Subqueries in Cypher
Recap our example graph
All of our code examples will continue with one of the graph examples we have been using before, but include some more data for the queries on this page. Below is an image of the new graph, a network of people, the companies they work for, and the technologies they like.
We have added one more Person node (blue) who WORKS_FOR a Company node (red) and LIKES a Technology (green) node: Ryan works for Company Z and likes Python.
You can find this data on the right hand side of the graph.
To recap, each person could also have multiple IS_FRIENDS_WITH relationships to other people.

You can create this dataset using the following Cypher® query:
CREATE (diana:Person {name: "Diana"})-[:LIKES]->(query:Technology {type: "Query Languages"})
CREATE (melissa:Person {name: "Melissa", twitter: "@melissa"})-[:LIKES]->(query)
CREATE (dan:Person {name: "Dan", twitter: "@dan", yearsExperience: 6})-[:LIKES]->(etl:Technology {type: "Data ETL"})<-[:LIKES]-(melissa)
CREATE (xyz:Company {name: "XYZ"})<-[:WORKS_FOR]-(sally:Person {name: "Sally", yearsExperience: 4})-[:LIKES]->(integrations:Technology {type: "Integrations"})<-[:LIKES]-(dan)
CREATE (sally)<-[:IS_FRIENDS_WITH]-(john:Person {name: "John", yearsExperience: 5, birthdate: "1985-04-04"})-[:LIKES]->(java:Technology {type: "Java"})
CREATE (john)<-[:IS_FRIENDS_WITH]-(jennifer:Person {name: "Jennifer", twitter: "@jennifer", yearsExperience: 5, birthdate: "1988-01-01"})-[:LIKES]->(java)
CREATE (john)-[:WORKS_FOR]->(xyz)
CREATE (sally)<-[:IS_FRIENDS_WITH]-(jennifer)-[:IS_FRIENDS_WITH]->(melissa)
CREATE (joe:Person {name: "Joe", birthdate: "1988-08-08"})-[:LIKES]->(query)
CREATE (mark:Person {name: "Mark", twitter: "@mark"})
CREATE (ann:Person {name: "Ann"})
CREATE (x:Company {name: "Company X"})<-[:WORKS_FOR]-(diana)<-[:IS_FRIENDS_WITH]-(joe)-[:IS_FRIENDS_WITH]->(mark)-[:LIKES]->(graphs:Technology {type: "Graphs"})<-[:LIKES]-(jennifer)-[:WORKS_FOR]->(:Company {name: "Neo4j"})
CREATE (ann)<-[:IS_FRIENDS_WITH]-(jennifer)-[:IS_FRIENDS_WITH]->(mark)
CREATE (john)-[:LIKES]->(:Technology {type: "Application Development"})<-[:LIKES]-(ann)-[:IS_FRIENDS_WITH]->(dan)-[:WORKS_FOR]->(abc:Company {name: "ABC"})
CREATE (ann)-[:WORKS_FOR]->(abc)
CREATE (a:Company {name: "Company A"})<-[:WORKS_FOR]-(melissa)-[:LIKES]->(graphs)<-[:LIKES]-(diana)
CREATE (:Technology {type: "Python"})<-[:LIKES]-(:Person {name: "Ryan"})-[:WORKS_FOR]->(:Company {name: "Company Z"})An introduction to subqueries
Subqueries were introduced in Neo4j 4.0.
Go to the Cypher manual → Subqueries for detailed information on how to use them.
The following types of subqueries are possible in Neo4j:
The EXISTS, COUNT, and CALL {…} subqueries are covered in this section.
To learn more about using CALL {…} IN TRANSACTIONS, see the code examples in the following tutorials on how to import CSV data into a Neo4j database:
The COLLECT subqueries were introduced in Neo4j 5.6.
It is a new kind of subquery for collecting results of a subquery into a list so that further operations like DISTINCT, ORDER BY, LIMIT, and SKIP can be performed.
COLLECT subqueries differ from COUNT and EXISTS subqueries in that the final RETURN clause is mandatory.
The RETURN clause in a COLLECT subquery must return exactly one column.
Cypher subqueries
A subquery is a set of Cypher statements that execute within their own scope. A subquery is typically called from an outer enclosing query.
Here are some important things to know about a subquery:
-
A subquery returns values referred to by the variables in the
RETURNclause. -
A subquery cannot return variables with the same name used in the enclosing query.
-
You must explicitly pass in variables from the enclosing query to a subquery.
Subqueries are demarcated by braces ({ }).
In the Filtering on patterns section of the Getting the correct results chapter, you learnt how to filter based on patterns. For example, you can write the following query to find the friends of someone who works for Neo4j:
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person)
WHERE exists((p)-[:WORKS_FOR]->(:Company {name: 'Neo4j'}))
RETURN p, r, friendIf you run this query in Neo4j Browser, the following graph is returned:
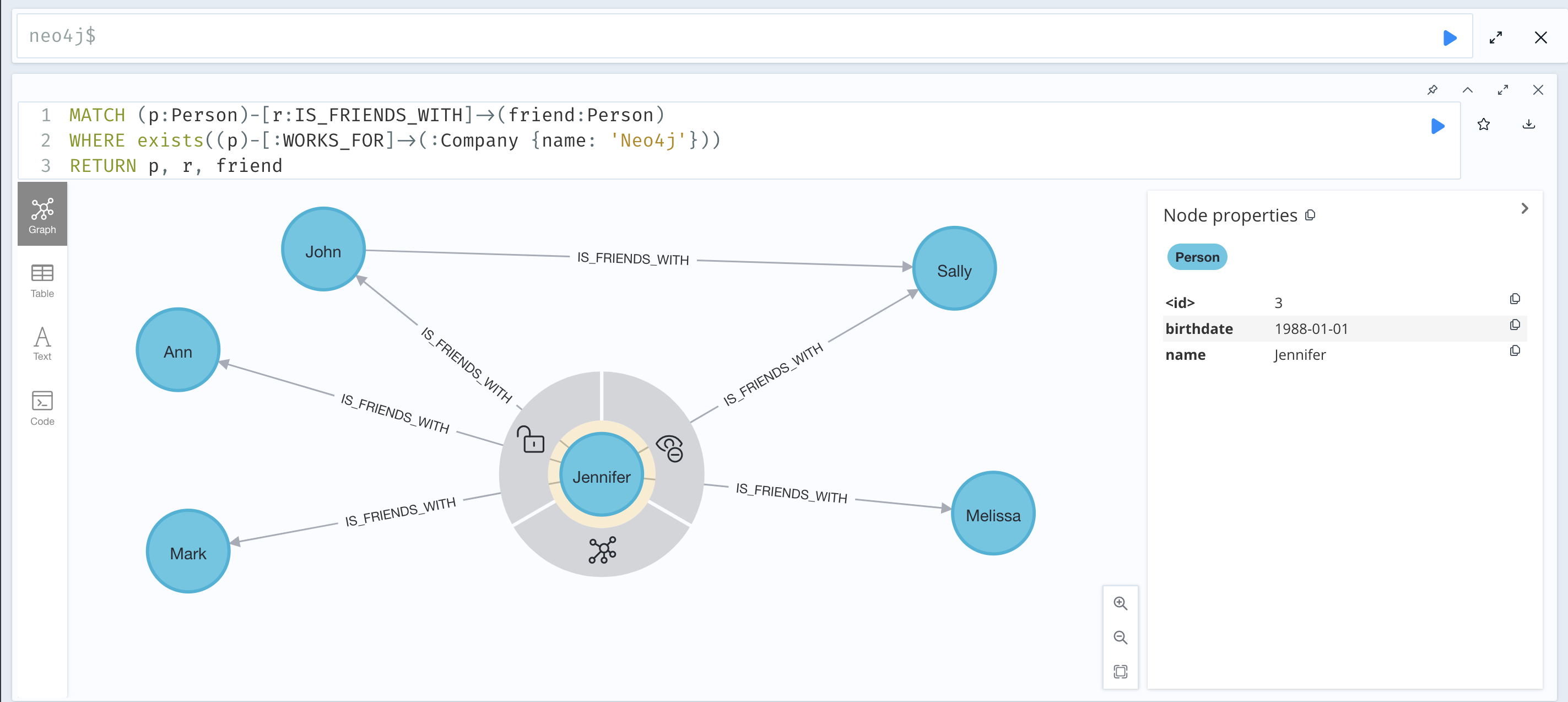
Cypher subqueries enable more powerful pattern filtering.
Instead of using the exists function in the WHERE clause, you can use the EXISTS subquery.
You can reproduce the previous example with the following query:
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person)
WHERE EXISTS {
MATCH (p)-[:WORKS_FOR]->(:Company {name: 'Neo4j'})
}
RETURN p, r, friendYou will get the same result, which is nice, but so far all you’ve achieved is the same thing with more code!
Next, let’s write a subquery that filters more powerfully than what can be achieved with the WHERE clause or the exists function alone.
Assume that:
-
You want to find people who work for a company whose name starts with 'Company' and who like at least one technology that’s liked by three or more people.
-
You aren’t interested in knowing what those technologies are.
You might try to answer this question with the following query:
MATCH (person:Person)-[:WORKS_FOR]->(company)
WHERE company.name STARTS WITH "Company"
AND (person)-[:LIKES]->(t:Technology)
AND COUNT { (t)<-[:LIKES]-() } >= 3
RETURN person.name as person, company.name AS company;If you run this query, you’ll see the following output:
Variable `t` not defined (line 4, column 25 (offset: 112))
"AND (person)-[:LIKES]->(t:Technology)"
^You can find people that like a technology, but you cannot check that at least three other people like that technology as well, because the variable t isn’t in the scope of the WHERE clause.
Let’s instead move the two AND statements into an EXISTS subquery block, resulting in the following query:
MATCH (person:Person)-[:WORKS_FOR]->(company)
WHERE company.name STARTS WITH "Company"
AND EXISTS {
MATCH (person)-[:LIKES]->(t:Technology)
WHERE COUNT { (t)<-[:LIKES]-() } >= 3
}
RETURN person.name as person, company.name AS company;Now you can successfully run the query, which returns the following results:
| person | company |
|---|---|
"Melissa" |
"CompanyA" |
"Diana" |
"CompanyX" |
If you recall the graph visualisation from the start of this guide, Ryan is the only other person who works for a company which name starts with 'Company'.
He’s been filtered out in this query because the only Technology that he likes is Python, and there aren’t three other people who like Python.
Result returning subqueries
So far you have learnt how to use subqueries to filter out results, but this doesn’t fully show their power. You can also use subqueries to return results as well.
Let’s say you want to write a query that finds people who like Java or have more than one friend.
Apart from that, you want to return the results ordered by date of birth in descending order.
This can be partially achieved using the UNION clause and the COUNT subquery:
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC
UNION
MATCH (p:Person)
WHERE COUNT { (p)-[:IS_FRIENDS_WITH]->() } > 1
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC;If you run that query, you see the following output:
| person | dob |
|---|---|
"Jennifer" |
1988-01-01 |
"John" |
1985-04-04 |
"Joe" |
1988-08-08 |
You’ve got the correct people.
But the UNION approach only lets us sort results per UNION clause, not for all rows.
You can try another approach, where you execute each of the subqueries separately and collect the people from each part using the collect() function.
There are some people who like Java and have more than one friend, so you need to use DISTINCT operator in the RETURN clause to remove the duplicates:
// Find people who like Java
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
WITH collect(p) AS peopleWhoLikeJava
// Find people with more than one friend
MATCH (p:Person)
WHERE COUNT { (p)-[:IS_FRIENDS_WITH]->() } > 1
WITH collect(p) AS popularPeople, peopleWhoLikeJava
WITH popularPeople + peopleWhoLikeJava AS people
// Unpack the collection of people and order by birthdate
UNWIND people AS p
RETURN DISTINCT p.name AS person, p.birthdate AS dob
ORDER BY dob DESCIf you run that query, you will get the following output:
| person | dob |
|---|---|
"Joe" |
1988-08-08 |
"Jennifer" |
1988-01-01 |
"John" |
1985-04-04 |
This approach works, but it’s more difficult to write, as you have to keep passing through parts of the query to its next part.
The CALL {…} clause gives you the best of both worlds:
-
You can use the UNION approach to run the individual queries and remove duplicates.
-
You can sort the results afterwards.
Our query using the CALL {…} clause looks like this:
CALL {
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p
UNION
MATCH (p:Person)
WHERE COUNT { (p)-[:IS_FRIENDS_WITH]->() } > 1
RETURN p
}
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC;If you run that query, you will get the following output:
| person | dob |
|---|---|
"Joe" |
1988-08-08 |
"Jennifer" |
1988-01-01 |
"John" |
1985-04-04 |
You could extend the query further to return the technologies that these people like, and the friends that they have. The following query shows how to do this:
CALL {
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p
UNION
MATCH (p:Person)
WHERE COUNT { (p)-[:IS_FRIENDS_WITH]->() } > 1
RETURN p
}
WITH p,
[(p)-[:LIKES]->(t) | t.type] AS technologies,
[(p)-[:IS_FRIENDS_WITH]->(f) | f.name] AS friends
RETURN p.name AS person, p.birthdate AS dob, technologies, friends
ORDER BY dob DESC;| person | dob | technologies | friends |
|---|---|---|---|
"Joe" |
1988-08-08 |
["Query Languages"] |
["Mark", "Diana"] |
"Jennifer" |
1988-01-01 |
["Graphs", "Java"] |
["Sally", "Mark", "John", "Ann", "Melissa"] |
"John" |
1985-04-04 |
["Java", "Application Development"] |
["Sally"] |
You can also apply aggregation functions to the results of the subquery. The following query returns the youngest and oldest of the people who like Java or have more than one friend.
CALL {
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p
UNION
MATCH (p:Person)
WHERE COUNT { (p)-[:IS_FRIENDS_WITH]->() } > 1
RETURN p
}
RETURN min(p.birthdate) AS oldest, max(p.birthdate) AS youngest| oldest | youngest |
|---|---|
1985-04-04 |
1988-08-08 |