Northwind Recommendation Engine
Recently, I was asked to pitch a method for providing recommendations. Luckily, armed with the knowledge obtained from talks from Max De Marzi and Mark Needham at a recent Neo4j London Meetups, I knew this could be easily achieved with Neo4j.
The key issue with recommendation engines comes from the data. Luckily, Neo4j comes bundled with the Northwind Graph Example. The Northwind database is an infamous dataset containing purchase history that has been used to teach relational databases for years and was a great place to start.
You can import the Northwind database into a graph by following the "Import Data into Neo4j" post on Neo4j or type the following into Neo4j’s browser, e.g. empty database in Neo4j Desktop or a blank sandbox.
:play northwind graph
Here is how to load the data manually:
Now we’ve got some data, let’s start to explore the dataset.
Dataset
The Northwind Graph provides us with a rich dataset, but primarily we’re interested in Customers and their Orders. In a Graph, the data is modelled like so:

Popular Products
To find the most popular products in the dataset, we can follow the path from :Customer to :Product
match (c:Customer)-[:PURCHASED]->(o:Order)-[:PRODUCT]->(p:Product)
return c.companyName, p.productName, count(o) as orders
order by orders desc
limit 5Content Based Recommendations
The simplest recommendation we can make for a Customer is a content based recommendation.
Based on their previous purchases, can we recommend them anything that they haven’t already bought?
For every product our customer has purchased, let’s see what other customers have also purchased.
Each :Product is related to a :Category so we can use this to further narrow down the list of products to recommend.
match (c:Customer)-[:PURCHASED]->(o:Order)-[:PRODUCT]->(p:Product)
<-[:PRODUCT]-(o2:Order)-[:PRODUCT]->(p2:Product)-[:PART_OF]->(:Category)<-[:PART_OF]-(p)
WHERE c.customerID = 'ANTON' and NOT( (c)-[:PURCHASED]->(:Order)-[:PRODUCT]->(p2) )
return c.companyName, p.productName as has_purchased, p2.productName as has_also_purchased, count(DISTINCT o2) as occurrences
order by occurrences desc
limit 5Pretty standard so far.
Collaborative Filtering
Collaborative Filtering is a technique used by recommendation engines to recommend content based on the feedback from other Customers. To do this, we can use the k-NN (k-nearest neighbors) Algorithm. k-N works by grouping items into classifications based on their similarity to eachother. In our case, this could be ratings between two Customers for a Product. To give a real world example, this is how sites like Netflix make recommendations based on the ratings given to shows you’ve already watched.
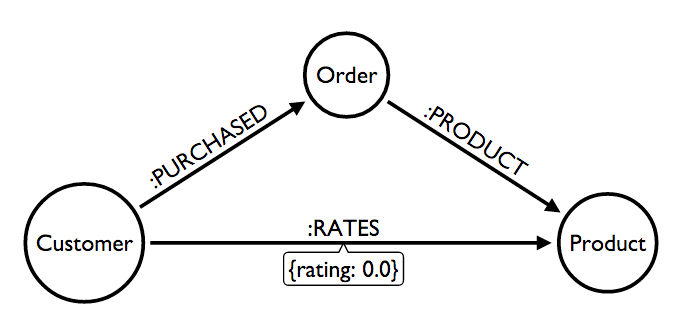
The first thing we need to do to make this model work is create some "ratings relationships". For now, let’s create a score somewhere between 0 and 1 for each product based on the number of times a customer has purchased a product.
MATCH (c:Customer)-[:PURCHASED]->(o:Order)-[:PRODUCT]->(p:Product)
WITH c, count(p) as total
MATCH (c)-[:PURCHASED]->(o:Order)-[:PRODUCT]->(p:Product)
WITH c, total,p, count(o)*1.0 as orders
MERGE (c)-[rated:RATED]->(p)
ON CREATE SET rated.rating = orders/total
ON MATCH SET rated.rating = orders/total
WITH c.companyName as company, p.productName as product, orders, total, rated.rating as rating
ORDER BY rating DESC
RETURN company, product, orders, total, rating LIMIT 10Now our model should look something like this:
MATCH (me:Customer)-[r:RATED]->(p:Product)
WHERE me.customerID = 'ANTON'
RETURN p.productName, r.rating limit 10Now we can use these ratings to compare the preferences of two Customers.
// See Customer's Similar Ratings to Others
MATCH (c1:Customer {customerID:'ANTON'})-[r1:RATED]->(p:Product)<-[r2:RATED]-(c2:Customer)
RETURN c1.customerID, c2.customerID, p.productName, r1.rating, r2.rating,
CASE WHEN r1.rating-r2.rating < 0 THEN -(r1.rating-r2.rating) ELSE r1.rating-r2.rating END as difference
ORDER BY difference ASC
LIMIT 15Now, we can create a similarity score between two Customers using Cosine Similarity (Hat tip to Nicole White for the original Cypher query…)
MATCH (c1:Customer)-[r1:RATED]->(p:Product)<-[r2:RATED]-(c2:Customer)
WITH
SUM(r1.rating*r2.rating) as dot_product,
SQRT( REDUCE(x=0.0, a IN COLLECT(r1.rating) | x + a^2) ) as r1_length,
SQRT( REDUCE(y=0.0, b IN COLLECT(r2.rating) | y + b^2) ) as r2_length,
c1,c2
MERGE (c1)-[s:SIMILARITY]-(c2)
SET s.similarity = dot_product / (r1_length * r2_length)MATCH (me:Customer)-[r:SIMILARITY]->(them)
WHERE me.customerID='ANTON'
RETURN me.companyName, them.companyName, r.similarity
ORDER BY r.similarity DESC limit 10Great, let’s now make a recommendation based on these similarity scores.
WITH 1 as neighbours
MATCH (me:Customer)-[:SIMILARITY]->(c:Customer)-[r:RATED]->(p:Product)
WHERE me.customerID = 'ANTON' and NOT ( (me)-[:RATED|PRODUCT|ORDER*1..2]->(p:Product) )
WITH p, COLLECT(r.rating)[0..neighbours] as ratings, collect(c.companyName)[0..neighbours] as customers
WITH p, customers, REDUCE(s=0,i in ratings | s+i) / LENGTH(ratings) as recommendation
ORDER BY recommendation DESC
RETURN p.productName, customers, recommendation LIMIT 10There you have it! Quick and simple recommendations using Neo4j.
Is this page helpful?