

Cypher Performance Improvements in Neo4j 5

Director of Engineering, Neo4j
7 min read


In November 2024, we will see the release of the Long-Term Support version of Neo4j 5 (Neo4j 5.26 LTS). With that, we will have all the new features and new Cypher language constructs for Neo4j 5. Some of these are about extending the language and its capabilities, but many features have also been developed to improve the performance of Cypher queries.
Generic Performance Improvements
The language runtime and query planning are continuously improved and fine-tuned, as is the database kernel. Even without considering the specific features mentioned next, each release gets faster.
New Operators
We introduced some new operators as an example of the continuous performance improvements in Neo4j 5. The Neo4j query planner translates a Cypher query into a sequence of operators running on the Cypher runtime. In Neo4j 5, we introduce operators developed for specific actions. When the planner can use these instead of the existing, more generic operators, they can considerably speed up queries:
- UnionNodeByLabelsScan
- UnionRelationshipTypeScan
- IntersectionNodeByLabelsScan
- SubtractionNodeByLabelsScan
- VarLengthExpand(Pruning,BFS)
Learn more about operators in the Cypher Manual.
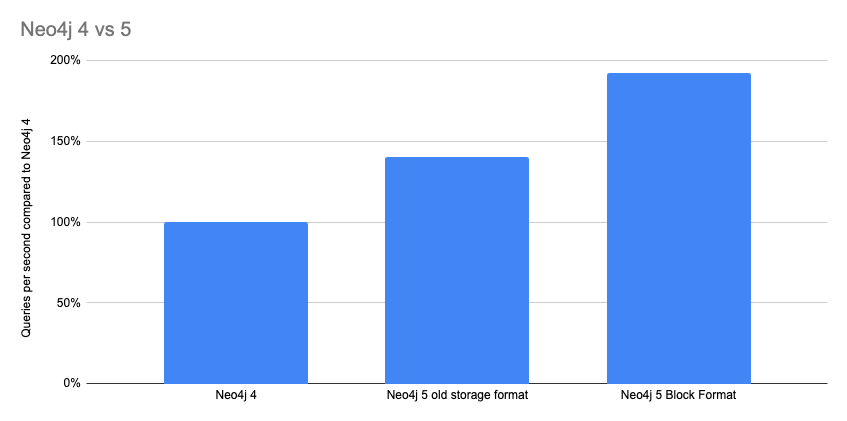
Block Format
As seen in the chart above, the new storage format — introduced and made default in Neo4j 5 — also has a big impact on Cypher performance.
Block format is a completely new way of laying out the data on disk, achieving vastly fewer I/O calls with more data inlining. This results in much faster query execution.

Read Try Neo4j’s Next-Gen Graph-Native Store Format to learn more about the block format.
Cypher Performance Features
Specific features to boost Cypher performance have been added. Some are optional, and some only apply to certain types of queries. None of them are used in the generic performance improvement shown in the first chart above.
Parallel Runtime
In Neo4j 4, Pipelined Runtime was introduced. This was about twice as fast as the slotted runtime and is now default in the Enterprise edition (and Aura). In Pipelined Runtime, the query is divided into pipelines that produce batches of roughly 100-1,000 rows each (referred to as morsels), which are written into buffers containing data and tasks for a pipeline.

The Pipelined Runtime executes in a single thread.
In some cases, with large analytical read queries that traverse a large portion of the graph and where multiple CPU cores are available, it is beneficial to divide the work into multiple threads, which is what the Parallel Runtime in Neo4j 5 does.

The Parallel Runtime supports read queries only and works best with long-running, analytical, graph-global queries (i.e., queries that touch a large proportion of the graph). The Parallel Runtime is configurable (for on-prem users), allowing users to select how many CPUs to make available to the Parallel Runtime. For many queries, performance scales almost linearly as additional CPUs are made available.
To use the Parallel Runtime, simply prefix the query with:
CYPHER runtime = parallel
...
For a simple query where we just list all unanswered questions, the improvement looks like this:
CYPHER runtime = parallel
MATCH (q:Question)
WHERE NOT EXISTS {(q)<-[:ANSWERED]-(:Answer)}
RETURN count(q) AS unanswered
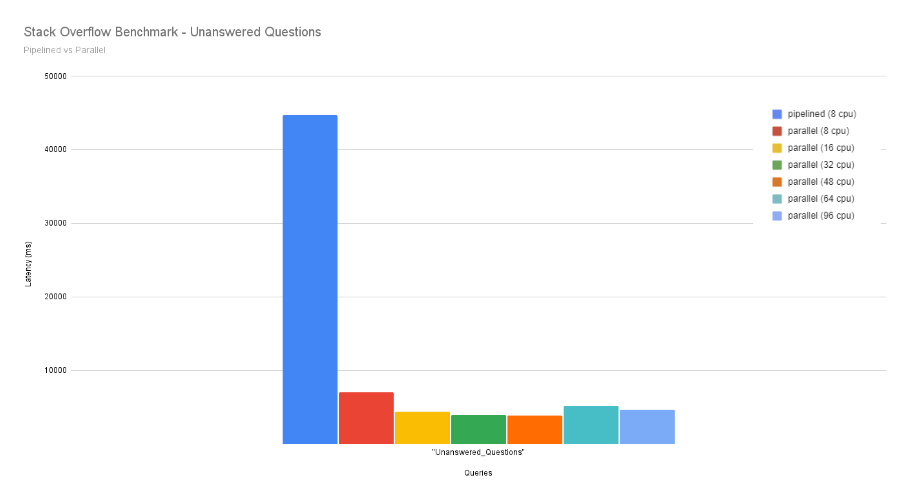
The image above shows some benchmarks reflecting the impact of Parallel Runtime on Stack Overflow data (a graph with 50 million nodes and 124 million relationships).
A more advanced query like this gets an even better improvement:
CYPHER runtime = parallel
MATCH (u:User)-[:POSTED]->(q:Question)-[:TAGGED]->(t:Tag)
WHERE $datetime <= q.createdAt < $datetime + duration({months: $months})
RETURN t.name AS name,
count(DISTINCT u) AS users,
max(q.score) AS score,
round(avg(count { (q)<-[:ANSWERED]-() }),2) AS avgAnswers,
count(DISTINCT q) AS questions
ORDER BY questions DESC
LIMIT 20

Read Speed Up Your Queries With Neo4j’s New Parallel Runtime to learn more about the parallel runtime.
CALL { … } IN CONCURRENT TRANSACTIONS
Parallel Runtime is currently for read-only queries. For write queries, users can take advantage of another Neo4j 5 feature: CIT concurrent, which splits transactions into sub-transactions and runs them concurrently. The sub-transactions can contain write operations, and the most common use case is for LOAD CSV.
CALL { … } IN TRANSACTIONS was released in Neo4j 5.7 and allows queries that generate a large number of rows to be split into multiple transactions to avoid running out of memory.
CALL { … } IN CONCURRENT TRANSACTIONS is an extension that allows these concurrent transactions to be run in parallel on multiple threads to boost performance.
LOAD CSV WITH HEADERS FROM 'https://myserver.com/mydata.csv' AS row
CALL (row) {
CREATE (...)
} IN 3 CONCURRENT TRANSACTIONS OF 100 ROWS
Check out the Cypher Manual to learn more about concurrent transactions. Learn more about concurrent writes in Introducing Concurrent Writes to Cypher Subqueries.
Label Inference
The core to performant queries in any database is query planning. This is the process of figuring out the most performant way to execute a query based on the statistics of the database data. This is continuously tweaked and improved in every version, but among the improvements, label inference stands out as a bigger initiative.
Query planning is done by analyzing ways to execute a query and estimating the cardinality of the different operators (i.e., how many rows they will likely result in, based on statistics about the graph) and picking the query that would likely be the fastest. The better the estimates, the more likely we will get an optimal query.
Label inference is a technique of getting more out of the existing statistics by applying more advanced deduction logic, and thus getting more optimal plans.

MATCH (admin:Administrator { name: $adminName }),(resource:Resource { name: $resourceName })
MATCH p=(admin)-[:MEMBER_OF]->()-[:ALLOWED_INHERIT]->(company)-[:WORKS_FOR|HAS_ACCOUNT]-()-[:WORKS_FOR|HAS_ACCOUNT]-(resource)
WHERE NOT ((admin)-[:MEMBER_OF]->()-[:DENIED]->(company))
RETURN count(p) AS accessCount
Please note that the impact of label inference depends on the query and the graph structure, and not all cases will see such a big improvement as this.
It should also be noted that label inference can cause existing query plans to change, and we cannot guarantee with certainty that some queries on some databases will not show regressions. To avoid that, it was added as an opt-in feature in Neo4j 5, with the plan of making it default in the next major version.
Label inference can be enabled by prefixing the query with:
CYPHER inferSchemaParts = most_selective_label
...
To learn more, see Query tuning.
It can also be enabled for all the queries across your Neo4j instance by using the following configuration option:
dbms.cypher.infer_schema_parts = MOST_SELECTIVE_LABEL
See Configuration settings to learn more.
Eagerness Analysis on Logical Plan
The quickest and most memory-efficient way to execute a query is for the next step in the query to start processing the rows from the previous step before it is done. If we want to summarize the wealth of all the people in a country, we don’t have to list all those people and then start summarizing their assets (which requires us to hold all those people in memory), but instead, we can start summing up the combined wealth as fetched people start coming in.
There are, however, cases where this isn’t possible. If, for example, we want to return the richest person in the country, we have to fetch them all before we can determine who has the most money. The operator is said to be “eager” — as it is eager to collect all rows before yielding a result.
Some operators, like max() in the above example, are eager by default. But in queries with both reads and writes, there may be a need to be eager even when no such operator is used. To determine that, the query planner performs an eagerness analysis of the query and inserts eager operators where needed. It has the goal of using as few as possible because the more it uses, the slower and more memory-consuming it gets. But missing an eager may lead to an incorrect result.
The method of eagerness analysis is rewritten in Neo4j 5 so that it performs the analysis on the logical plan instead of the intermediate representation. This new method is about 20 percent more eager-optimal (it plans fewer eager operators) than the old, meaning faster and more memory-efficient queries.
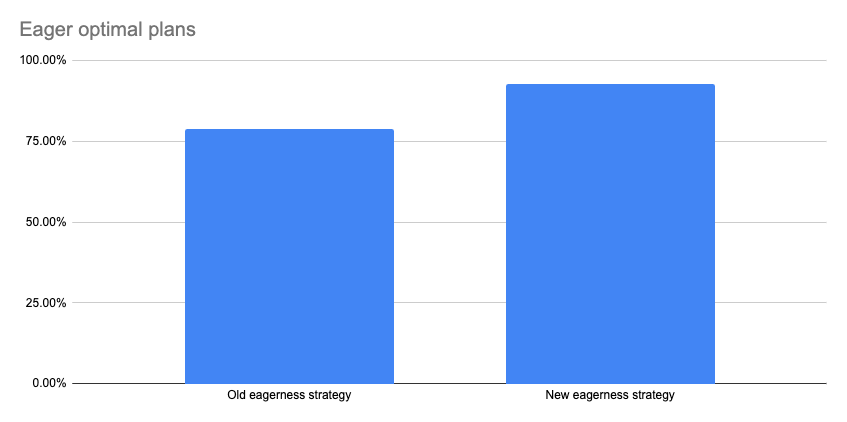
Another advantage is that it is more observable. If you investigate a query plan with EXPLAIN, you can see why it decided to add the eager operators it did.
New Language Constructs
As I mentioned in the beginning, there are also a lot of new constructs in the Cypher language in Neo4j 5. These do not have performance improvements as the main purpose, but since the lack of them required other, less-performant ways of achieving them, you could, in a sense, see them as performance improvements as well. Some examples of these are:
- Quantified Path Patterns
- Shortest path (based on Quantified Path Patterns)
- OPTIONAL CALL
- Dynamic labels
- Vector indexes
- UNION DISTINCT
- Normalized strings
- Change Data Capture
- Value types
- COUNT
Learn more about deprecations, additions, and compatibility in the Cypher Manual.
Cypher Performance improvements in Neo4j 5 was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Neo4j Sink Connector for Confluent Available as Managed Connector on Confluent Cloud

