Concepts
This chapter deals with various concepts that are applicable for all modules offered. Especially checkout the page regarding naming conventions, for all Cypher and Java-based migrations and callbacks.
Connectivity
Neo4j-Migrations solely uses the Neo4j Java Driver.
Most of the time you pass a pre-configured driver object to our API.
The Spring-Boot-Plugin depends on the driver-instance provided by Spring-Boot which can be configured via properties in the spring.neo4j.* space.
The CLI and Maven-Plugin offer parameters to define the URL, username and password alike.
All of this mean that we can keep this chapter short and basically defer to the driver’s documentation:
The Neo4j Java Driver Manual v4.4.
For ease of use, here are the most common forms of URLs the driver might take.
The URLS all have this format: <NEO4J_PROTOCOL>://<HOST>:<PORT>.
The Neo4j-Protocol might be one of the following:
| URI scheme | Routing | Description |
|---|---|---|
|
Yes |
Unsecured |
|
Yes |
Secured with full certificate |
|
Yes |
Secured with self-signed certificate |
|
No |
Unsecured |
|
No |
Secured with full certificate |
|
No |
Secured with self-signed certificate |
You don’t have to care much more about the Driver API than knowing how to create an instance:
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Config;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
class HowToCreateADriverInstance {
public static void main(String... args) {
Driver driver = GraphDatabase.driver(
"neo4j://your.database.io",
AuthTokens.basic("neo4j", "secret"),
Config.defaultConfig()
);
}
}This instance needs to be passed than to the Neo4j-Migrations Core API in case you aren’t using one of our integrations. Mostly everything else than can be done via Cypher scripts alone. If you need more control about what happens in a migration, have a look at our Java-based migration support.
Migrations
Migrations are all operations or refactorings you apply to a database. These operations might be creating, changing, or dropping indexes and constraints or altering data. Sometimes you might even want to create users or databases.
Cypher (.cypher), Catalog-based (.xml) and class based (i.e. .java or .kt) based migrations require a certain naming
convention to be recognized:
V1_2_3__Add_last_name_index.(cypher|xml|java)-
Prefix
Vfor "Versioned migration" orRfor "Repeatable migration" -
Version with optional underscores separating as many parts as you like
-
Separator:
__(two underscores) -
Required description: Underscores or spaces might be used to separate words
-
Suffix: Depending on the given type.
Exceptions are made for callbacks (see naming conventions) and some extensions supported by Neo4j-Migrations.
Cypher-based
Cypher-based migrations can be mostly anything you can write down as Cypher statement.
A Cypher-based migration can contain one or more statements with multiple lines separated by a ; followed by a new line.
By default, all statements in one script will be executed in a single transaction.
Here’s an example:
CREATE (agent:`007`) RETURN agent;
UNWIND RANGE(1,6) AS i
WITH i CREATE (n:OtherAgents {idx: '00' + i})
RETURN n
;This script contains two different statements.
Neo4j-Migrations will by default look in classpath:neo4j/migrations for all *.cypher files matching the name described in
Naming conventions. You can change (or add to this default) with the Core API or the appropriate properties in
Spring-Boot-Starter or the Maven-Plugin like this:
MigrationsConfig configLookingAtDifferentPlaces = MigrationsConfig.builder()
.withLocationsToScan(
"classpath:my/awesome/migrations", (1)
"file:/path/to/migration" (2)
).build();| 1 | Look at a different place on the classpath |
| 2 | Look additional at the given filesystem path |
Switching database inside Cypher scripts
With the command :USE
The command :USE has the same meaning as in Neo4j-Browser or Cypher-Shell: All following commands will be applied in the given database.
The transaction mode will be applied as configured per database and will "restart" when you switch the database again.
This is the preferred way of doing things like this:
:USECREATE database foo IF NOT EXISTS WAIT;
:use foo;
CREATE (n:InFoo {foo: 'bar'});
:use neo4j;
CREATE (n:InNeo4j);With the Cypher keyword USE
It is of course possible to use the Cypher keyword USE <graph> (See USE) inside your scripts.
There are a couple of things to remember, though:
-
It can get tricky if you combine it in creative ways with the options for schema- and target-databases Neo4j-Migrations offer itself
-
If you have more than one statement per script (which is completely not a problem) and one of them should use
USEyou must configure Neo4j-Migrations to useTransactionMode#PER_STATEMENT(see Transactions, meaning to run each statement of a script in a separate transaction. This is slightly more error-prone, as it will most likely leave your database in an inconsistent state if one statement fails, since everything before has already been committed.
Based on a catalog
Migrations can be used to define a local catalog in an iterative fashion. Each migration discovered will contribute to a catalog
known in the context of a Migration instance.
Catalog based migrations are written in XML and can contain one <catalog /> item per migration and many <operation /> items
per migration.
The simplest way of defining a catalog based migrations looks like this:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<create>
<constraint name="unique_isbn" type="unique">
<label>Book</label>
<properties>
<property>isbn</property>
</properties>
</constraint>
</create>
</migration>Here a unique constraint is defined for the property isbn of all nodes labelled Book. This constraint is known only locally
and does not contribute to the contextual catalog.
This can also be rewritten such as this:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<catalog>
<constraints>
<constraint name="unique_isbn" type="unique">
<label>Book</label>
<properties>
<property>isbn</property>
</properties>
</constraint>
</constraints>
</catalog>
<create item="unique_isbn"/>
</migration>The constraint can be reused later, too:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<drop item="unique_isbn"/>
</migration>Indexes are supported, too:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<create>
<index name="node_index_name">
<label>Person</label>
<properties>
<property>surname</property>
</properties>
</index>
</create>
</migration>
The XML schema supports types for indexes as well: FULLTEXT and TEXT. The former being the well known
Lucene backed indexes, the latter the new TEXT index introduced in Neo4j.
|
To learn more about the scheme, have a look at the XML schema explained and also make sure you follow the concepts about catalogs as well as the catalog examples.
Last but not least, Neo4j-Migrations offers several built-in refactorings, modelled after APOC Refactor but without requiring APOC to be installed inside the database or cluster.
The example given in the APOC docs above can be identically modelled with the following catalog item:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<refactor type="rename.label">
<parameters>
<parameter name="from">Engineer</parameter>
<parameter name="to">DevRel</parameter>
<parameter name="customQuery"><![CDATA[
MATCH (person:Engineer)
WHERE person.name IN ["Mark", "Jennifer", "Michael"]
RETURN person
]]></parameter>
</parameters>
</refactor>
</migration>It will rename the label Engineer on all nodes matching the custom query to DevRel.
All supported refactorings are described in Refactorings.
What’s the advantage of using XML instead of a Cypher-based migration for this purpose? The syntax for defining constraints and indexes has been changed considerably over the last decade of Neo4j versions and many variants that used to be possible in Neo4j 3.5 have been deprecated for a while and will vanish in Neo4j 5.0.
With a neutral representation of constraints and indexes, we can translate these items into the syntax that fits your target database. In addition, we also can do idempotent operations on older databases that don’t actually have them.
Furthermore, some structured form is necessary for creating a representation of concepts like refactorings.
What’s the advantage of using Catalog-based migrations for the purpose of creating constraints and indexes for specific versions of Neo4j compared to Cypher-based migrations with preconditions? When using preconditions it us up to you to take care of newer versions of Neo4j as the come available as well as making sure you get the syntax right. Using a Catalog-based migration frees you from this duty. Preconditions have been available earlier than the concept of a catalog and can be used for many purposes (i.e. making sure actual data exists). In contrast to that, Catalog-based migrations have a very strong focus on actual schema items.
However, Catalog-based migrations offer support for preconditions too. They can be added as XML processing instructions anywhere in the document and look like this:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<?assert that edition is enterprise ?>
<?assume q' RETURN true?>
</migration>They can appear anywhere in the document, but we recommend putting them into the root element.
While both elements - constraint and index - do support a child element named options, these are not
rendered or used yet.
|
Java-based
Neo4j-Migrations provides the interface ac.simons.neo4j.migrations.core.JavaBasedMigration for you to implement.
Based on that interface you can do much more than just migrate things via adding or changing data:
You can refactor everything in your database in a programmatic way.
One possible migration looks like this:
package some.migrations;
import ac.simons.neo4j.migrations.core.JavaBasedMigration;
import ac.simons.neo4j.migrations.core.MigrationContext;
import org.neo4j.driver.Driver;
import org.neo4j.driver.Session;
public class V001__MyFirstMigration implements JavaBasedMigration {
@Override
public void apply(MigrationContext context) {
try (Session session = context.getSession()) { (1)
// Steps necessary for a migration
}
}
}| 1 | The MigrationContext provides both getSession() or getSessionConfig() to be used in combination with getDriver().
The latter is helpful when you want to have access to a reactive or asynchronous session.
It is important that you use the convenient method getSession() or create a session with the provided config as only
those guarantee hat your database session will be connected to the configured target database with the configured user.
In addition, our context will take care of managing Neo4j causal cluster bookmarks.
However, if you feel like it is necessary to switch to a different database, you can use the driver instance any way you want.
The transaction handling inside Java-based migrations is completely up to you. |
You don’t have to annotate your Java-based migrations in any way. Neo4j-Migrations will find them on the classpath as is. The same naming requirements that apply to Cypher scripts apply to Java-based migrations as well, see Naming conventions.
|
There are some restrictions when it comes to run Neo4j-Migrations on GraalVM native image:
You might or might not be able to convince the runtime to find implementations of an interface in native image.
You must at least explicitly include those classes in the native image unless used otherwise as well.
The CLI will outright refuse to scan for Java-based migrations in its native form (when using the --package option).
It does support them only in JVM mode.
|
While you can theoretically extend the public base interface Migration too, we don’t recommend it.
In fact, on JDK 17 we forbid it.
Please use only JavaBasedMigration as the base interface for your programmatic migrations.
Callbacks
Callbacks are part of a refactoring or a chain of migration that lives outside the chain of things.
As such these callbacks can be used to make sure certain data, constructs or other preconditions are available or fulfilled before anything else happens.
They also come in handy during integration tests.
You might want to have your migrations as part of the main source tree of your application and
at the same time have in your tests source tree the same folder with a bunch of callbacks that
create test data for example in an afterMigrate event.
Callbacks are not considered immutable after they have been invoked and their invocation is not stored in the history graph. This gives you a hook to add some more volatile things to your refactoring.
The beforeFirstUse callback is especially handy in cases in which you want to create the target database before migrations
are applied: It will always be invoked inside the home database of the connected user, so at this point, the target database
does not need to exist yet.
Be aware that for this to work you must specify both target and schema database: The schema database must exist
and cannot be created with a beforeFirstUse callback. This due to the fact that migrations will always be run inside
lock represented by a couple of Nodes.
An appropriate CLI call would look like this: neo4j-migrations --schema-database neo4j --database canBeCreatedWithCallback apply
A corresponding callback would contain: CREATE DATABASE canBeCreatedWithCallback IF NOT EXISTS;
|
Lifecycle phases
The following phases are supported:
- beforeFirstUse
-
The only phase that only runs once for any given instance of Neo4j-Migrations. It will run before any other operations are called, when the first connection is opened. Callbacks in this phase will always be invoked in the schema database and not the target database, so they won’t require the target database to be present. Also, no user impersonation will be performed. This can be used to create the target database before any migrations or validations are run.
- beforeMigrate
-
Before migrating a database.
- afterMigrate
-
After migrating a database, independent of outcome.
- beforeClean
-
Before cleaning a database.
- afterClean
-
After cleaning a database, independent of outcome.
- beforeValidate
-
Before validating a database.
- afterValidate
-
After validating a database, independent of outcome.
- beforeInfo
-
Before getting information about the target database.
- afterInfo
-
After getting information about the target database.
Using a catalog of items
Neo4j is a schema free or a database with little schema. There are labels for nodes, types for relationships and both can have properties. Hence, property graph. But there’s no "hard" schema determining that all nodes have all the same properties with the same type.
However, there are concepts to force the existence of properties on entities: Constraints. Constraints can also enforce uniqueness and keys; they go hand in hand with indexes. Constraints and indexes are what we refer to in Neo4j-Migrations as schema.
|
Why the heck XML? While XML has been badmouthed for a while now, it has a couple of advantages over JSON and YAML,
especially in terms of schema: There are many options to validate a given document, Document Type Definition (DTD)
and XML Schema being two of them. Neo4j-Migrations opted for the latter, it is documented in the appendix.
Most of your tooling should be able to load this and validate any migration for you and guide you to what is possible
and what not.
Our benefit lies in the fact that XML support comes directly with the JVM, and we don’t need to introduce any additional dependencies to parse and validate content. |
A catalog is also used to represent predefined or built-in refactorings, such as renaming all occurrences of types or labels.
What is a catalog?
Inside Neo4j-Migrations the concept of a catalog has been introduced. A catalog holds the same type of entities as a schema and migrations can pick up elements from the catalog to define the final schema.
Items can reside multiple times inside the catalog, identified by their id and the version of the migration in which they have been defined. This is so that a drop operation for example can refer to the last version of an entity applied to the schema and not to the latest, in which properties or options might have change.
Refactorings exists as a general concept in a catalog, they don’t need to be defined, but just declared as an operation to be executed.
How is a catalog defined?
The catalog comes in two flavors, the remote and the local catalog. The remote catalog - or in other words the catalog defined by the databases' schema - is the easier one to understand: It is a read-only view on all items contained in the database schema that Neo4j-Migrations supports, such as constraints and indexes. It can be retrieved on demand any time.
The local catalog is a bit more complex: It is build in an iterative way when discovering migrations. Catalog-based migrations
are read in versioning order. Items in their <catalog /> definition are required to have a unique id (name) per migration.
All items are added in a versioned manner to the local catalog. If an item named a is defined in both version n and n+x,
it will be accessible in the catalog in both variants. Thus, Neo4j-Migrations can for example support dropping of unnamed
items and recreating them in a new fashion. The approach of a versioned, local catalog also allows executing advanced operations
like verify: The verification of the remote catalog against the local catalog triggered in migration n+1 can refer to
the local catalog in version n (the default) to assert to ground for all following operations, or for the current version
to make sure everything exists in a given point in time without executing further operations.
Last but not least: Sometimes it is required to start fresh in a given migration. For this purpose the catalog element supports
an additional attribute reset. Setting this to true in any given migration will cause the catalog to be reset in this version.
Resetting means either being replaced with an empty catalog (<catalog reset="true" />) or replaced with the actual content.
Operations working with a catalog
Operations available to catalog based migrations are
create-
Creates an item
drop-
Drops an item
verify-
Verify the locally defined catalog against the remote schema
apply-
Drops all supported types from the remote schema and creates all elements of the local catalog.
refactor-
Executes one of several predefined refactorings
While create and drop work on single item, verify and apply work on the whole, known catalog in a defined version range.
A word on naming: Neo4j-Migrations requires unique names of catalog items across the catalog. In contrast to the
Neo4j database itself, using the name wurstsalat for both a constraint and an index is prohibited. Recommended
names in this case would be wurstsalat_exists and wurstsalat_index.
|
Both create and drop operations are idempotent by default.
This behaviour can be changed using ifNotExists and ifExists attributes with a value of false.
Be aware that idempotent does not mean "force", especially in the create case. If you want to update / replace an existing
constraint, and you are unsure if it does exist or not, use
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<drop item="a" ifExists="true" />
<create item="a" />
</migration>The drop operation will ensure that the constraint goes away, and the create operation will safely build a new one.
Verification (or assertions)
verify asserts that all items in the catalog are present in an equivalent or identical form in the database. This is a useful
step inside a migration to make sure things are "as you expect" before applying further migrations. Thus, it can only be
used before running any create, drop or apply commands.
The catalog items that are subject to the verification are by default made up from all prior versions to the migration
in which the verify appears. As an example, inside migration V2.1 a verify appears. All catalog items from versions
1.0 upto 2.0 will take part of the assertion. Items defined in 2.1 with the same name won’t be asserted, so that you can
assert a given state and then redefine parts of it for example.
This behavior can be changed by using the attribute latest, setting it to true on the element (<verify latest="true" />).
This will take the catalog as defined in this version.
Applying the whole catalog
apply on the other hands drops all items in the current physical schema and creates all items in state of the catalog
at the current version of migration. From the same example as above, everything from 1.0 upto and including 2.1 will be
included, definitions will be identified by their name respectively id.
The apply operation loads all supported item types from the database, drops them and then creates all items of
the local catalog. This is a potentially destructive operation as it might drop items you have no replacement for.
Also be aware that neo4j-migrations will never drop the constraints needed for the locking node to function proper (Basically, none of the constraints defined for the label __Neo4jMigrationsLock).
|
apply can’t be used together with drop or create in the same migration.
Executing refactorings
refactor is used to run parameterized predefined refactorings. The refactor element can be used after the verify operation and before, after or in between drop or create operations. It will be executed in the order in which it was defined. It cannot be used together with apply.
Have a look at the general catalog example or at the appendix for some concrete examples of executing predefined refactorings.
Create a catalog from the actual database schema
The API provides getDatabaseCatalog and getLocalCatalog methods.
The former reads all supported items in the Neo4j schema and creates a catalog view on them, the latter provides access
to the catalog defined by all migrations.
Those methods are used by the CLI to provide the ability to dump the whole database schema as a catalog definition in our own XML format or as Cypher script targeting a specific Neo4j version.
Last but not least, there’s public API ac.simons.neo4j.migrations.core.catalog.CatalogDiff.between that can be used to
diff two catalogs and evaluate whether they are identical, equivalent or different to each other.
Refactorings cannot be derived from an existing database.
Naming conventions
Cypher-based resources
All Cypher-based resources (especially migration and callback scripts) require .cypher as extension.
The Core API, the Spring-Boot-Starter and the Maven-Plugin will by default search for such Cypher scripts in classpath:neo4j/migrations.
The CLI has no default search-location.
Migration scripts
A Cypher script based migration must have a name following the given pattern to be recognized:
V1_2_3__Add_last_name_index.cypher-
Prefix
Vfor "Versioned migration" orRfor "Repeatable migration" -
Version with optional underscores separating as many parts as you like
-
Separator:
__(two underscores) -
Required description: Underscores or spaces might be used to separate words
-
Suffix:
.cypher
This applies to both Cypher scripts outside an application (in the file system) and inside an application (as resources).
| Cypher-based migrations scripts are considered to be immutable once applied. We compute their checksums and record it inside the schema database. If you change a Cypher-based migration after it has been applied, any further application will fail. By marking a migration as repeatable you indicate that it is safe to repeat it whenever its checksum changes. |
Callback scripts
A Cypher script is recognized as a callback for a given lifecycle if it matches the following pattern:
nameOfTheLifecyclePhase.cypher
nameOfTheLifecyclePhase__optional_description.cyphernameOfTheLifecyclePhase must match exactly (case-sensitive) the name of one of the supported lifecycle phases (see Lifecycle phases),
followed by an optional description and the suffix .cypher, separated from the name of the phase by two underscores (__).
The description is used to order different callback scripts for the same lifecycle phase.
If you use more than one script in the same lifecycle phase without a description, the order is undefined.
Callback scripts are not considered to be immutable and can change between execution.
If you use DDL statements such as CREATE USER or CREATE DATABASE in them make sure you look for an IF NOT EXITS
option in your desired clause so that these statements become idempotent.
|
Catalog-based migrations
Catalog-based migrations (See Using a catalog of items) are XML files based on the migration.xsd scheme. As such they require
the extension .xml and otherwise follow the same naming conventions as Cypher-based resources.
Java-based migrations
For Java (or actually anything that can be compiled to a valid Java class) based migrations, the same naming conventions apply as for
Cypher-based scripts apart from the extension.
To stick with the above example, V1_2_3__Add_last_name_index.cypher becomes V1_2_3__Add_last_name_index as simple class name,
or in source form, V1_2_3__Add_last_name_index.java.
Our recommendation is to use something like this:
public class V1_2_3__AddLastNameIndex implements JavaBasedMigration {
@Override
public void apply(MigrationContext context) {
// Your thing
}
@Override
public String getSource() {
return "Add last name index"; (1)
}
}| 1 | Defaults to the simple class name being added to the history chain. |
Chain of applied migrations
All migrations applied to a target database are stored in the schema database. The target and the schema database can be the same database. If you are an enterprise customer managing different databases for different tenants that are however used for the same application, it makes absolutely sense to use a separate schema database that stores all data related to Neo4j-Migrations.
The subgraph will look like this:
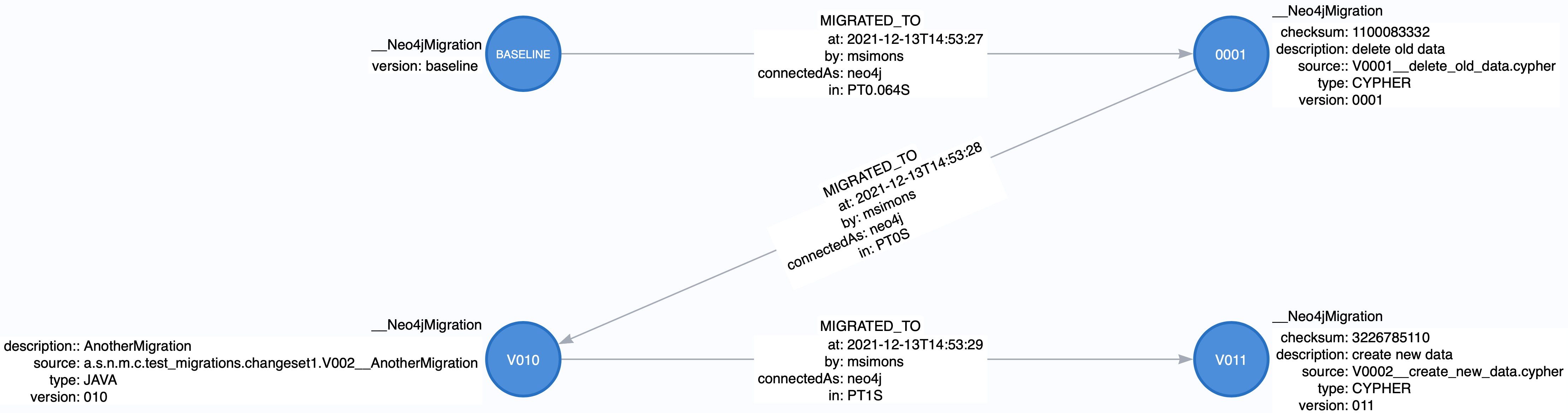
In case you use a schema database for any database with a different name than the default (which is neo4j) the nodes
labelled __Neo4jMigration will have an additional property name migrationTarget which contains the target graph.
Separate schema databases
Since version 1.1.0 you can use a different database for storing information about migrations.
You need to run a Neo4j 4+ Enterprise Edition.
The command line argument and the property, respectively, is schema-database throughout the configuration.
The name given must be a valid Neo4j database name (See Administration and configuration).
The database must exist and the user must have write access to it.
Valid scenarios are:
-
Using a schema database for one other database
-
Using a schema database for maintaining multiple migrations of different databases
-
Using pairs of schema databases and target databases
Neo4j-Migrations will create subgraphs in the schema database identifiable by a migrationTarget-property in the __Neo4jMigration-nodes.
Neo4j-Migrations will not record a migrationTarget for the default database (usually neo4j),
so that this feature doesn’t break compatibility with schemas created before 1.1.0.
| It is usually a good idea to separate management data (like in this case the chain of applied migrations) from you own data, whether the latter is created or changed by refactorings itself or by an application). So we recommend to use separated databases when you’re on enterprise edition. |
Transactions
All operations that are managed by Neo4j-Migrations directly, except catalog-based migrations, are executed inside transactional functions. This is essentially a scope around one or more statements which will be retried on certain conditions (for example, on losing connectivity inside a cluster setup).
You can configure if all statements of one Cypher-based migration go into one transactional function or if each statement goes into its own transactional scope:
MigrationsConfig configPerMigration = MigrationsConfig.builder()
.withTransactionMode(MigrationsConfig.TransactionMode.PER_MIGRATION)
.build();
// OR
MigrationsConfig configPerStatement = MigrationsConfig.builder()
.withTransactionMode(MigrationsConfig.TransactionMode.PER_STATEMENT)
.build();Per Migration is the default, as we think it’s safer: Either the whole migration is applied (or failed) or none. But there are certain scenarios that require a transaction per statement, for example most DDL operations such as creating databases might not be run together with DML operations in the same transaction.
| Catalog-based migrations - that is creation of indexes and constraints through the dedicated Neo4j-Migrations API - are always executed inside auto-commit transactions, as the underlying connectivity has some deficiencies that don’t allow retries or continuing using a transaction in some failure conditions that might happen during the creation of schema items. |
Preconditions
Our Cypher based migrations support a set of simple assertions and assumptions as preconditions prior to execution.
Preconditions can be added as a single-line Cypher comment to a script. Multiple preconditions in one script must all be
met (logically chained with AND).
- Assertions
-
Preconditions starting with
// assertare hard requirements. If they cannot be satisfied by the target database, Neo4j-Migrations will abort. - Assumptions
-
Preconditions starting with
// assumeare soft requirements. If they cannot be satisfied, the corresponding script will be skipped and not be part of any chain.
| If you think that preconditions might change (for example when asking for a specific version): Make sure you have alternative scripts with the same filename available, both having preconditions meeting the matching cases. We will treat them as alternatives and make sure that a changed checksum is not treated as an error. For example this would happen if you suddenly one migration has its precondition met which it didn’t before and therefore changing the chain of applied migrations. |
Require a certain edition
The Neo4j edition can be required with either
// assume that edition is enterpriseor
// assume that edition is community.Require a certain version
The Neo4j version can be required with
// assume that version is 4.3Multiple versions can be enumerated after the is separated by a ,.
Version ranges can be required with lt (lower than) or ge (greater than or equals), for example:
// assume that version is ge 4.0Both assumptions combined makes it safe to use version assumptions (see the warning above). We recommend using one refactoring for the minimum version you support and one for all higher that support the feature you want. For example: Your minimum supported database version is 4.3 and you want to create an existential constraint. You want to have 2 migrations:
// assert that edition is enterprise
// assume that version is 4.3
CREATE CONSTRAINT isbn_exists IF NOT EXISTS ON (book:Library) ASSERT exists(book.isbn);And the different one for 4.4 or higher:
// assert that edition is enterprise
// assume that version is ge 4.4
CREATE CONSTRAINT isbn_exists IF NOT EXISTS FOR (book:Library) REQUIRE book.isbn IS NOT NULL;The former will only applied to the 4.3, the latter to 4.4 or higher. If your user upgrades their database at some point, Neo4j-Migrations will recognize that it used an older, compatible script with it and wont fail, even though the new script has a different checksum.
Preconditions based on Cypher queries
You can require a precondition based on a query that must return a single, boolean value via
// assume q' RETURN trueThe above case will of course always be satisfied.
Here’s a complete example:
// assert that edition is enterprise
// assert that version is 4.4
// assume q' MATCH (book:Library) RETURN count(book) = 0
CREATE CONSTRAINT isbn_exists IF NOT EXISTS FOR (book:Library) REQUIRE book.isbn IS NOT NULL;This refactoring will only execute on Neo4j 4.4 enterprise (due to the requirements of existence constraints and the 4.4 syntax being used)
and will be ignored when there are already nodes labeled Library.
Why only preconditions for scripts?
Since we offer full programmatic access to migrations together with the context that has information about the Neo4j version, edition and access to both target and schema database, it would be duplicate work if we take the decision away from you. You are completely free inside a programmatic refactoring not to do anything in a given context. The migration will be dutifully recorded nevertheless.
Upgrading older database
Given that your application needs to support multiple versions of Neo4j, including versions that didn’t exist when you created your application originally and you might have invalid Cypher now in potentially already applied migrations you can do the following
-
Create subfolders in your migration locations or configure additional locations
-
Duplicate the migrations that contain Cypher that is problematic in newer Neo4j versions
-
Keep the names of the migrations identical and distribute them accordingly in these folders
-
Add a precondition matching only older versions of Neo4j to one and keep the rest unaltered
-
Adapt the other one containing only "good" syntax and add a precondition for the newer Neo4j version
Thus, you support the following scenarios:
-
On older database versions against which your application already ran, nothing will change; the migration with the fixed syntax will be skipped
-
Same for a clean slate on older database versions
-
On the newer database version, only the fixed syntax migration will be applied.
Was this page helpful?