Turn a Harry Potter book into a knowledge graph

Graph ML and GenAI Research, Neo4j
12 min read
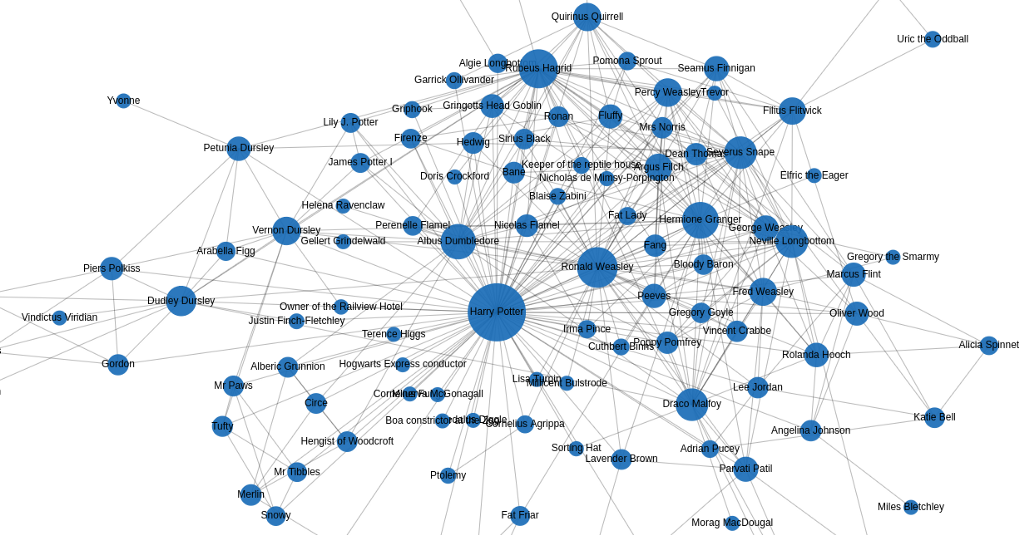
Learn how to combine Selenium and SpaCy to create a Neo4j knowledge graph of the Harry Potter universe
Most likely, you have already seen the Game of Thrones network created by Andrew Beveridge.
Andrew constructed a co-occurrence network of book characters. If two characters appear within some distance of text between each other, we can assume that they are somehow related or they interact in the book.
I decided to create a similar project but choose a popular book with no known (at least to me) network extraction. So, the project to extract a network of characters from the Harry Potter and the Philosopher’s Stone book was born.

I did a lot of experiments to decide the best way to go about it. I’ve tried most of the open-source named entity recognition models to compare which worked best, but in the end, I decided that none were good enough.
Luckily for us, the Harry Potter fandom page contains a list of characters in the first book. We also know in which chapter they first appeared, which will help us even further disambiguate the characters.
Armed with this knowledge, we will use SpaCy’s rule-based matcher to find all mentions of a character. Once we have found all the occurrences of entities, the only thing left is to define the co-occurrence metric and store the results in Neo4j.
We will use the same co-occurrence threshold as was used in the Game of Thrones extraction. If two characters appear within 14 words of each other, we will assume they have interacted somehow and store the number of those interactions as the relationship weight.
Agenda
- Scrape Harry Potter fandom page
- Preprocess book text (Co-reference resolution)
- Entity recognition with SpaCy’s rule-based matching
- Infer relationships between characters
- Store results to Neo4j graph database
I have prepared a Google Colab notebook if you want to follow along.
Harry Potter fandom page scraping
We will use Selenium for web scraping. As mentioned, we will begin by scraping the characters in the Harry Potter and the Philosopher’s Stone book. The list of characters by chapter is available under the CC-BY-SA license, so we don’t have to worry about any copyright infringement.
We now have a list of characters with information on which chapter they first appeared. Additionally, each of the characters has a web page with detailed information about the character.
For example, if you check out the Hermione Granger page, you can observe a structured table with additional information. We will use the alias section for the entity extraction and add other character details like house and blood type to enrich our knowledge graph.
I haven’t added all code used to enrich information in this gist for readability and clarity. I have also added some exceptions for aliases. For example, Harry Potter has the following alias:
- Gregory Goyle (under disguise of Polyjuice)
We want to ignore all the aliases under the disguise of Polyjuice. It seems he also told Stanley Shunpike that he was Neville Longbottom, which we will also skip.
Before we continue with named entity extraction from the book, we will store the scraped information about the characters to Neo4j.
Attributes:
- name
- url
- aliases
- nationality
- blood-type
- gender
- species
Relationships:
- House
- Loyalty
- Family
If you have some experience with Cypher, you might have noticed that we have stored information such as blood, gender, aliases, but also family and loyalty relationships to our graph.
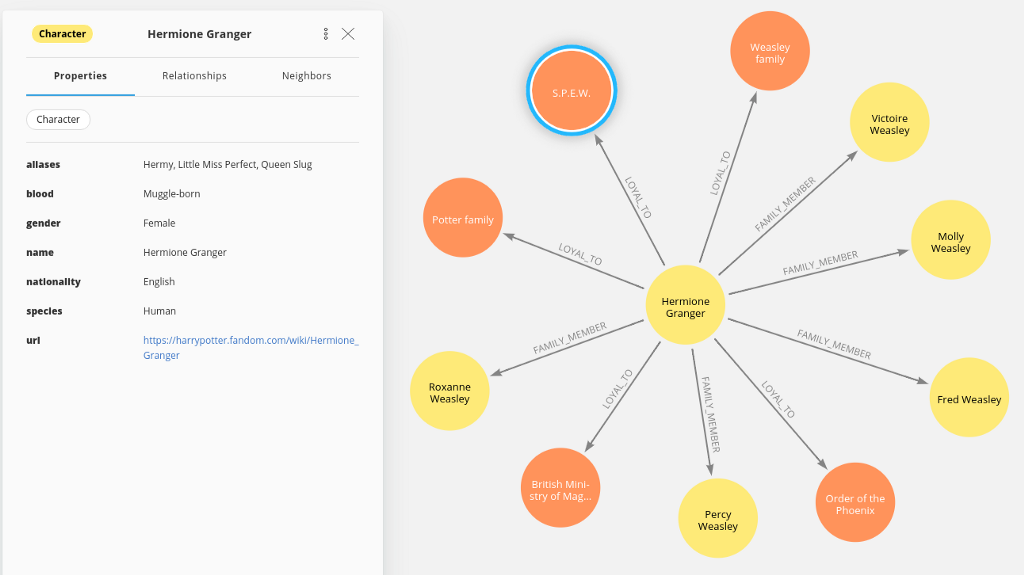
It seems that Hermione Granger is also known as Little Miss Perfect and is loyal to the Society for the Promotion of Elfish Welfare. Unfortunately, the data has no timeline, so Fred Weasley is already brother-in-law to Little Miss Perfect.
Text preprocessing
First of all, we have to get our hands on the text from the book. I’ve found a GitHub repository that contains the text of the first four Harry Potter books.
There is no license attached to the data, so I will assume we can use the data for educational purposes within the limits of fair use. If you actually want to read the book, please go and buy it.
Getting the text from a GitHub file is quite easy:
We have to be careful to provide the link to the raw text content, and it should work.
When I first did the entity extraction, I forgot to use the co-reference resolution technique beforehand. Co-reference resolution is the task of determining linguistic expressions that refer to the same real-world entity.
In simple terms, we replace the pronouns with the referenced entities.
For a real-world example, check out my Information extraction pipeline post.
From text to knowledge. The information extraction pipeline
I’ve been searching for open-source co-reference resolution models, but as far as I know, there are only two. The first is NeuralCoref that works on top of SpaCy, and AllenNLP provides the second model. Since I have already used NeuralCoref before, I decided to look at how the AllenNLP model works.
Unfortunately, I quickly ran out of memory (Colab has 16GB RAM) when I input a whole chapter into the AllenNLP model. Then I sliced a chapter into a list of sentences, but it worked really slow, probably due to using the BERT framework.
So, I defaulted to use NeuralCoref, which can easily handle a whole chapter and works faster. I have copied the code I have already used before:
Now that we have our text ready, it is time to extract mentioned characters from the text.
Entity recognition with spaCy’s rule-based matching
First, I wanted to be cool and use a Named Entity Recognition model. I’ve tried models from SpaCy, HuggingFace, Flair, and even Stanford NLP.
None of them worked well enough to satisfy my requirements. So instead of training my model, I decided to use SpaCy’s rule-based pattern matching feature.
We already know which characters we are looking for based on the data we scraped from the HP fandom site. Now we just have to find a way to match them in the text as perfectly as possible.
We have to define the text patterns for each of the character.
First, we add the full name as the pattern we are looking for. Then we split the name by whitespace and create a pattern out of every word of the term. So, for example, if we are defining matcher patterns for Albus Dumbledore, we will end up with three different text patterns that could represent the given character:
- Full name: Albus Dumbledore
- First name: Albus
- Last name: Dumbledore
There are some exceptions. I have defined a list of stop words that should not be included in the single word pattern for a given character.
For example, there is a “Keeper of the Zoo” character present in the book. It might be pretty intuitive not to define words like “of” or “the” as the matcher patterns of an entity.
Next, we want all single words to be title-cased. This is to avoid all mentions of the color “black” being a reference to “Sirius Black”. Only if the “Black” is title-cased, will we assume that “Sirius Black” is referenced. It is not a perfect solution as “Black” could be title-cased due to being at the start of a sentence, but it is a good enough solution.
A particular case I’ve introduced is that “Ronald Weasley” is mainly referred to as “Ron” in the text. Lastly, we do not split entities like “Vernon Dursley’s secretary” or “Draco Malfoy’s eagle owl”.
There are two obstacles we must overcome with this approach. The first issue is that the following text: “Albus Dumbledore is a nice wizard”
will produce three matches. We will get three results because we have used the whole and parts of names in our matcher pattern. To solve this issue, we will prefer more extended entities.
If there is a match that composes of multiple words and another match consisting of a single word in the same place, we will prefer the one with multiple words.
My implementation of longer-word entities prioritization is very basic. First, it checks if a more extended entity already exists. It then checks if the current result is longer than any existing entities in the same position, and lastly appends a new result if there are no existing entities yet.
What is interesting is the very last “else” clause. Sometimes, more entities are assigned to a single position. Consider the following sentence:
“Weasley, get over here!”
There are many Weasley characters that we can choose from. This is the second issue we must overcome. It mostly happens when a person is referenced by their last name, and there are many characters with that last name.
We must come up with a generic solution for entity disambiguation.
This is a bit longer function. We start by identifying which entities require disambiguation.
I introduced a unique logic disambiguating the “Dursley” term. If “Mr.” is present before the “Dursley” term, then we reference Vernon, and if “Mrs.” is present, we choose “Petunia”.
Next, we have a more generic solution. The algorithm assigns the reference to the nearest neighbor out of the options.
For example, suppose we can choose between “Harry Potter”, “James Potter”, and “Lily Potter”. In that case, the algorithm identifies the nearest of those three entities in the text and assigns the current item its value. There are some exceptions where their full or first name is not referenced within the same chapter, and I have added hard-coded options as a last resort.
Infer relationships between characters
We are finished with the hard part. Inferring relationships between characters is very simple. First, we need to define the distance threshold of interaction or relation between two characters. As mentioned, we will use the same distance threshold as was used in the GoT extraction.
That is, if two characters co-occur within the distance of 14 words, then we assume they must have interacted. I have also merged entities not to skew results.
What do I mean by joining entities? Suppose we have the following two sentences:
“Harry was having a good day. He went to talk to Dumbledore in the afternoon.”
Our entity extraction process will identify three entities, “Harry”, “He” as a reference to Harry, and “Dumbledore”. If we took the naive approach, we could infer two interactions between Harry and Dumbledore as two references of “Harry” are close to “Dumbledore”.
However, I want to avoid that, so I have merged entities in a sequence that refers to the same character as a single entity. Finally, we have to count the number of interactions between the pairs of characters.
Store results to Neo4j graph database
We have extracted the interactions network between character, and the only thing left is to store the results into a graph database. The import query is very straightforward as we are dealing with a monopartite network.
If you are using the Colab notebook I have prepared, then it would be easiest to create either a free Neo4j Sandbox or free Aura database instance to store the results.
Let’s visualize the interaction network to examine the results.
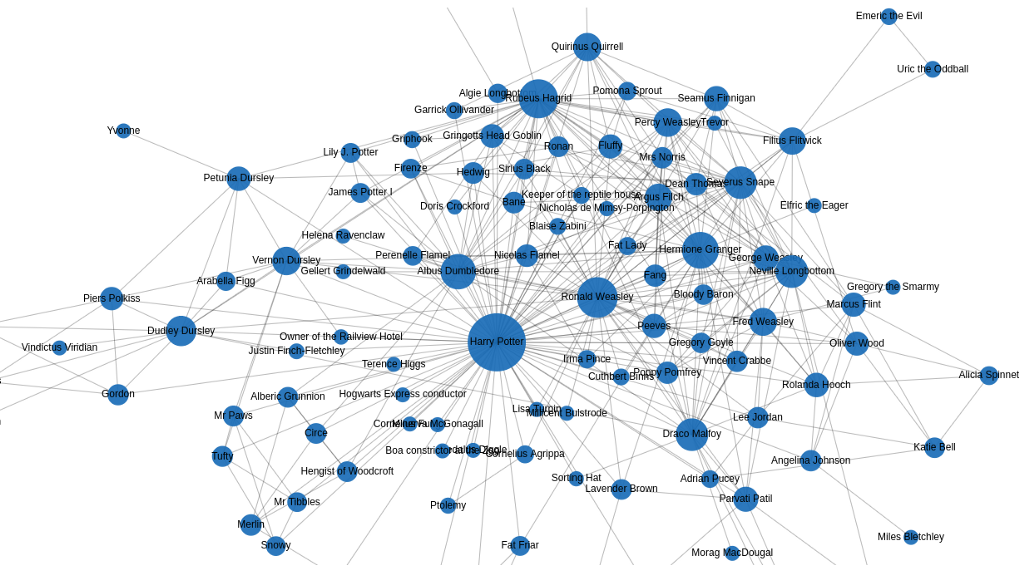
At first glance, the results look pretty cool. In the center of the network is Harry Potter, which is understandable as the book is mostly from his point of view.
I’ve noticed I should have added some additional stop words in the matcher pattern, but hey, you live, and you learn.
Conclusion
I am quite proud of how good the rule-based matching based on predefined entities turned out. As always, the code is available on GitHub.
You could try this approach on the second or third book. Probably the only thing that would need a bit of fine-tuning is the entity disambiguation process.
Stay tuned till next time, when we will perform a network analysis of the Harry Potter universe.
You can use the Neo4j graph algorithms playground application to test out graph algorithms on the Harry Potter knowledge graph if you don’t want to wait.
Thinking about building a knowledge graph?
Download The Developer’s Guide: How to Build a Knowledge Graph for a step-by-step walkthrough of everything you need to know to start building with confidence.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



