
User Segmentation Based on Node Roles in the Peer-to-Peer Payment Network

Graph ML and GenAI Research, Neo4j
13 min read
Knowing your users is vital to any business. When your users can interact with each other on a social media platform, content sharing platform, or even work-related platforms, you can construct a network between your users based on their interactions and extract graph-based features to segment your users. Of course, these same approaches can be applied to other platforms that are not user-centric.
In this blog post, I will walk you through the user segmentation process of a peer-to-peer payment platform through network analysis.
On a peer-to-peer platform, users can digitally transfer money online to anyone else on the platform. Such platforms have gained a lot of popularity in recent years. Examples of real-world peer-to-peer payment platforms are Venmo, PayPal, and Revolut.
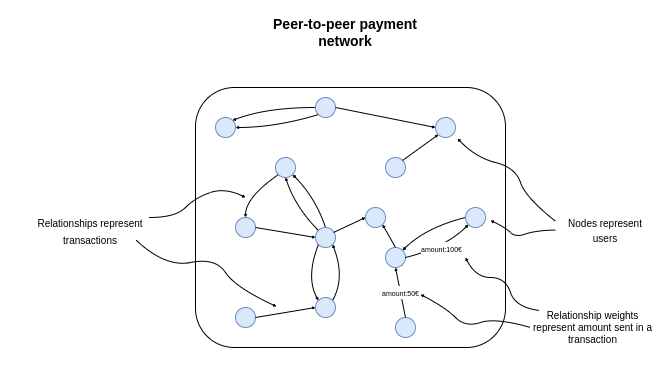
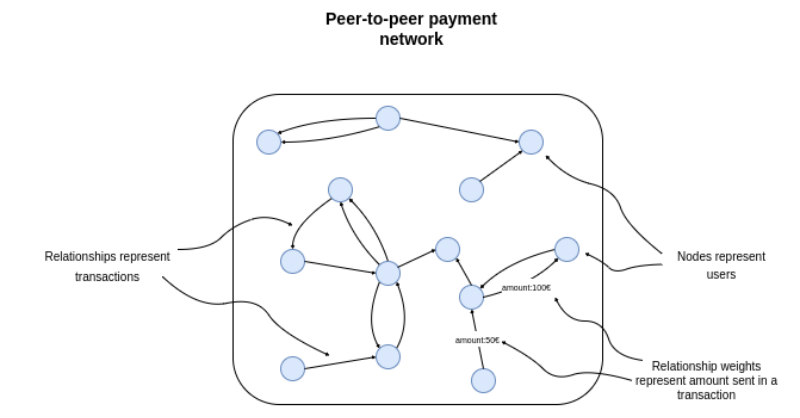
We can represent the transactions between users as a network where nodes represent users, and the relationships represent transactions. The connections have a weight or a property that contains the information about the total amount sent. If your dataset includes the timeline information, you could also add the dates of transactions to the relationships.
In order to segment the users in the network, we need to come up with features that describe the role of users in the network. In general, we could take advantage of running unsupervised algorithms that auto-magically encode node positions and roles in the network as a vector per node.
However, the problem with the unsupervised approach to feature engineering is that it’s hard to explain the results. For this reason, we will manually construct feature vectors for users.
We can encode anything in the feature vectors we deem descriptive of user roles in the network. For example, in a peer-to-peer payment network, it makes sense to encode how many transactions and their values a user has but also look at which users connect to different communities and act as a bridge between them.
In this example, we will combine some simple statistics like the average transaction value of a user with outputs of graph algorithms like the Betweenness Centrality to encode the user roles in the network.
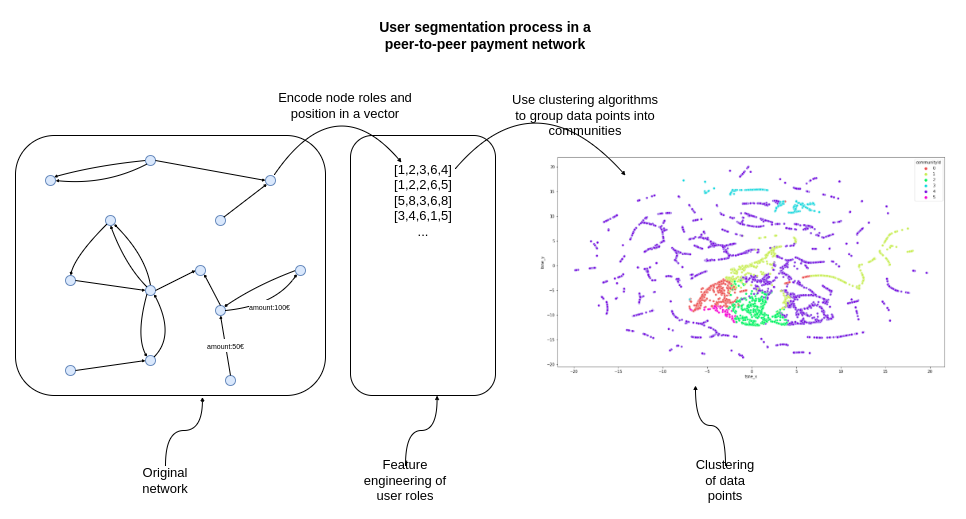
As mentioned, we need to encode user roles and positions in the network as vectors. In this post, we will manually construct features describing nodes. These features are:
- Average transaction amount
- Years since first transaction
- Weighted in-degree (total amount received)
- Weighted out-degree (total amount sent)
- Betweenness centrality
- Closeness centrality
We will use these six features to encode node roles and positions in the network. The average transaction amount and the years since the first transaction features are used to capture how old they accounts are and how much on average they send. Next, we will use the weighted in and out-degrees to encode the total amount sent and received by the user. Lastly, we will use the Closeness and Betweenness centralities algorithms to encode the node position in the network.
After the feature engineering process is completed, we will use the K-means algorithm to cluster the data points into groups or communities of users. These communities will represent various segments of users on the platform.
Environment setup
We will be using Neo4j as the database to store the peer-to-peer network. Therefore, I suggest you download and install the Neo4j Desktop application if you want to follow along with the code examples.
The dataset is available as a database dump. It is a variation of the database dump available on Neo4j’s product example GitHub to showcase fraud detection.
I wrote a post about restoring a database dump in Neo4j Desktop a while back if you need some help. After you have restored the database dump, you will also need to install the Graph Data Science and APOC libraries. Make sure you are using version 2.1.0 of the GDS library or later.
The code with the examples in this post is available on GitHub.
blogs/p2p-network-analysis.ipynb at master · tomasonjo/blogs
You will need to have the following three Python libraries installed:
- graphdatascience: Neo4j Graph Data Science Python client
- seaborn: Visualization library
- scikit-learn: We will use t-SNE dimensionality reduction
Setting up the connection to Neo4j
Now we are ready to start coding. First, we need to define the connections to the Neo4j instance with the graphdatascience library.
We need to fill in the credentials to define the connection to the Neo4j instance. Make sure to change the passwordvariable to the appropriate value. I like to print the gds.version() method to make sure that the connection is valid and the target database has the Graph Data Science library installed.
We can quickly evaluate the populated graph schema with the apoc.meta.stats procedure.
There are 33,732 users in the database and 102,832 P2P transactions. There could be multiple P2P transactions between a pair of users. Therefore, we are dealing with a directed weighted multigraph. We have some additional information about the users available, such as which IPs, credit cards, and devices they have used.
Feature engineering
We will now move on to calculating user features used for segmentation. The first two features we will extract are the account age, calculated by looking at the first transaction, and the average transaction amount. We will use a single Cypher statement to calculate them and store them as node properties in the database.
The gdsobject has a run_cyphermethod that allows you to execute any Cypher statements.
The remaining four attributes will be calculated by executing graph algorithms available in the Graph Data Science library. The graphdatascience library allows you to execute any GDS procedure and algorithm using pure Python code. I wrote an article on mapping GDS syntax from Cypher statements to pure Python code to help you with the transition.
First, we need to project an in-memory graph. The projected graph schema will be relatively simple and will contain only User nodes and P2P relationships.
In addition, we will include node properties accountYears and avgTransactionAmount and relationship property totalAmount in the projection.
Since we want to use network features like the Betweenness and Closeness centrality for user segmentation, we will first evaluate how connected our network is using the Weakly Connected Components algorithm. The Weakly Connected Components algorithm is used to find disconnected parts or islands in the network and can help you evaluate how connected the network is overall.
We will use the mutate mode of the Weakly Connected Components algorithm, which stores the results to the projected graph and returns high-level statistics of the algorithm result.
There are 7743 disconnected components in our P2P network.
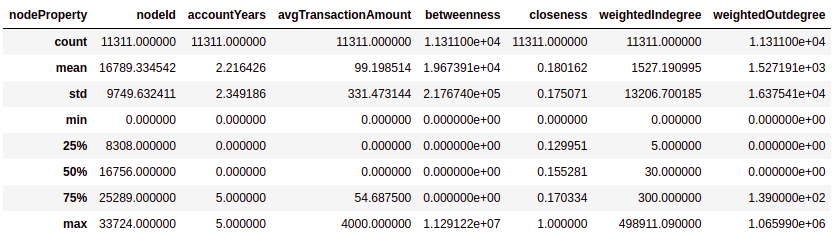
That is a high and slightly unexpected amount of disconnected components, as there are only around 30,000 users in the network. The largest component has 11,311 members, about 30 percent of the population, while other components are tiny and contain only a few members. We notice that 99 percent of communities have 12 or fewer members.
Since we want to segment our users based on their network features, we will focus our analysis on the largest component only and ignore the rest. This is because the network attributes are not very descriptive when dealing with small components that contain five members. More importantly, I want to show you how to filter the largest component in your projected graph. However, you could always run your analysis on the whole network if you wanted to, or if that was the requirement.
The subgraph filter projection procedure allows us to filter projected graphs on mutated properties. In this example, we will select only nodes that are part of the largest component. Then, the subgraph filter projection creates a new graph based on the specified predicates.
First, we needed to fetch the id of the largest component. We can retrieve mutated properties from the projected graph using the gds.graph.streamNodeProperty method.
Next, we applied a simple aggregation and sorting to extract the particular component id, and then used it as an input to the subgraph filter projection method.
Now that we have the projected graph containing only the largest component ready, we can extract the network features. We will begin by calculating the weighted in and out-degrees. Again, we will use the mutate mode of the algorithm to store the results back to the projected graph.
The only two features we need to calculate are the Betweenness and Closeness centralities. The Betweenness centrality is used to find bridges in the network connecting different community nodes.
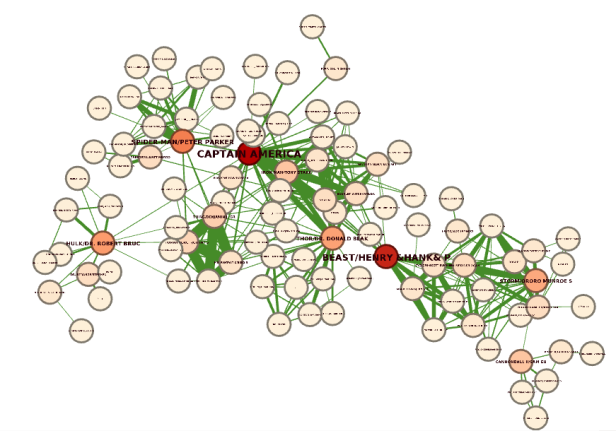
This example visualized a Marvel network, where relationships represent which characters appeared together in a comic. A prime example of Betweenness centrality is the character Beast, which connects the right-hand-side community with the other part of the network. If he was removed from the network, there would be no connection between the two communities. We can say that character Beast acts as a bridge between the two communities.
Closeness centrality is a way to identify nodes close to all the other nodes in the network and can therefore spread the information to the network efficiently. The idea is that the information only spreads through the shortest paths between pairs of nodes.
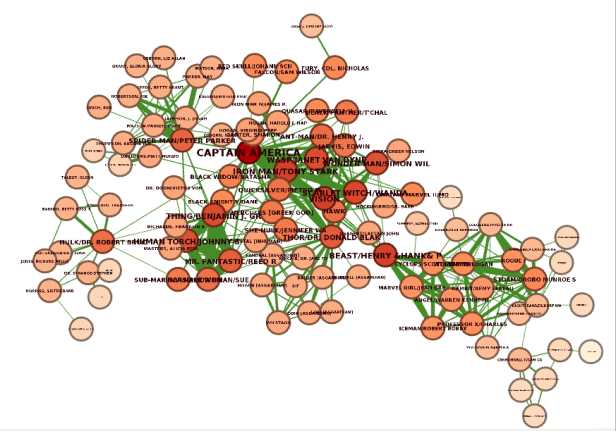
We can observe that nodes in the center of the network have the highest Closeness centrality score as they are able to reach all the other nodes the fastest.
We calculate the Closeness and Betweenness centrality score with the following code:
Feature exploration
Before we move on to the K-means clustering part, we will quickly evaluate the distributions of our features. We can fetch multiple mutated properties from the projected graph using the gds.graph.streamNodeProperties method.
The features_df dataframe has the following structure:
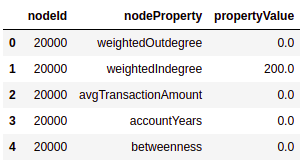
We can use the features_df dataframe to visualize the distributions of our features.
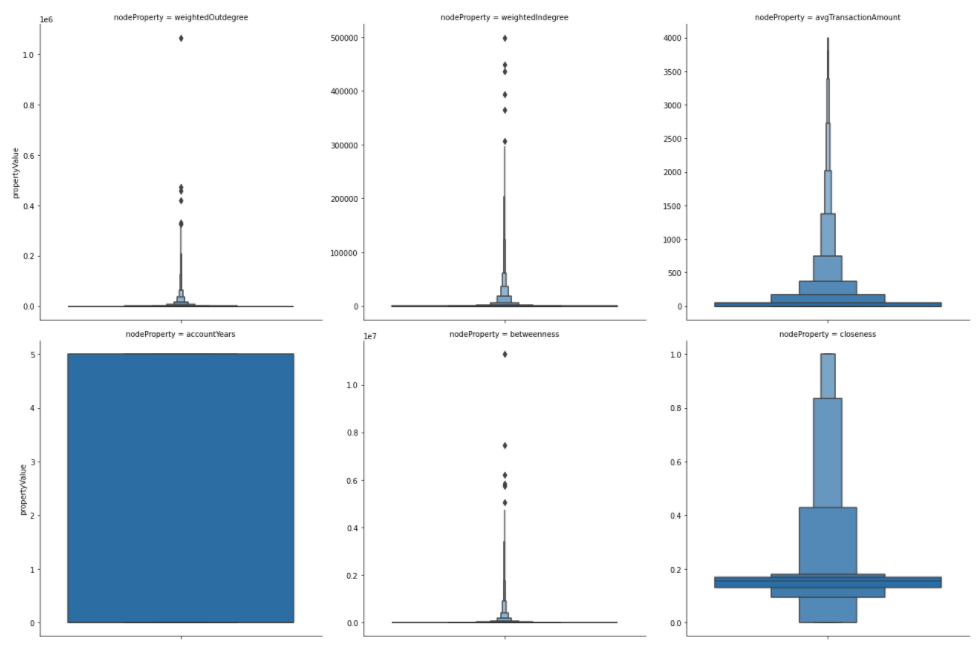
Interestingly, the account age is equally distributed through the years. Most users have a small average transaction amount of only a few hundred. However, some outliers have an average transaction amount of more than 3000. We have a few outliers in the weighted out-degree that have sent values of over half a million. The dataset doesn’t contain the currency, so I can’t say if we are dealing with USD or not.
The gds.graph.streamNodeProperties has a special keyword separate_property_columns attribute that pivots the dataframe automatically for us. Let’s try it out.
The pivot_features_df dataframe has the following structure:
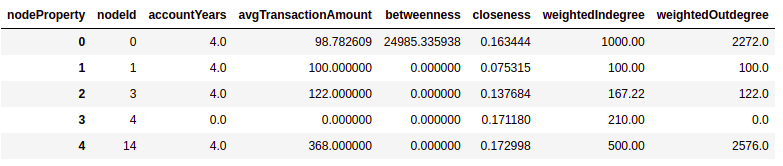
If you are not that visually oriented and want to get a table of distribution statistics, you can use the describe method of the dataframe.
Results
The pivot dataframe structure is also handy when we want to visualize the correlation matrix.
Results
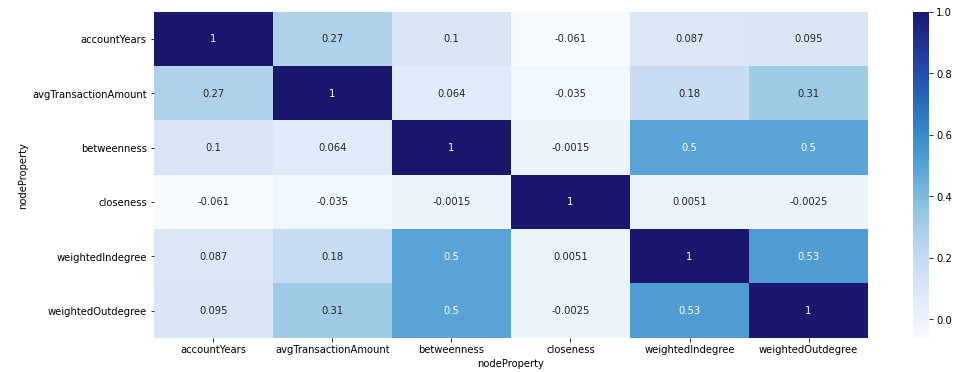
We can observe that the Betweenness centrality correlates with both the weighted in and out-degrees. Other than that, it seems that our features are not that correlated.
K-means clustering
K-means clustering is a widely used technique to group or cluster data points. However, since there are no training labels to learn from, the K-means algorithm is regarded as an unsupervised machine learning algorithm. The algorithm starts with the first group of randomly selected centroids used as baseline points for every cluster. The number of clusters is a fixed number defined with the parameter k. The algorithm then assigns each data point to the nearest centroid and iteratively optimizes the position of centroids.
There are plenty of great resources on the web about the K-means algorithm, so I won’t go into detail about how it works.
But there’s one crucial component to understand how it differs from other community detection algorithms like the Louvain or Label Propagation algorithms. Instead of using a graph of nodes and relationships as an input, we need to input vectors (array of numbers) of features that describe each data point.
Before running the K-means algorithm, we need to standardize our features, so that some features with high values will not skew the results. Therefore, we will use the standard score scaler, which is available in the Graph Data Science library.
We have selected our six features to be scaled and mutated under the features node property in the projected graph. The features node property type is a vector or an array of numbers.
The only thing left to do is execute the K-means algorithm. We need to define how many clusters we want to identify by specifying the parameter k. For the purpose of blog presentability, I will use a smaller value of 6. However, you should probably use a larger number when you don’t need to sacrifice accuracy for blog presentability like me.
Inspect cluster results
We will begin the cluster analysis by evaluating the size of clusters. First, we need to merge the kmeans_df dataframe with the pivot_features_df. Next, we use a simple group by aggregation to calculate the size of clusters.
Results
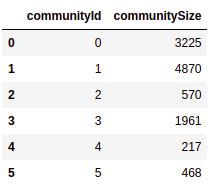
The cluster sizes vary from 217 members all the way to 4870 members. While we could calculate statistics of features for every community, it is tough to compress the results and make them presentable in a blog. Therefore, we will first evaluate the weighted out-degree (total amount sent to other users) per cluster.
Results
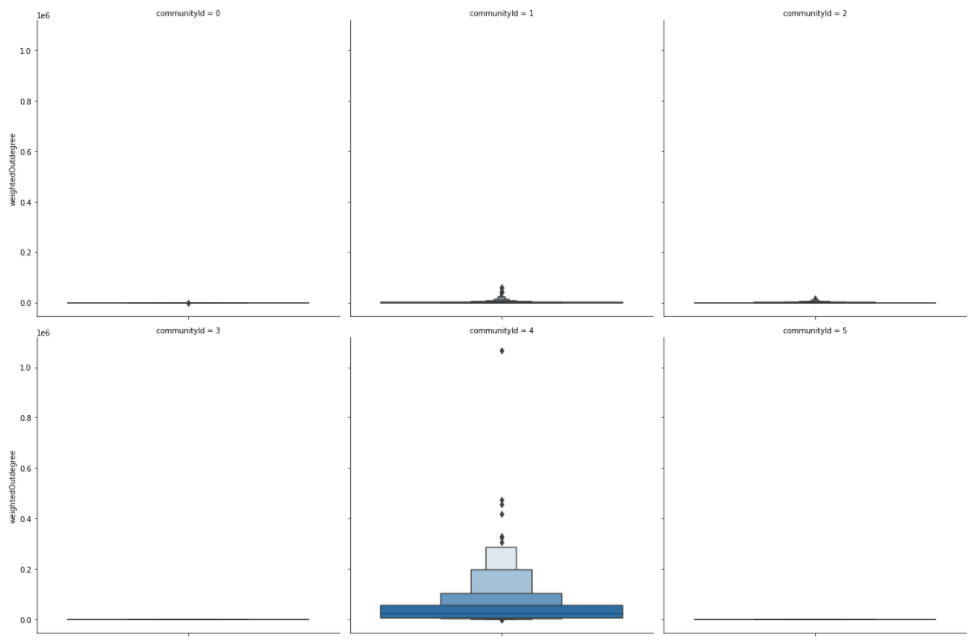
Users in communities 3 and 5 have no outgoing transactions, as their total amount sent to other users is zero. Communities 1 and 2 represent users that sent a small amount to other users. On the other hand, the community with id 4 represents power users who sent vast amounts to other users.
Let’s say we are interested in learning more about the power users community. We can use Pandas methods to filter and transform the data to an appropriate structure to be visualized with the Seaborn library.
Results
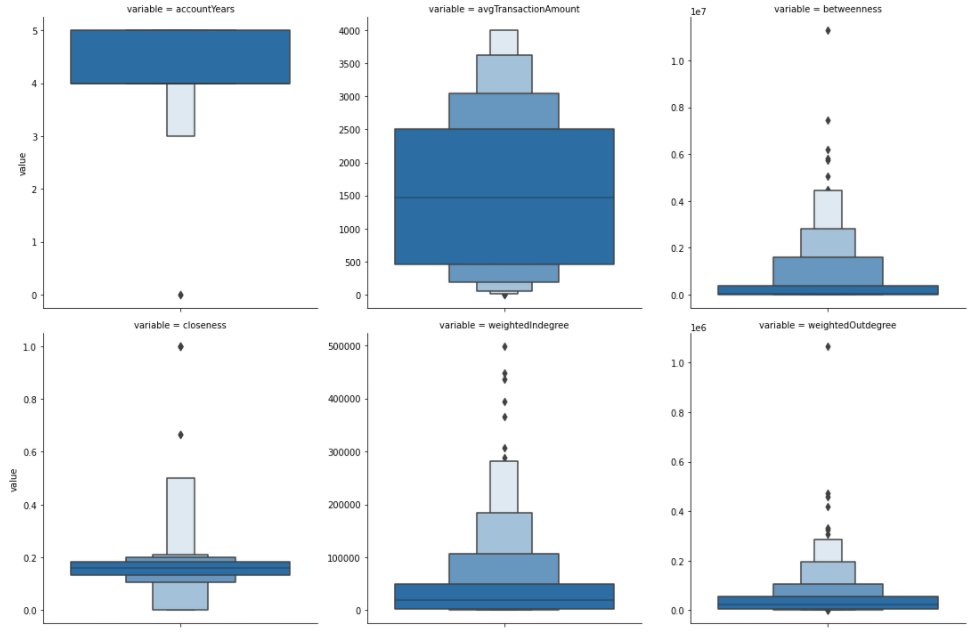
It seems that power users are more or less the oldest accounts.
Their average transaction amount usually ranges between 500 to 2500. So they sent a lot of currency to other users, but also received a lot of it. Not surprisingly, they have, on average, a high Betweenness score. Therefore, we can assume that they connect various communities of users and act as a bridge between them.
Lastly, we will plot the clusters on a scatter plot. In order to achieve this, we need to use a dimensionality reduction algorithm like t-SNE to reduce the feature dimensionality to 2.
Results
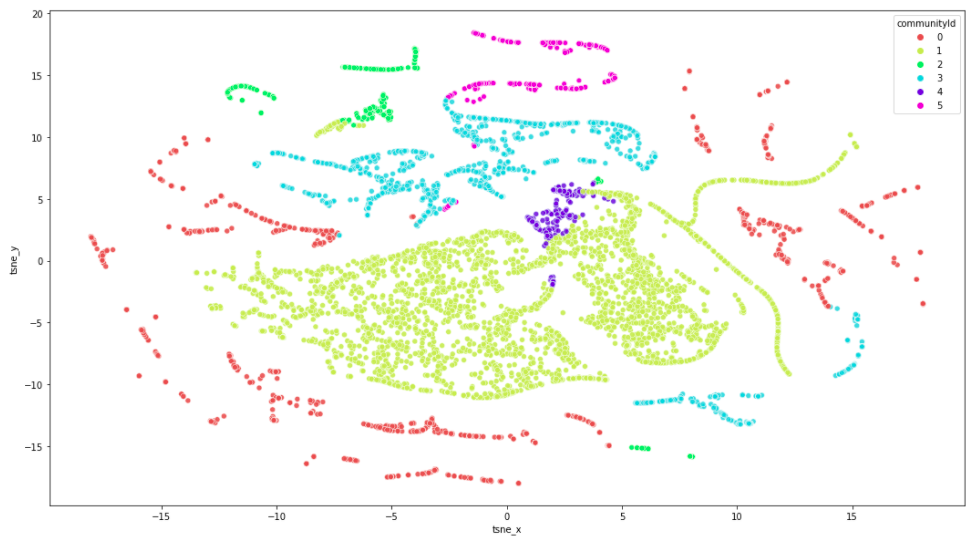
Maybe it is evident from this visualization that our cluster analysis accuracy would benefit from raising the number of clusters by increasing the K value. You may also be asking yourself why the split between clusters isn’t more distinct. For example, the red community is present on both the left and right sides of the visualization. I attribute this to the t-SNE dimensionality reduction algorithm. If we were to run the K-means algorithm on only two features, we should get a nice distinct split between clusters.
Conclusion
K-means algorithm was added to the Neo4j Graph Data Science library just recently and is a wonderful addition that can be used in your data science workflows. I also enjoy the new Neo4j Graph Data Science Python client that seamlessly integrates with other Python data science libraries.
It gives me an excuse to brush up on my visualization skills to make excellent presentations or explore outputs visually. I will definitely be using it in my projects. I encourage you to try it out and learn about its benefits.
As always, the code is available on GitHub.
User Segmentation Based on Node Roles in the Peer-to-Peer Payment Network was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Text2Cypher Across Languages: Evaluating Foundational Models Beyond English



