they are traversed:
relationships(p)=[{Relationship (ACTED_IN)}, {Relationship (DIRECTED)}]
With the Nodes or Relationships in an array we can apply normal array functions on them for instance getting the last Node by using nodes(p)[-1] or getting the last relationship by using relationships(p)[-1].
Relationship functions and path direction
When working with Paths, you can for example obtain the last relationship and check if the start node of the relationship has a certain label. In this case you have to be aware that the startNode(relationship) and endNode(relationship) functions are relative to the relationship and not to the Path as shown in the following example:
MATCH p=(a:Person)-[rel1:FOLLOWS]->(b:Person)<-[rel2:KNOWS]-(c:Person) RETURN p
p=[a:Person, rel1, b:Person,b:Person, rel2, c:Person]
We can now get the start node of the last relationship like this:
startNode(relationships(p)[-1]) = c:Person
When you look at the Path perspective the first node of the last relationship is b:Person. Be aware of this, the relationship startNode/endNode functions are always relative to the relationship, not to the Path!
Uniqueness
The Paths returned by a query are the results of a traversal over the graph. In a Graph everything is connected and it is not hard to imagine that we may walk over the same relationship twice. Take for example the following data with Person Nodes and a name property:

If we use the query

we expect to have the results a,b,c,d and a,b,a,b for personNames but we get:

The reason is that the query engine guarantees that per MATCH pattern it walks over a relationship once per direction in a Path. In other words the query engine is implementing the RELATIONSHIP_PATH ‘uniqueness’ in mathematical terms it is the TRAIL traversal.
It is good to know that Cypher behaves like this, take for instance the following query to find the coActors of Tom Hanks in the movie Cast Away:
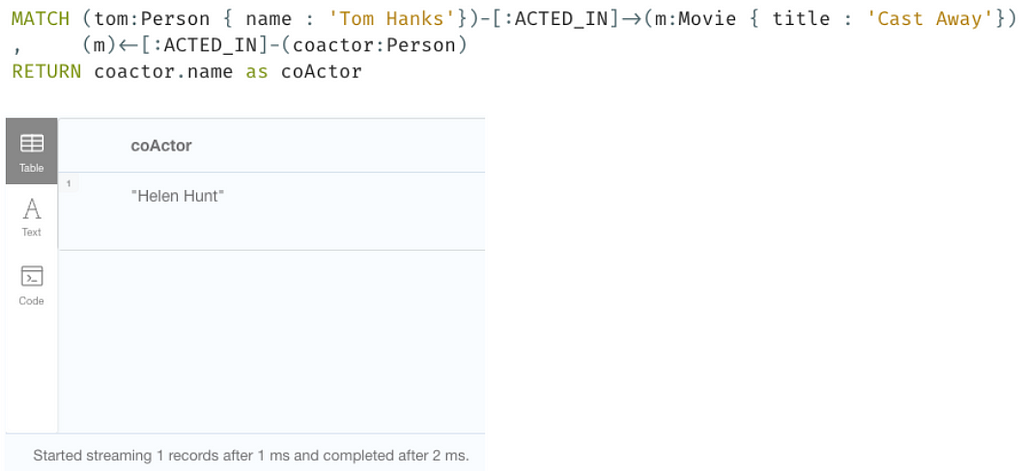
Due to the RELATIONSHIP_PATH uniqueness we know that the ‘tom ACTED_IN m’ relationship will not be walked over again when we walk to the co-actor.
It is very important to realise that the RELATIONSHIP_PATH uniqueness applies per MATCH <pattern>. When we put an extra MATCH in the query we get a different result:

The second MATCH initiates a new uniqueness rule/check giving back all the actors in the movie Cast Away.
Now that the basics of the Path is explained we dive a bit deeper in the graph by variable length paths.
Variable length paths
It is possible to specify patterns where you don’t know how deep the path will be. Because Neo4j persists the data as a graph in nodes and relationships it is possible to specify patterns like ()-[*]-() where we just walk over the graph without a limit on the depth. The database does not have to calculate the ‘joins’ between nodes at query time, it can just walk over the persisted relationships without using indexes.
As mentioned you can specify a variable path with a ‘*’ in the relationship section. A ‘*’ means paths with a length 1 to infinite and is a shorthand for “*1..”. It is also possible to specify the minimum and maximum depth of the traversal with ‘*min..max’. If max is omitted then the length is infinite.
[*1..3] means minimal length is 1 and maximum length is 3.
[*3] (is *3..3) means only paths with length 3.
Imagine that we have a database with the following nodes and relationships
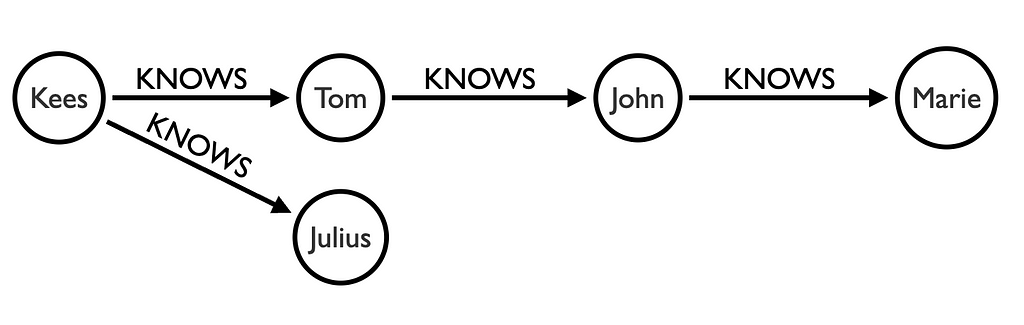
When we do a MATCH p=(a:Person {name :"Kees" })-[:KNOWS*1..2]->(b) we will get back paths with a length of 1 and a length of 2:
Kees,Tom
Kees,Tom,John
Kees,Julius
When we do a MATCH p=(a:Person {name :"Kees" })-[:KNOWS*]->(b) we will get back the following paths:
Kees,Tom
Kees,Tom,John
Kees,Tom,John,Marie
Kees,Julius
As you see the Cypher engine goes first to the deepest level also known as Depth First Search (DFS).
When we do a MATCH p=(a:Person {name :"Kees" })-[:KNOWS*3]->(b) we only searching for paths with a length of 3. So with this data we will get back the following path:
Kees, Tom, John, Marie
Path length 0
It is possible to specify a 0 for the minimum length (or fixed length) of a Path. This is in some cases useful where you just want to let the match <pattern> be successful even if there is no path found from a node.
MATCH (tom:Person {name : ”Tom Hanks” )-[:FOLLOWS*0..1]->(ff:Person)
…
In this way the pattern behaves like an OPTIONAL MATCH:OPTIONAL MATCH (tom:Person {name: ”Tom Hanks” )-[:FOLLOWS]->(ff:Person)
…
It can be useful to apply the path length 0 when using pattern comprehension
MATCH (tom:Person {name : ”Tom Hanks” )WITH tom, [(tom)-[:FOLLOWS*0..1]->(f:Person) | f.name ] as tomFollows
…
Typically this construct can be applied to avoid cartesian products when you have a query with a lot of optional matches after each other as explained in the Cypher Query Optimisations article (under “Multiple OPTIONAL MATCH statements”).
An important thing to remember when using path length 0 is that when the Path length is 0 the ‘single’ Node must have all the Labels specified in the pattern. In the example above we expect the Person Node in the following pattern something else is happening:
MATCH (tom:Person {name : ”Tom Hanks” )-[:FOLLOWS*0..1]->(ff:Writer)
…
This query will only return a result for path length 0 when there is a Node tom with a Person and a Writer label! It is possible to avoid this by not specifying the Writer label:
MATCH (tom:Person {name : ”Tom Hanks” )-[:FOLLOWS*0..1]->(ff)
It is important to Model your graph properly so that in this case the FOLLOWS relationship is already enough information to find the requested pattern.
Traversal explosion
As mentioned the query engine engine will give you back ‘every possible path’ which is in most cases preferred. But there are use cases where it is not beneficial. Let assume the following graph where the red nodes are Locations and the beige nodes are Customers.
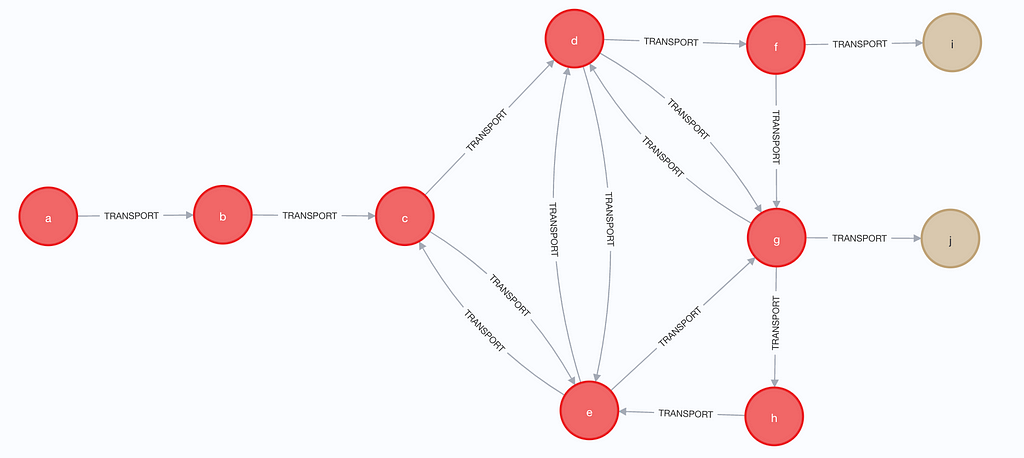
When we want to traverse the graph from node ‘a’ with a variable depth then we see a lot of possible paths as in shown in the table below:

So even with this set of 10 nodes and 16 relationships we already get 1102 possible paths. Imagine if you have a cluster of 30 nodes pointing to each other instead of the 6 nodes above.
When we want to know to which customers something is transported in this example using the default query engine the query engine has to evaluate a lot of paths to get to the Customer Nodes. In the next article dive deeper on some use case where we use other UNIQUENESS approaches via the apoc.path.expand procedure.
If you have questions regarding Cypher Paths, you can always head to the Cypher topic on Neo4j Discord channel to chat directly or go to the Neo4j Community Forum.
The Power of the Path — part 1 was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles




SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3

