Enhanced QA integrating unstructured knowledge graph using Neo4j and LangChain

Data Scientist
7 min read
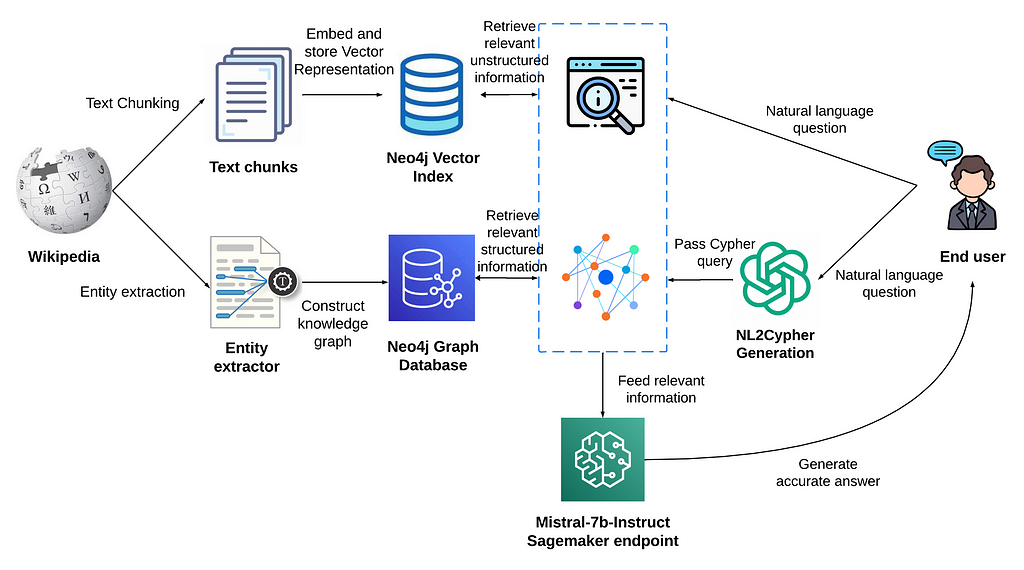
Neo4j Vector Index and GraphCypherQAChain for optimizing the synthesis of information for informed response generation with Mistral-7b
Information retrieval and knowledge extraction is a growing field, which has witnessed a notable shift with the advent of Large Language Models (LLMs) and knowledge graphs, particularly within the context of multi-hop question answering.
In this blog, we’ll walk you through a project that leverages the robust capabilities of Neo4j Vector Index and Neo4j Graph Database to implement a retrieval-augmented generation system, aiming to provide precise and contextually rich answers to user queries.
This system employs a vector similarity search to search through unstructured information and concurrently accesses a graph database to retrieve structured data, ensuring that the responses are not only comprehensive but also anchored in validated knowledge.
This approach is particularly vital for addressing multi-hop questions, where a single query can be broken down into multiple sub-questions and may require information from numerous documents to generate an accurate answer.
In an era where data is both abundant and complex, the above system stands as a pivotal tool, ensuring that user queries are met with answers that are a seamless blend of wide-reaching knowledge and validated accuracy, thereby bridging the gap between unstructured data and structured knowledge graphs.
As a final step, the system passes the retrieved unstructured and structured information into a new large language model, Mistral-7b, for text generation. This integration ensures that the responses generated are not only informed by the vast knowledge encapsulated in the model but are also finely tuned and enriched by the specific, real-time data retrieved from the vector and graph databases, providing a nuanced, accurate, and contextually relevant user experience.
Neo4j vector index
The Neo4j Vector Index has emerged as a pivotal tool in the realm of retrieval-augmented generation (RAG) applications, particularly in handling both structured and unstructured data. The LangChain library, a prominent framework for building Large Language Model (LLM) applications, has integrated full support for Neo4j Vector Index, streamlining data ingestion and querying in RAG applications.
This integration facilitates efficient data ingestion into Neo4j Vector Index and enables the construction of effective RAG applications, providing real-time, accurate, and contextually relevant answers by leveraging both structured and unstructured data.
GraphCypherQAChain
The GraphCypherQAChain class serves a functional purpose in the realm of querying graph databases, particularly Neo4j, using natural language questions. It uses LLM to generate Cypher queries from input questions, executes them against a Neo4j graph database, and provides answers based on the query results.
This utility allows users to retrieve specific data without needing to write complex Cypher queries, thereby making the data stored in the graph database more accessible and easier to interact with.
Mistral 7B
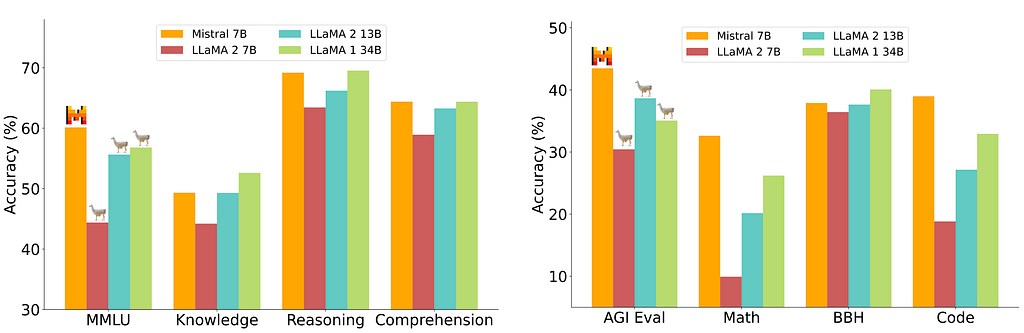
Mistral 7B is a recent large language model recognized for its remarkable performance across a spectrum of benchmarks, demonstrating proficiency in handling various language tasks and queries, as seen in the figure below.
In the architecture of Retrieval-Augmented Generation (RAG), Mistral 7B stands pivotal by synthesizing and generating text based on the information retrieved from vector and graph search, ensuring the output is not only rich in context but also precisely tailored to the user’s query. It effectively bridges the gap between unstructured data and structured knowledge graphs, providing answers that are a blend of pre-trained knowledge and real-time, validated data.
Implementation
Let’s start by installing the dependencies.
Refer to my GitHub repo for the complete Jupyter Notebook.
%pip install langchain openai wikipedia tiktoken neo4j python-dotenv transformers %pip install -U sagemaker
Neo4j vector index
We will start by importing the requisite libraries and modules, setting a foundation for interfacing with the dataset preparation, Neo4j Vector Index, and using the text generation capabilities of Mistral 7B. With dotenv, it securely loads environment variables, safeguarding sensitive credentials for the OpenAI API and Neo4j database.
import os
import re
from langchain.vectorstores.neo4j_vector import Neo4jVector
from langchain.document_loaders import WikipediaLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
from dotenv import load_dotenv
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
os.environ["NEO4J_URI"] = os.getenv('NEO4J_URI')
os.environ["NEO4J_USERNAME"] = os.getenv('NEO4J_USERNAME')
os.environ["NEO4J_PASSWORD"] = os.getenv('NEO4J_PASSWORD')
Here, we decided to work with a Wikipedia page of Leonhard Euler for our experiment. We use the bert-base-uncased model for tokenizing the text. The WikipediaLoader loads the raw content of the specified page, which is then chunked into smaller text pieces using RecursiveCharacterTextSplitter from LangChain.
This splitter ensures that each chunk is maximized to 200 tokens with an overlap of 20 tokens, adhering to context window limits for embedding models and making sure that the continuity of the context is not lost.
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def bert_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
raw_documents = WikipediaLoader(query="Leonhard Euler").load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 200,
chunk_overlap = 20,
length_function = bert_len,
separators=['nn', 'n', ' ', ''],
)
documents = text_splitter.create_documents([raw_documents[0].page_content])
The chunked documents are instantiated into the Neo4j vector index as nodes. It uses the core functionalities of Neo4j graph database and OpenAI embeddings to construct this vector index.
# Instantiate Neo4j vector from documents
neo4j_vector = Neo4jVector.from_documents(
documents,
OpenAIEmbeddings(),
url=os.environ["NEO4J_URI"],
username=os.environ["NEO4J_USERNAME"],
password=os.environ["NEO4J_PASSWORD"]
)
After ingesting the documents in the vector index, we perform a vector similarity search for a sample user query and retrieve the top 2 most similar documents.
query = "Who were the siblings of Leonhard Euler?"
vector_results = neo4j_vector.similarity_search(query, k=2)
for i, res in enumerate(vector_results):
print(res.page_content)
if i != len(vector_results)-1:
print()
vector_result = vector_results[0].page_content

Build knowledge graph
Highly inspired by the NaLLM project, we use their open-source project to construct a knowledge graph from unstructured data.
Below is a knowledge graph constructed using a single chunk of a document from a Wikipedia article of Leonhard Euler.
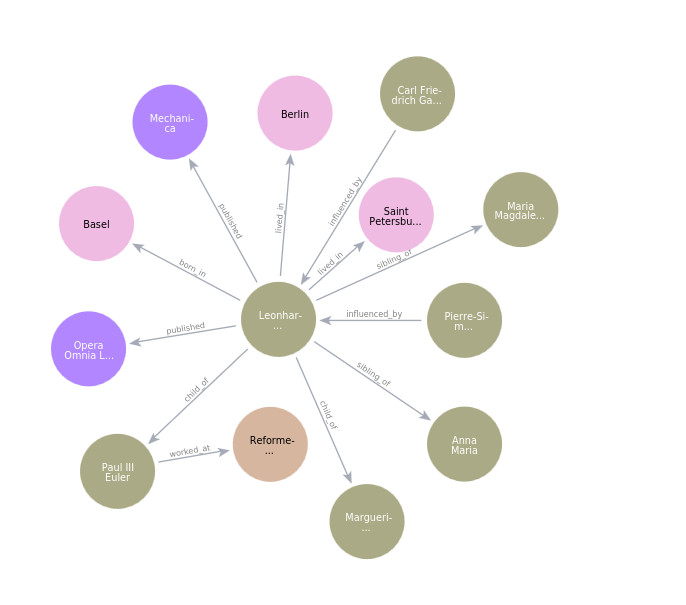
After studying the project in-depth, I learned a lot about building knowledge graphs using LLMs. For instance, here is the prompt to capture entities and relationships from unstructured text:
"""
You are a data scientist working for a company that is building a graph database. Your task is to extract information from data and convert it into a graph database.
Provide a set of Nodes in the form [ENTITY_ID, TYPE, PROPERTIES] and a set of relationships in the form [ENTITY_ID_1, RELATIONSHIP, ENTITY_ID_2, PROPERTIES].
It is important that the ENTITY_ID_1 and ENTITY_ID_2 exists as nodes with a matching ENTITY_ID. If you can't pair a relationship with a pair of nodes don't add it.
When you find a node or relationship you want to add try to create a generic TYPE for it that describes the entity you can also think of it as a label.
Example:
Data: Alice lawyer and is 25 years old and Bob is her roommate since 2001. Bob works as a journalist. Alice owns a the webpage www.alice.com and Bob owns the webpage www.bob.com.
Nodes: ["alice", "Person", {"age": 25, "occupation": "lawyer", "name":"Alice"}], ["bob", "Person", {"occupation": "journalist", "name": "Bob"}], ["alice.com", "Webpage", {"url": "www.alice.com"}], ["bob.com", "Webpage", {"url": "www.bob.com"}]
Relationships: ["alice", "roommate", "bob", {"start": 2021}], ["alice", "owns", "alice.com", {}], ["bob", "owns", "bob.com", {}]
"""
There are a lot of functions which are interesting and can be improved at the same time.
Neo4j DB QA chain
Next, we import the necessary libraries to set up the Neo4j DB QA Chain.
from langchain.chat_models import ChatOpenAI from langchain.chains import GraphCypherQAChain from langchain.graphs import Neo4jGraph
Once the graph is constructed, we need to connect to the Neo4jGraph instance and visualize the schema.
graph = Neo4jGraph(
url=os.environ["NEO4J_URI"], username=os.environ["NEO4J_USERNAME"], password=os.environ["NEO4J_PASSWORD"]
)
print(graph.schema)
Node properties are the following:
[{'labels': 'Person', 'properties': [{'property': 'name', 'type': 'STRING'},
{'property': 'nationality', 'type': 'STRING'},
{'property': 'death_date', 'type': 'STRING'},
{'property': 'birth_date', 'type': 'STRING'}]},
{'labels': 'Location', 'properties': [{'property': 'name', 'type': 'STRING'}]},
{'labels': 'Organization', 'properties': [{'property': 'name', 'type': 'STRING'}]},
{'labels': 'Publication', 'properties': [{'property': 'name', 'type': 'STRING'}]}]
Relationship properties are the following:
[]
The relationships are the following:
['(:Person)-[:worked_at]->(:Organization)',
'(:Person)-[:influenced_by]->(:Person)',
'(:Person)-[:born_in]->(:Location)',
'(:Person)-[:lived_in]->(:Location)',
'(:Person)-[:child_of]->(:Person)',
'(:Person)-[:sibling_of]->(:Person)',
'(:Person)-[:published]->(:Publication)']
The GraphCypherQAChain abstracts all the details and outputs a natural language response for a natural language question(NLQ). However, internally, it uses LLMs to generate a Cypher query for that question and retrieves the result from the graph database, and finally uses that result to generate the final natural language response, again using an LLM.
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
graph_result = chain.run("Who were the siblings of Leonhard Euler?")

graph_result 'The siblings of Leonhard Euler were Maria Magdalena and Anna Maria.'
Mistral-7B-Instruct
We set up the Mistral-7B endpoint from Hugging Face within the AWS SageMaker environment.
import json
import sagemaker
import boto3
from sagemaker.huggingface import HuggingFaceModel, get_huggingface_llm_image_uri
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
hub = {
'HF_MODEL_ID':'mistralai/Mistral-7B-Instruct-v0.1',
'SM_NUM_GPUS': json.dumps(1)
}
huggingface_model = HuggingFaceModel(
image_uri=get_huggingface_llm_image_uri("huggingface",version="1.1.0"),
env=hub,
role=role,
)
The final response is crafted by constructing a prompt that includes an instruction, relevant data from the vector index, relevant information from the graph database, and the user’s query.
This prompt is then passed to the Mistral-7b model, which generates a meaningful and accurate response based on the provided information.
mistral7b_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.g5.4xlarge",
container_startup_health_check_timeout=300,
)
query = "Who were the siblings of Leonhard Euler?"
final_prompt = f"""You are a helpful question-answering agent. Your task is to analyze
and synthesize information from two sources: the top result from a similarity search
(unstructured information) and relevant data from a graph database (structured information).
Given the user's query: {query}, provide a meaningful and efficient answer based
on the insights derived from the following data:
Unstructured information: {vector_result}.
Structured information: {graph_result}.
"""
response = mistral7b_predictor.predict({
"inputs": final_prompt,
})
print(re.search(r"Answer: (.+)", response[0]['generated_text']).group(1))
The siblings of Leonhard Euler were Maria Magdalena and Anna Maria.
Key takeaways
The integration of Neo4j Vector Index and GraphCypherQAChain with Mistral-7b provides a robust system for handling complex data that effectively bridges the gap between voluminous unstructured data and intricate graph knowledge, providing a comprehensive and accurate response to user queries by synthesizing information from both data sources.
Utilizing Neo4j for both vector similarity search and graph database retrieval ensures that the responses generated are not only informed by the vast pre-trained knowledge of Mistral-7b but are also contextually enriched and validated by real-time data from the vector and graph databases.
Finally, I aim to experiment with multi-hop queries in future experiments, as initially establishing a modular pipeline was necessary to adapt to the rapidly growing field of AI.
Summary
This project underscores the potent combination of Neo4j Vector Index and LangChain’s GraphCypherQAChain to navigate through unstructured data and graph knowledge, respectively, and subsequently use Mistral-7b for generating informed and accurate responses.
By employing Neo4j for retrieving relevant information from both a vector index and a graph database, the system ensures that the generated responses are not only contextually rich but also anchored in validated, real-time knowledge.
The implementation demonstrates a practical application of retrieval-augmented generation, where the synthesized information from diverse data sources is utilized to generate responses that are a harmonious blend of pre-trained knowledge and specific, real-time data, thereby enhancing the accuracy and relevance of the responses to user queries.
References
- Neo4j and Large Language Models (LLMs)
- Knowledge Graphs & LLMs: Harnessing Large Language Models with Neo4j
- Knowledge Graphs & LLMs: Fine-Tuning Vs. Retrieval-Augmented Generation
- Knowledge Graphs & LLMs: Multi-Hop Question Answering
- LangChain Library Adds Full Support for Neo4j Vector Index
- Mistral 7B
- Knowledge Graph Construction Demo from raw text using an LLM
Enhanced QA Integrating Unstructured and Graph Knowledge Using Neo4j and LangChain was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report



