Merging Data in the Graph
About this module
You have learned how to create nodes and relationships in the graph. When you create a node you want to ensure that there is only one instance of that node in the graph. You also want to ensure that you do not create unnecessary or duplicate relationships in the graph. Next, you will learn how to merge data in the graph.
At the end of this module, you will write Cypher statements to:
-
Merge data in a graph by:
-
Creating nodes.
-
Creating relationships.
-
| Because the code examples in this lesson modify the database, it is recommended that you do not execute them against your database as you will be doing so in the hands-on exercises. |
Creating data in the graph
Thus far, you have learned how to create nodes, labels, properties, and relationships in the graph.
You can use MERGE to either create new nodes and relationships or to make changes to existing nodes and relationships.
For example, how the graph engine behaves when a duplicate element is created depends on the type of element. You have not yet learned about defining constraints in the graph. Constraints can be used to eliminate duplication of nodes and you will learn about them in the course, Using Indexes and Query Best Practices in Neo4j 4.x.
Here are some facts about creating nodes and relationships in the graph when no constraints have been defined.
If you use |
The result is: |
|---|---|
Node |
If a node with the same property values exists, a duplicate node is created. |
Label |
If the label already exists for the node, the node is not updated. |
Property |
If the node or relationship property already exists, it is updated with the new value.
Note: If you specify a set of properties to be created using |
Relationship |
If the relationship exists, a duplicate relationship is created. |
Using MERGE
The MERGE clause is used to find nodes or patterns in the graph.
If the node or pattern is not found, by default, it is created.
You use the simple MERGE clause to:
-
Create a unique node based on label and key information for a property or set of properties.
-
Update a node based on label and key information for a property or set of properties.
-
Create a unique relationship between two nodes.
-
Create a unique node and relationship in the context of another node.
Syntax: Using MERGE to create nodes
Here is the simplified syntax for the MERGE clause for creating a node:
MERGE (variable:Label{nodeProperties})
RETURN variableIf there is an existing node with Label and nodeProperties found in the graph, no node is created. If, however the node is not found in the graph, then the node is created.
When you specify nodeProperties for MERGE, only use properties that satisfy some sort of uniqueness constraint.
You will learn about uniqueness constraints in the course, Using Indexes and Query Best Practices in Neo4j 4.x.
It is also extremely important to ensure that if you are using MERGE on a large dataset, the property that you use to uniquely identify the node has a uniqueness constraint defined which is an index.
If there is no index, the MERGE needs to scan all nodes to find the matching node which is very expensive for large datasets.
Here is what we currently have in the graph for the Person, Michael Caine. This node has values for name and born. Notice also that the label for the node is Person.
MATCH (p:Person)
WHERE p.name = 'Michael Caine'
RETURN p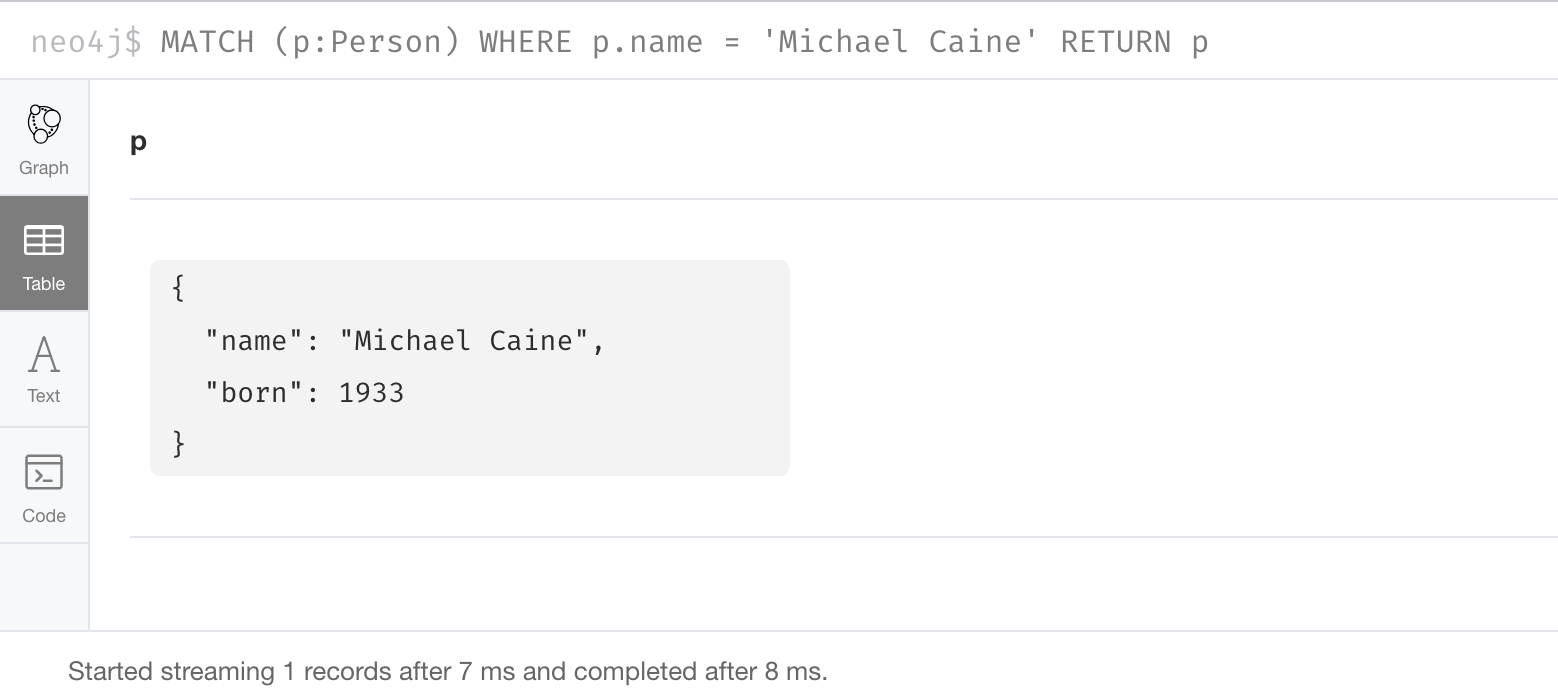
Example: Using MERGE
In this example, we use MERGE to find a node with the Actor label with the key property name of Michael Caine, and we set the born property to 1933. Our data model has never used the label, Actor so this is a new entity type in our graph.
MERGE (a:Actor {name: 'Michael Caine'})
SET a.born = 1933
RETURN aHere is the result of running this Cypher example. We do not find a node with the label Actor so the graph engine creates one.
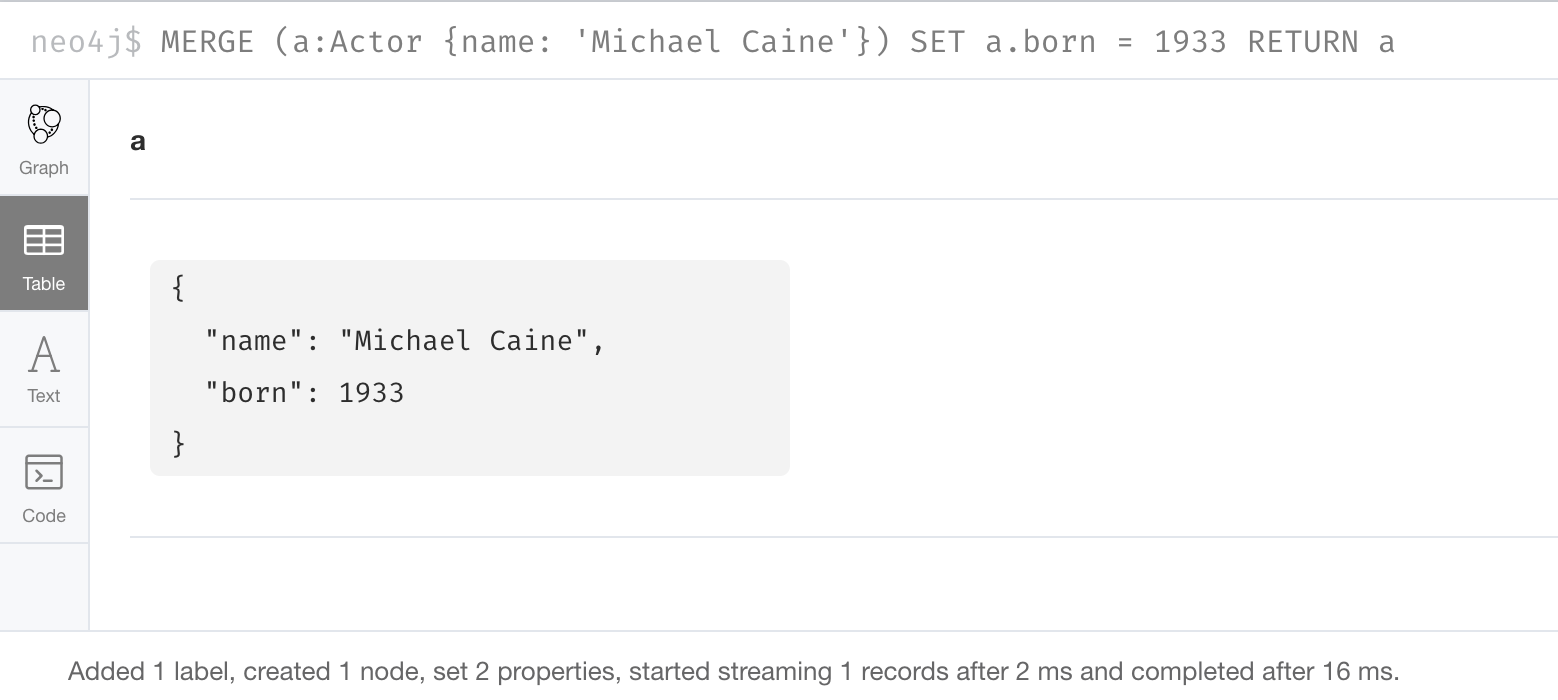
A best practice when using MERGE is to only specify properties that have unique values and unique labels.
|
Repeating the same MERGE
If we were to repeat this MERGE clause, no additional Actor nodes would be created in the graph.
At this point, however, we have two Michael Caine nodes in the graph, one of type Person, and one of type Actor:
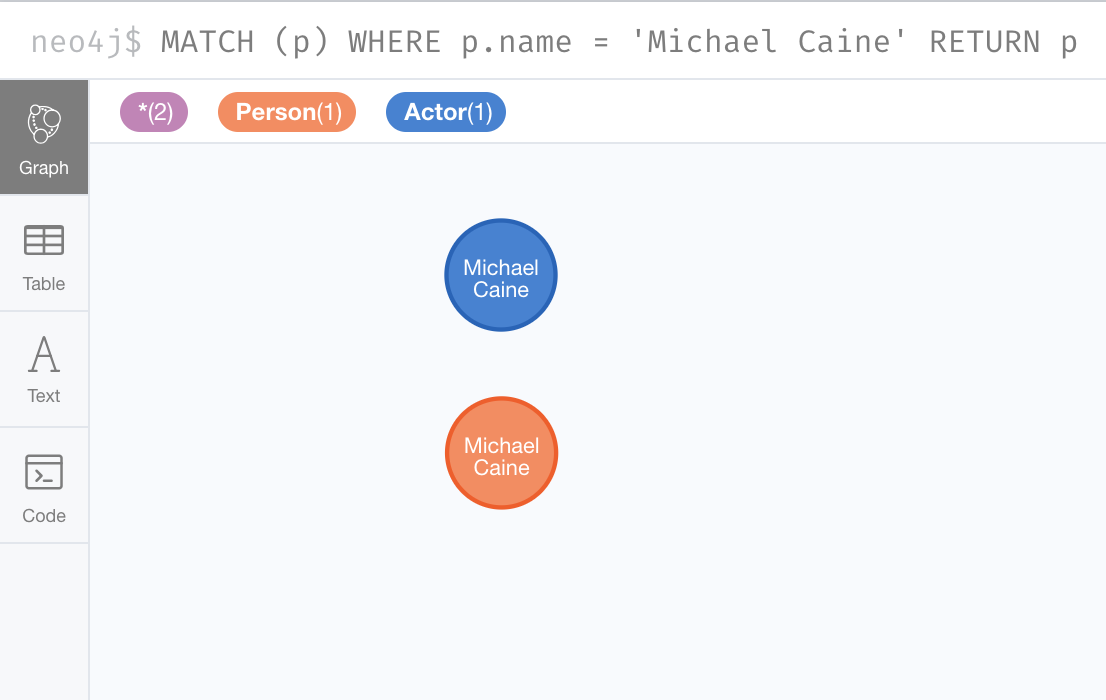
Be mindful that node labels and the properties for a node are significant when merging nodes.
If we were to run MERGE code again:
MERGE (a:Actor {name: 'Michael Caine'})
SET a.born = 1933
WITH a
MATCH (p)
WHERE p.name = 'Michael Caine'
RETURN p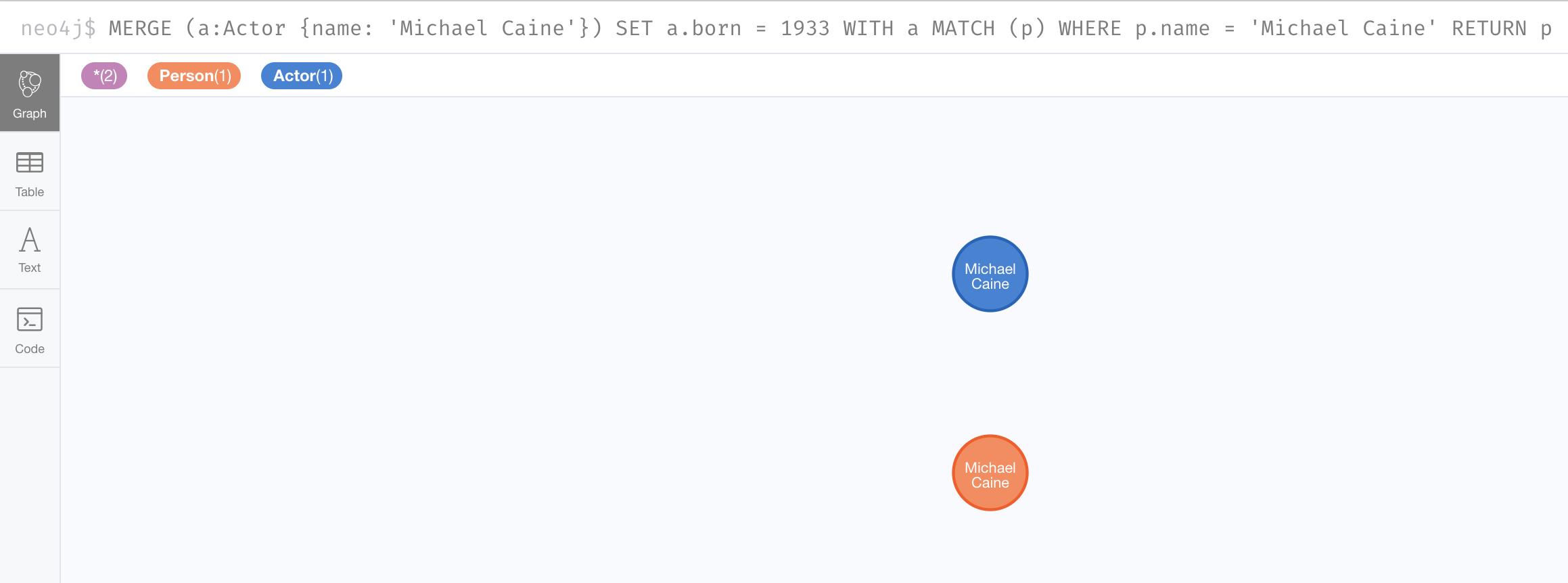
We would find that the Michael Caine node with the label Actor is not created.
The MERGE found this node in the graph and did not create a new one.
Notice that we have a WITH a in this code. The WITH clause can be used to separate the writing part of a query from a reading part of a query.
Here we see that the variable a is not used later in the query, but is simply used to separate writing and reading parts of the code.
Syntax: Using MERGE to create relationships
Here is the syntax for the MERGE clause for creating relationships:
MERGE (variable1:Label1 {nodeProperties1})-[:REL_TYPE]->
(variable2:Label2 {nodeProperties2})
RETURN variableIf there is an existing node with Label1 and nodeProperties1 with the :REL_TYPE relationship to an existing node with Label2 and nodeProperties2 in the graph, no relationship is created. If the relationship does not exist, the relationship is created.
Example: Finding existing relationships
Here is an example. We currently have the Person node with the :ACTED_IN relationship, but we do not have this relationship with the Actor node.
MATCH (p {name: 'Michael Caine'})-[*0..1]-(m)
RETURN p, mHere is the result:
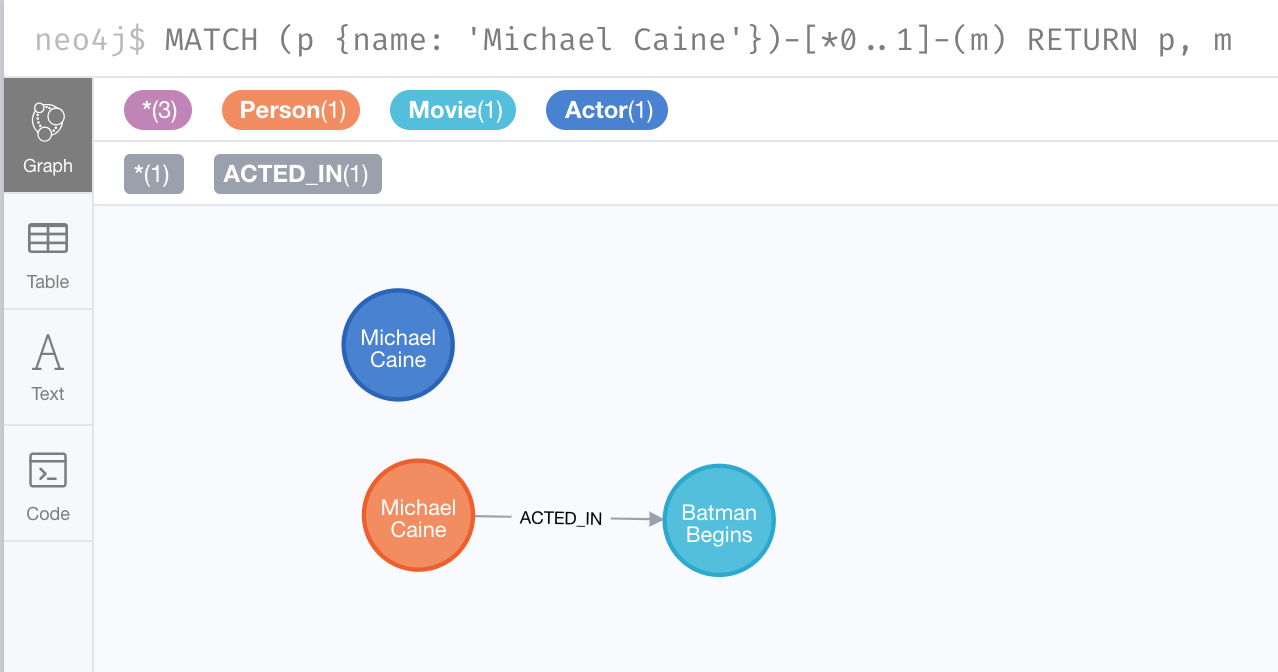
Example: Using MERGE to create relationship
Here is code where we want to create the :ACTED_IN relationship between Michael Caine and the movie Batman Begins.
MATCH (p {name: 'Michael Caine'}),(m:Movie {title:'Batman Begins'})
MERGE (p)-[:ACTED_IN]->(m)
RETURN p,mHere is the result of running this code:
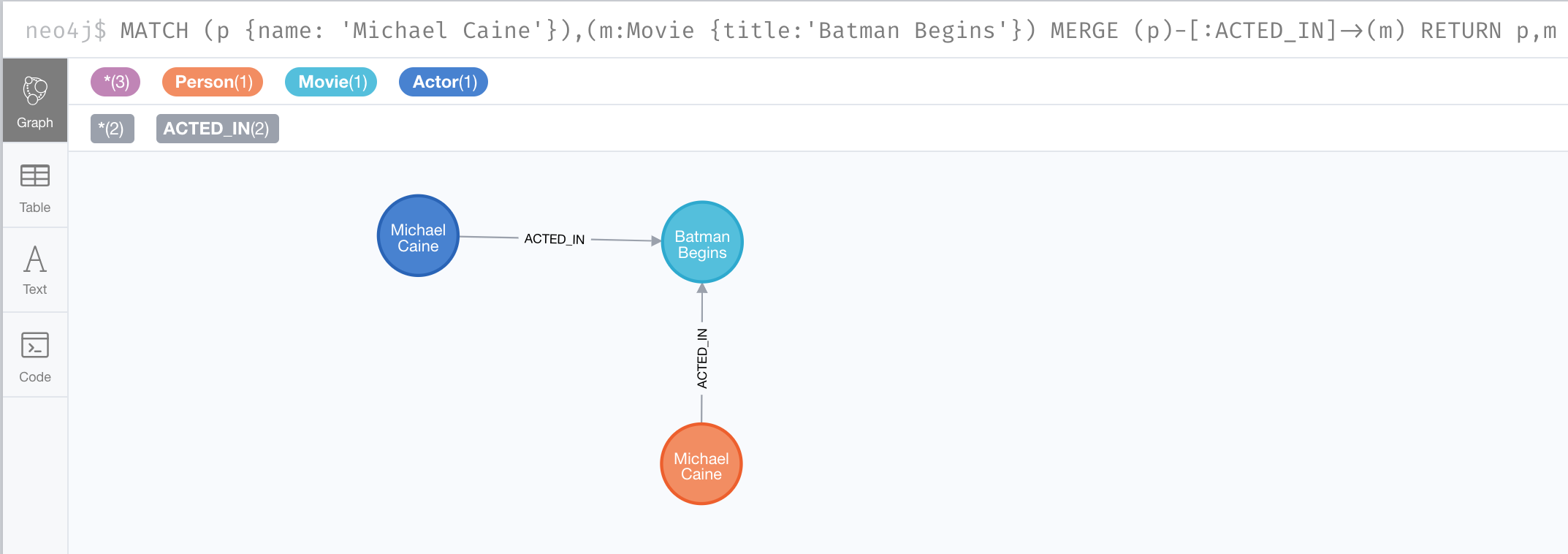
Since the relationship between the Person node and the Movie node already exists, it is not created. The relationship between the Actor node and the Movie node is created with this merge.
Although, you can leave out the direction of the relationship being created with the MERGE, in which case a left-to-right arrow will be assumed, a best practice is to always specify the direction of the relationship. However, if you have bidirectional relationships and you want to avoid creating duplicate relationships, you must leave off the arrow.
|
Specifying creation behavior when merging
You can use the MERGE clause, along with ON CREATE to assign specific values to a node being created as a result of an attempt to merge.
Here is an example where create a new node, specifying property values for the new node:
MERGE (a:Person {name: 'Sir Michael Caine'})
ON CREATE SET a.birthPlace = 'London',
a.born = 1934
RETURN aWe know that there are no existing Sir Michael Caine Person nodes.
When the MERGE executes, it will not find any matching nodes so it will create one and will execute the ON CREATE clause where we set the birthplace and born property values.
Here is the result of executing this code:
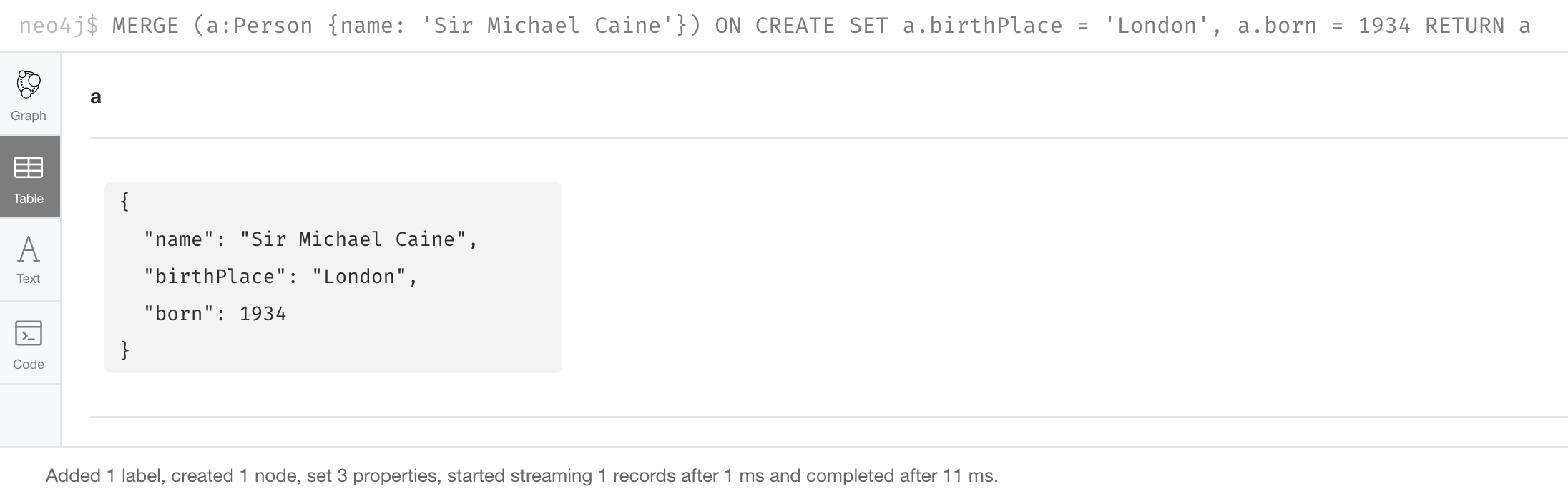
Specifying update behavior when merging
You can also specify an ON MATCH clause during merge processing.
If the exact node is found, you can update its properties or labels. Here is an example:
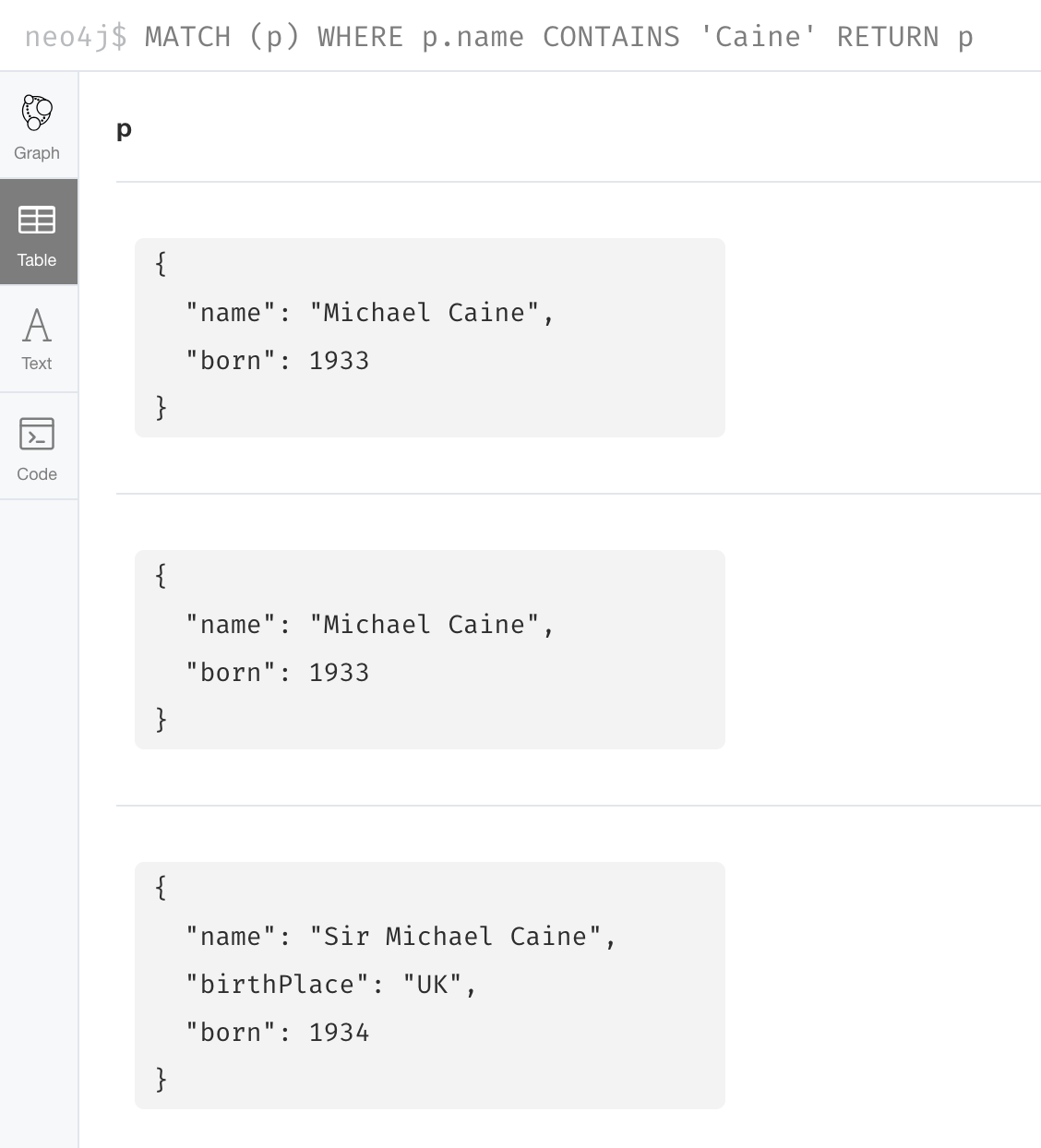
MERGE (a:Person {name: 'Sir Michael Caine'})
ON CREATE SET a.born = 1934,
a.birthPlace = 'UK'
ON MATCH SET a.birthPlace = 'UK'And here we see that only the existing node with the name, Sir Michael Caine is updated with the new birthPlace. Furthermore, no new node is created for Sir Michael Caine.
Using MERGE to create relationships
Using MERGE to create relationships is expensive, only do it when you need to ensure that a relationship is unique and you are not sure if it already exists.
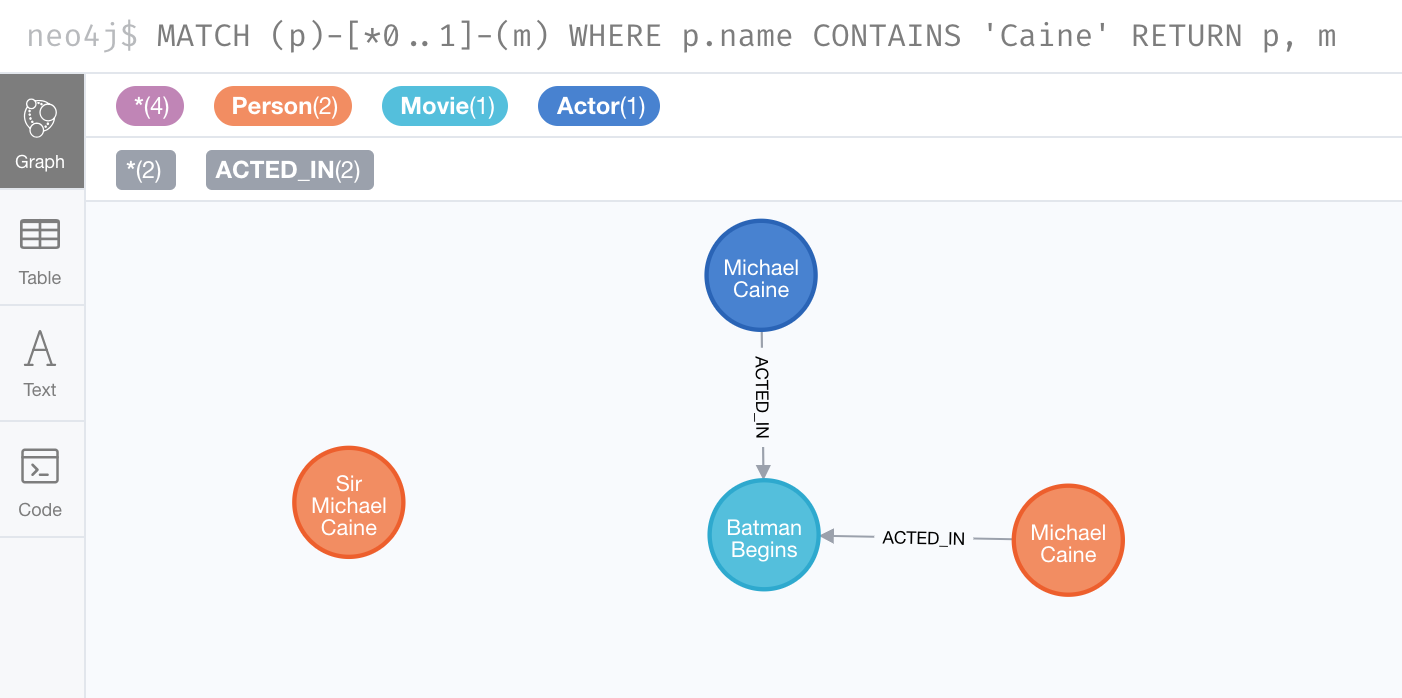
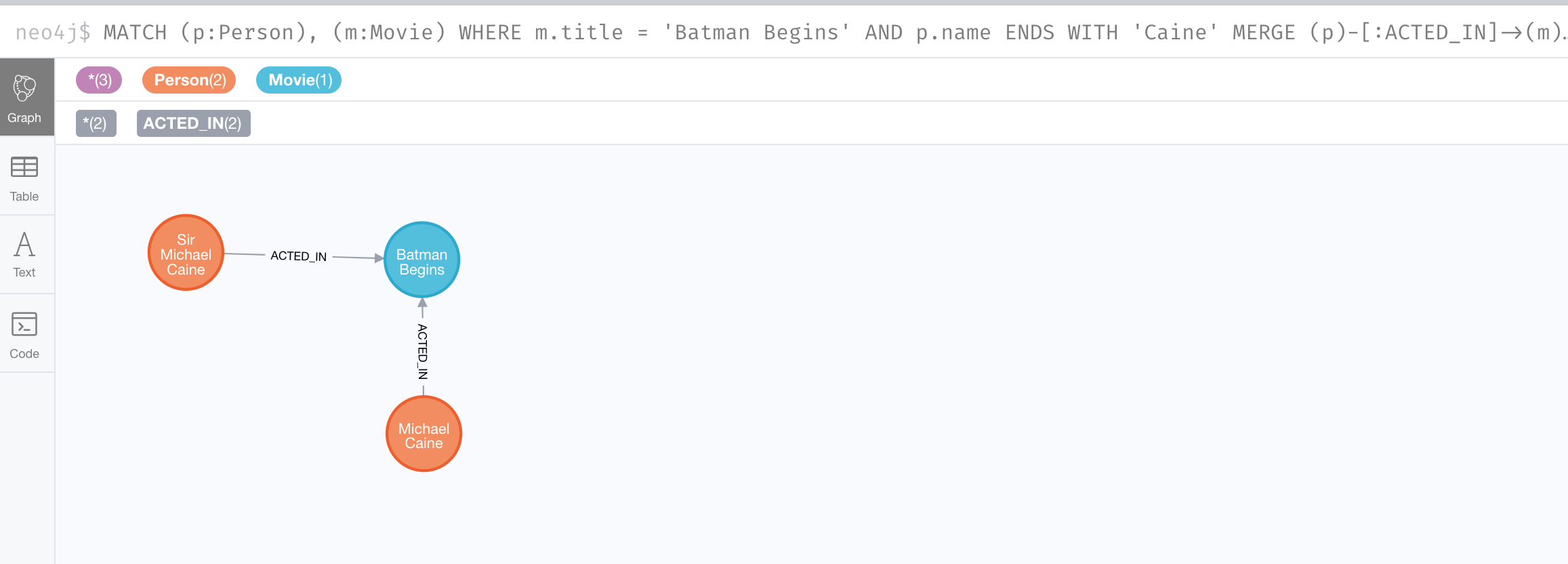
In this example, we use the MATCH clause to find all Person nodes that represent Michael Caine and we find the movie, Batman Begins that we want to connect to all of these nodes. We already have a connection between one of the Person nodes and the Movie node. We do not want this relationship to be duplicated. This is where we can use MERGE as follows:
MATCH (p:Person), (m:Movie)
WHERE m.title = 'Batman Begins' AND p.name ENDS WITH 'Caine'
MERGE (p)-[:ACTED_IN]->(m)
RETURN p, mHere is the result of executing this Cypher statement. It went through all the nodes and added the relationship to the nodes that didn’t already have the relationship.
You must be aware of the behavior of the MERGE clause and how it will automatically create nodes and relationships.
MERGE tries to find a full pattern and if it doesn’t find it, it creates that full pattern.
That’s why in most cases you will first MERGE your nodes and then your relationship afterwards.
Use MERGE carefully
Only if you intentionally want to create a node within the context of another (like a month within a year) then a MERGE clause with one bound and one unbound node makes sense.
For example:
MATCH (fromDate:Date {year: 2018})
MERGE (toDate:Date {month: 'January'})-[:IN_YEAR]->(fromDate)Exercise 12: Merging data in the graph
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-intro-neo4j-exercises
and follow the instructions for Exercise 12.
| This exercise has 16 steps. Estimated time to complete: 45 minutes. |
Check your understanding
Question 1
Given this MERGE clause, what is the most important thing you must make sure of?
MERGE (p:Person {name: 'Jane Doe'})
SET p.born = 1990
RETURN pSelect the correct answer.
-
The Person label exists in the graph.
-
The Person label does not exist in the graph.
-
The value for name is unique.
-
The value for born is unique.
Question 2
Given this MERGE clause, suppose that the p and m nodes exist in the graph.
What does this code do?
MATCH (p {name: 'Jane Doe'}),(m:Movie {title:'The Good One'})
MERGE (p)-[:ACTED_IN]->(m)Select the correct answers.
-
If the :ACTED_IN relationship exists, it deletes it and recreates it.
-
If the :ACTED_IN relationship exists, it does nothing.
-
If the :ACTED_IN relationship does not exist, it creates it.
-
If the :ACTED_IN relationship does not exist, it creates another one.
Question 3
Given this MERGE clause, suppose that the p and m nodes exist in the graph, but you do not know whether the relationship exists.
What are your options to process this MERGE clause?
MATCH (p {name: 'Jane Doe'}),(m:Movie {title:'The Good One'})
MERGE (p)-[rel:ACTED_IN]->(m)
SET rel.role=['role']Select the correct answers.
-
Use the default behavior. The relationship will be created if it doesn’t exist.
-
Specify
ON CREATEto perform additional processing when the relationship is created. -
Specify
ON MATCHto perform additional processing when the relationship is not created. -
Specify
ON DELETEto perform additional processing when the relationship is deleted.
Summary
You can now write Cypher statements to:
-
Merge data in a graph by:
-
Creating nodes.
-
Creating relationships.
-
Need help? Ask in the Neo4j Community