Why it is time for you to migrate from apoc.periodic.iterate to CALL { … } IN TRANSACTIONS.

The popular plugin APOC Core has long been the bandage on the holes in Cypher, but with every release, those holes are getting smaller and fewer, and APOC is slowly being graduated away.
One great example of this is Cypher’s CALL {…} IN TRANSACTIONS (CIT). Over the past few years, features have been added to CIT, chipping away at the differences between it, and APOC’s apoc.periodic.iterate.
The procedure apoc.periodic.iterate has been used as a way to transactionally create, update and delete data in bulk, to attempt to avoid OOM issues as well as enhance speed by using the procedures threading capabilities. This blog will go through all the original use cases of apoc.periodic.iterate and show the equivalent use case in Cypher as well as explain why you should make the switch.
… IN TRANSACTIONS
Traditionally, a query is run in one transaction, so if the query was to error, be that with a simple mistake or with something worse like an OOM error or a timeout, then all changes made up to that point are lost and are rolled back. Another issue with running a bulk update in one query is the amount of temporary data stored in memory which increases the chance of an OOM error! This was a time old database issue that APOC solved by introducing apoc.periodic.iterate. This procedure exposes a batchSize argument, giving the query writer control over how many rows the procedure should run before committing. As you may have already guessed, this issue has now also been solved in Cypher with CALL IN TRANSACTIONS 😉
Memory Tracking
The main reason for switching might very well be memory tracking. The most significant thing CIT can do better than APOC is memory tracking! All runtime executed Cypher code has its memory usage tracked. Whilst user defined procedures/functions have the ability to track memory, that addition came many years after apoc.periodic.iterate was written, so this procedure does not have it. Memory tracking stops a query from crashing and causing issues with the database, if the query was to be near an OOM issue, then it will fail cleanly and rollback, in the case of an OOM crash (like what could happen in APOC), the issue is a lot larger, and may cause database downtime! This is a pretty bad issue, and definitely what I would call the nail in the coffin for this APOC procedure.
Ease of use and error hunting
But what are the other benefits of switching to CIT?
Let’s say we want to add a new property to our Nodes; favoriteNumber. For the purpose of this blog we will assume favourite numbers are always a random value greater than 0 and less than or equal to 20.
CALL apoc.periodic.iterate(
'MATCH (n:Person) RETURN elementId(n) AS id',
'MATCH (n:Person) WHERE elementId(n) = id SET n.favoriteNumber = toInteger(rand() * 20 + 1)',
{batchSize: 1000}
)
MATCH (n:Person)
CALL (n) {
SET n.favoriteNumber = toInteger(rand() * 20 + 1)
} IN TRANSACTIONS OF 1000 ROWS
So what are the main differences between these two queries? (We will discuss why APOC’s query is more complex further down) Firstly, the readability, not the most important, but the easiest to see. Cypher’s CIT version allows for any tool working with Cypher to format, apply auto-completion, keyword highlighting and so on. As well as to fail early on syntactic mistakes.
Let’s say we made a small typo in our query;
CALL apoc.periodic.iterate(
'MATCH (n:Person) RETURN elementId(n) AS id',
'MATCH (n:Person) WHERE elementId(n) = id SET m.favoriteNumber = toInteger(rand() * 20 + 1)',
{batchSize: 1000}
)
MATCH (n:Person)
CALL (n) {
SET m.favoriteNumber = toInteger(rand() * 20 + 1)
} IN TRANSACTIONS OF 1000 ROWS
Do you see it? Tricky right? The issue here is that the SET references a variable called m, but our node variable is actually called n. How does this show up for a user? For the APOC version, they see the query as written, the actual Cypher queries are represented as STRING values and thus their contents are ignored by any tool, when it is run a result is also returned! Hurrah thinks the user, it worked, but on closer inspection, the results say:
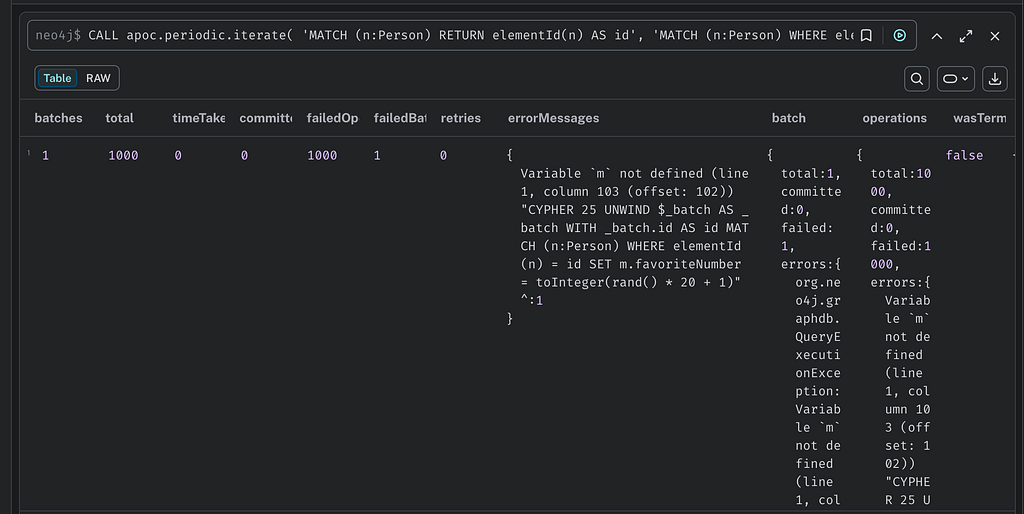
This error message is hard to read, not only because it came back from a positive result, but also because the batching logic supplied by APOC is to prepend the query with the Cypher version and UNWIND clause, making the query look quite different from what was written. We can see that there is an undefined variable m, but as this is also represented as text, the formatting gets messy. Imagine trying to find this error in a much larger query!
On the Cypher side, when I type out that query, before even running it I see the red squiggly line:

and if I were to run it, ignoring that line, the query errors and I get a clear message that shows me what to do:

Query Planning
So aside from readability, what about the query plan? When tweaking queries, it is good to know how Cypher has planned it, and what one could do to change it, in this case, the plan is going to be pretty simple:
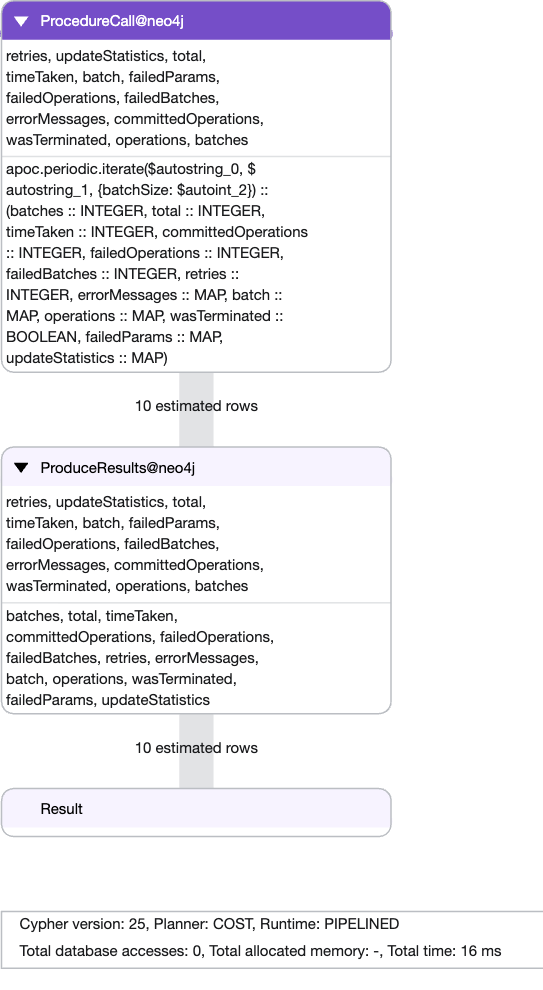
TIP: to generate the plan, prepend your query with EXPLAIN
The APOC plan is very simple; procedure call, procedure result, zero information about the actual queries run, zero room for optimisation.
For the CIT variant however, the Cypher engine can plan for the entire query, showing the usage of a Label Scan and SetProperty! If this was a more complicated query, one can see how this plan can become vital in query optimisation.
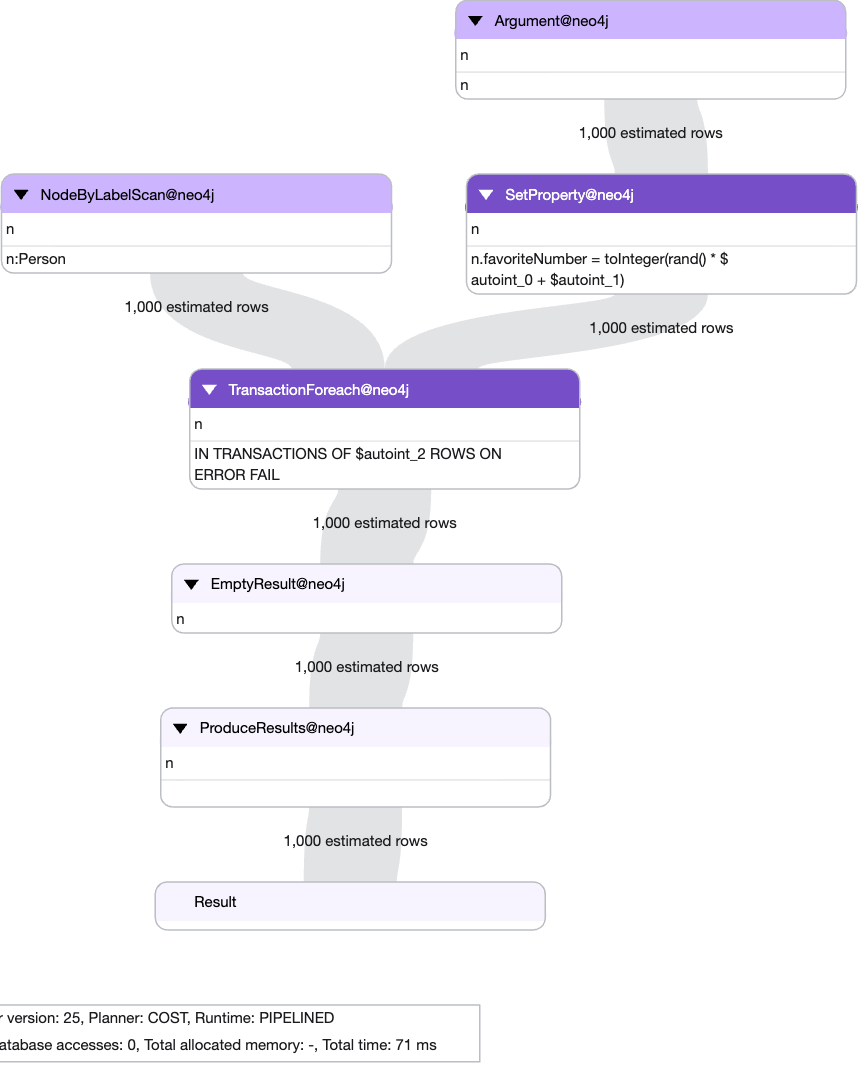
Query Statistics
Cypher also has built in query statistics, once a query is run, the result returns with information about how many nodes and relationships were created, updated and deleted. The APOC run query returns believing that nothing has changed, whereas the Cypher one correctly informs the user the number of node properties that were updated. APOC does consolidate the changes by returning them as a column in its result set, but as it just adds together all the results from the run inner queries, this result is not always accurate.
Entity Rebinding
Another issue with the APOC procedure is the way Neo4j handles nodes and relationship transactions. A fetched node or relationship references the transaction it was fetched from, meaning it is a big no, no to share this entity across different transactions. This means that in APOC the recommended, and only safe way of passing nodes and relationships between the original query and the iterating query, is to reference the entity’s id. This is why in the example query the APOC version returns the node’s elementId() and then rematches on it. This is what APOC calls rebinding. This is less efficient because the work for fetching a node or relationship has to be done twice by APOC, once to fetch the id and then once to fetch by that id. If this step is skipped, this can lead to OOM issues and/or invalid reference errors. This is not an issue in CIT as those transactions are handled directly by Cypher’s runtime engine.
Concurrency
A big benefit of apoc.periodic.iterate was the parallel feature. When this argument is true, APOC spins up threads that are then executed concurrently, hopefully speeding up the query execution. Cypher’s CIT has also caught up with its own … IN CONCURRENT TRANSACTIONS syntax. See the documentation for the recommended usage of this feature.
ON ERROR RETRY
The final feature missing from Cypher was added early 2025 (Neo4j’s 2025.03 release) and was the ON ERROR RETRY feature. This replaces the final APOC config parameter retries as a way to combat any transient errors (i.e. errors where retrying a transaction can be expected to give a different result). This was added to the already existing plethora of ON ERROR options supplied by CIT, see the documentation for more details.
Future improvements
The final reason we recommend to replace your usages of apoc.periodic.iterate with Cypher’s CIT is that our Cypher engineers are working hard on always improving the language, and this means that the performance is always improving as well as timely bug fixes are being constantly made.
The APOC core plugin is under what we call maintenance mode, this means that the engineering team is not actively improving it or adding new features. Bugs and security issues are still fixed but this means that improvements are a lot more likely to be seen on Cypher’s CIT than on APOC.
Conclusion
And that was it! All the reasons why Cypher queries looking to run with multiple transactions should choose CALL IN TRANSACTIONS over apoc.periodic.iterate! By switching to CIT, you are choosing a cleaner, more performant, and actively developed feature that secures your applications against critical errors like OOM crashes, while improving your overall developer experience.
See Cypher’s documentation for help on how to get started with CIT today!
Batching Like a Pro was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3