
Discover AuraDB Free: Week 13 – Exploring a Kaggle HR Attrition Dataset

Head of Product Innovation & Developer Strategy, Neo4j
7 min read

Neo4j has been used in several HR applications and use-cases, such as for sales hierarchies, skills-management, recruiting applications, learning paths, internal role recommendations, and more.

So when I found IBM Attrition Dataset as one of the trending datasets on Kaggle, I wanted to give it a try.
The dataset is meant for attrition prediction, but we don’t take it that far — we just import and model it into AuraDB free and explore some of the visual aspects of the data.
AuraDB Free GA Launch
Just recently Neo4j AuraDB Free was launched as GA, so you can use Neo4j in the cloud without a credit card, even for long-running small projects or learning.
My colleague David Allen wrote a nice blog post that gives you some hands-on tips on getting started.
Dataset
The dataset is a CSV with 32 columns with all kinds of employee data:
- attrition
- department, role, job level, mode of work
- salary, salary increase percentage, stock options
- overtime, job satisfaction, job involvement
- education degree
- hire date, years at company, years since last promotion, years with mgr, source of recruiting
- leaves, absenteeism, work accidents
- workplace, distance, travel frequency
- gender, marital status
- number of companies worked for, working years
Importing Attrition Data
We put that CSV into a GitHub Gist and use a shortlink for accessing the raw file https://git.io/JX0dU.
First few records:
load csv with headers from "https://git.io/JX0dU" as row
return row limit 5;
{
"null": null,
"DistanceFromHome": "2",
"OverTime": "Yes",
"BusinessTravel": "Travel_Rarely",
"Date_of_termination": null,
"Status_of_leaving": "Salary",
"Absenteeism": "2",
"Gender": "Male",
"Attrition": "Yes",
"Source_of_Hire": "Job Event",
"YearsAtCompany": "0",
"Mode_of_work": "OFFICE",
"Leaves": "4",
"Department": "Research & Development",
"Job_mode": "Contract",
"TotalWorkingYears": "7",
"PercentSalaryHike": "15",
"MonthlyIncome": "2090",
"Age": "37",
"JobInvolvement": "2",
"JobSatisfaction": "3",
"JobLevel": "1",
"Work_accident": "No",
"Date_of_Hire": "21-01-2021",
"PerformanceRating": "3",
"YearsSinceLastPromotion": "0",
"JobRole": "Laboratory Technician",
"Higher_Education": "Graduation",
"TrainingTimesLastYear": "3",
"MaritalStatus": "Single",
"YearsWithCurrManager": "0",
"NumCompaniesWorked": "6",
"StockOptionLevel": "0"
}
Unfortunately, there is no id column to identify employees, so we need to use the linenumber() function, and as it starts at 2 (probably 1 is the header row), subtract 1.
To import our data, this time we just import all attributes of a row into a single Employee node and will later extract other nodes as we progress through the data.
As all the CSV values are returned as strings, we’d have to convert them to numbers or booleans as needed, but we can also do that later. For instance:
- toFloat(“3.14”)
- toInteger(“42”)
- boolean: value = “Yes”
- date(‘2020–01–01’)
This import statement using MERGE is idempotent, so we can run it time and again, without new nodes being created if they already exist with that id.
It creates 1470 nodes which is the number of rows in our dataset.
LOAD CSV WITH HEADERS FROM "https://git.io/JX0dU" AS row
WITH linenumber()-1 AS id, row
MERGE (e:Employee {id:id})
ON CREATE SET e += row,
e.DistanceFromHome = toInteger(row.DistanceFromHome);
We want to set the Attrition fact as a label on the node, we picked :Left because it’s harder to misspell 🙂
MATCH (e:Employee)
WHERE e.Attrition = 'Yes'
SET e:Left;
Extract Department
The first node we want to extract is the Department. We will merge department on name to prevent duplicates and create the relationship to employee.
// see some departments
match (e:Employee)
return e.Department limit 5;
// create unique departments and connect them
match (e:Employee)
merge (d:Department {name:e.Department})
merge (e)-[r:WORKS_IN]->(d);
MATCH p=()-[r:WORKS_IN]->() RETURN p LIMIT 25;
Now we can inspect the departments and their employees, e.g. by opening Neo4j Bloom on this database and running the Employee Department search phrase and styling the employee by Attrition.
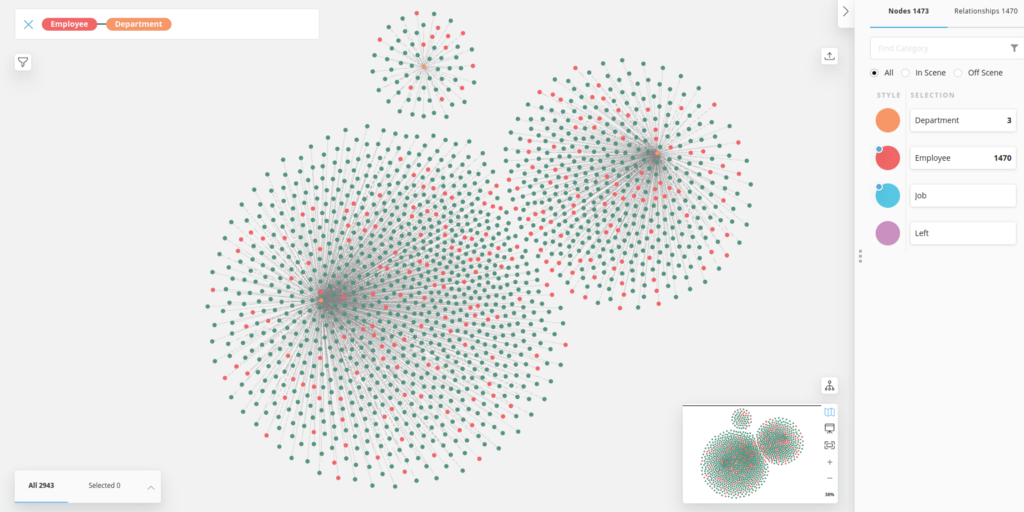
We can also look at the percentage leavers and see that R&D — despite being the largest — has the lowest percentage of leavers.
match (d:Department)<-[:WORKS_IN]-(e)
return d.name, count(*) as total, sum(case when e:Left then 1 else 0 end) as left
order by total desc;
// compute leaver percentage
match (d:Department)<-[:WORKS_IN]-(e)
with d.name as dep, count(*) as total, sum(case when e:Left then 1 else 0 end) as left
return dep, total, left, toFloat(left)/total as percent
order by percent desc;
╒════════════════════════╤═══════╤══════╤═══════════════════╕
│"dep" │"total"│"left"│"percent" │
╞════════════════════════╪═══════╪══════╪═══════════════════╡
│"Sales" │446 │92 │0.2062780269058296 │
├────────────────────────┼───────┼──────┼───────────────────┤
│"Human Resources" │63 │12 │0.19047619047619047│
├────────────────────────┼───────┼──────┼───────────────────┤
│"Research & Development"│961 │133 │0.1383975026014568 │
└────────────────────────┴───────┴──────┴───────────────────┘
Extracting Role and Job-Related Data
Next we can extract the role and some of the related job data.
We could just store it on the relationship to the department but wanted to connect other information to the core concept of employment, so we turn it into a node.
This time we use CREATE to get one instance of a role per employee.
MATCH (e:Employee)
CREATE (j:Job {name:e.JobRole})
SET j.JobSatisfaction=toInteger(e.JobSatisfaction),
j.JobInvolvement = toInteger(e.JobInvolvement),
j.JobLevel = toInteger(e.JobLevel),
j.MonthlyIncome = toInteger(e.MonthlyIncome)
MERGE (e)-[r:WORKS_AS]->(j);
We can now color the role by job satisfaction (red-yellow-green) in Bloom and size it by salary.
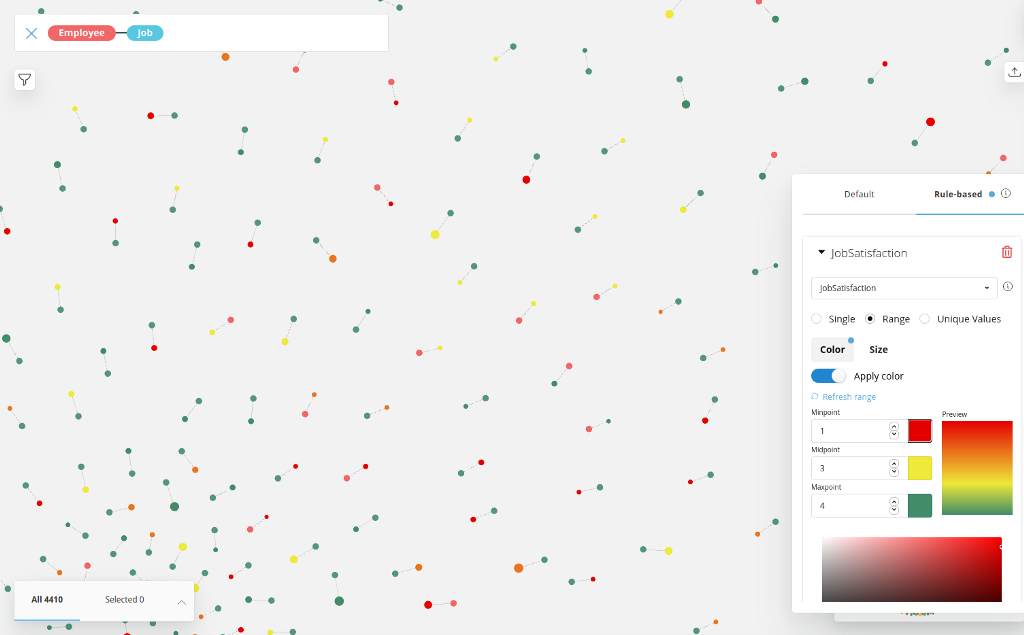
This allows us to see pairs of red-red (unsatisified-left), green-green (satisfied-retained) and the critical red-green (unsatisfied-not yet left) nodes between employees and their roles. And probably people with higher salaries are more likely to stick around and endure dissatisfaction.
We forgot to create the relationship between role and department, but fortunately we can just spell out our graph pattern and close the triangle that you can also see in the data model below.
MATCH (d:Department)<-[:WORKS_IN]-(e:Employee)-[:WORKS_AS]->(j:Job)
MERGE (j)-[:ROLE_IN]->(d);
We could use the Job Level in conjunction with the roles to create an hierarchy of roles, but as we don’t know who reported to whom, we can’t tell much about the real org-level.
Data Model
So far we ended up with this data model, but there are more and different approaches to extract relevant information into separate nodes.
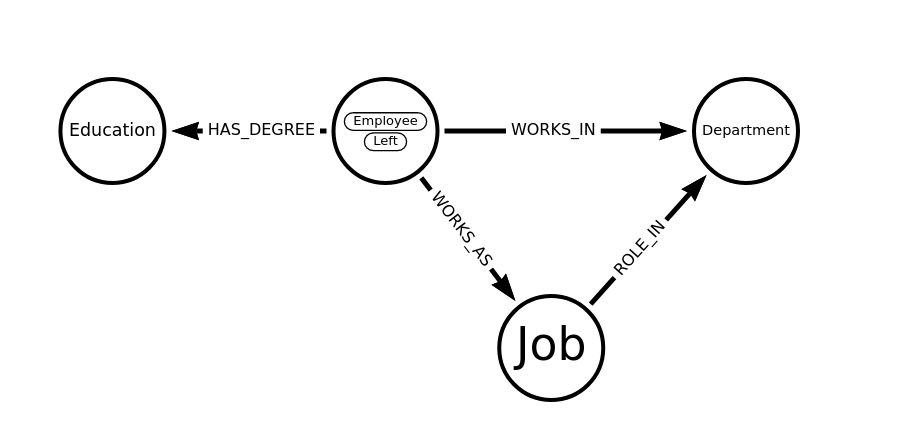
Some of the attributes, like role, salary etc. we could also have modeled as relationship properties the WORKS_IN relationship of Department, but we wanted to show and highlight the roles as first class entities in our model.
Extracting Education
Turning Education into a node was straightforward but not as insightful.
match (e:Employee)
merge (edu:Education {name:e.Higher_Education})
merge (e)-[r:HAS_DEGREE]->(edu);
MATCH (edu:Education)
RETURN edu.name, size( (edu)<--() ) as count
ORDER BY c DESC;
We find 4 types of education, pretty evenly distributed.
╒═════════════════╤═══╕
│"edu.name" │"c"│
╞═════════════════╪═══╡
│"Post-Graduation"│387│
├─────────────────┼───┤
│"Graduation" │367│
├─────────────────┼───┤
│"PHD" │358│
├─────────────────┼───┤
│"12th" │358│
└─────────────────┴───┘
We now can also start looking for patterns, like people who have similar education like leavers and which ones are most frequent.
MATCH (e:Left)-[:HAS_DEGREE]->(edu)<-[:HAS_DEGREE]-(e2)
return edu.name, e2:Left as hasLeft, count(distinct e2) as c order by c desc;
But again, those numbers are pretty close, so it’s not that predictive.
╒═════════════════╤═════════╤═══╕
│"edu.name" │"hasLeft"│"c"│
╞═════════════════╪═════════╪═══╡
│"Post-Graduation"│false │323│
├─────────────────┼─────────┼───┤
│"Graduation" │false │309│
├─────────────────┼─────────┼───┤
│"PHD" │false │301│
├─────────────────┼─────────┼───┤
│"12th" │false │300│
├─────────────────┼─────────┼───┤
│"Post-Graduation"│true │64 │
├─────────────────┼─────────┼───┤
│"Graduation" │true │58 │
├─────────────────┼─────────┼───┤
│"12th" │true │58 │
├─────────────────┼─────────┼───┤
│"PHD" │true │57 │
└─────────────────┴─────────┴───┘
Temporal Data
We wanted to see how recent the data is, so we returned the min- and max hire date; unfortunately the date strings are not ISO formatted, so the results were not useful and we had to convert them into date values. The temporal APIs are pretty broad — my colleague Jennifer Reif wrote a 5-part deep-dive series on it:
Cypher Sleuthing: Dealing with Dates, Part 1
Because the dates are not ISO formatted, we can’t use the built-in functions date(“2021-11-08”) but need to make use of the APOC utility library, and its apoc.temporal.toZonedTemporal, which can use a supplied format.
call apoc.help("temporal");
match (e:Employee)
set e.Date_of_Hire = date(apoc.temporal.toZonedTemporal(e.Date_of_Hire,"dd-MM-yyyy"));
match (e:Employee) return min(e.Date_of_Hire), max(e.Date_of_Hire);
Now we see that the dataset is current and that the earliest employee is from 1969 🙂
╒═════════════════════╤═════════════════════╕
│"min(e.Date_of_Hire)"│"max(e.Date_of_Hire)"│
╞═════════════════════╪═════════════════════╡
│"1969-06-19" │"2021-06-25" │
└─────────────────────┴─────────────────────┘
As the dataset also contains the YearsAtCompany information, we can compute the date until which they are employed and set it as a new attribute using the built-in duration arithmetics.
match (e:Employee)
set e.Employed_Until = e.Date_of_Hire + duration({years:toInteger(e.YearsAtCompany)});
match (e:Employee) return min(e.Employed_Until), max(e.Employed_Until);
The first employee left in 1994 and the dataset seems to be from June 2021.
╒═══════════════════════╤═══════════════════════╕
│"min(e.Employed_Until)"│"max(e.Employed_Until)"│
╞═══════════════════════╪═══════════════════════╡
│"1994-06-19" │"2021-06-30" │
└───────────────────────┴───────────────────────┘
Similarity Network and Predictions
You would need the graph data science library for computing similarity networks or node classification based on attributes and then use them to identify employees similar to the leavers who have not left yet and try to help them with their careers.
In Neo4j Sandbox, Desktop, or soon AuraDS you can project the isolated employee data into a in-memory graph with rescaled, normalized attributes that form a vector of information about each employee.
Those vectors can either be used to compute a similarity network with k-nearest-neighbors or node-similarity. That network can then be analyzed for tightly knit clusters that identify similar people and see the risk of churning per cluster. For high risk clusters, the people who have not yet left can be identified and worked with.
Alternatively those vectors, our extracted nodes, and the similarity network can be used to compute node embeddings that are then utilized in training a node-classification algorithm to predict attrition.
Resources
- Neo4j AuraDB Free
- Kaggle Dataset
- GitHub Gist
- ShortLink to Raw CSV
- 5-part series on temporal data in Neo4j
Discover AuraDB Free: Week 13 — Exploring a Kaggle HR Attrition Dataset was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles





How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs
