Agentic RAG: What it is, how it works, and when to use it


17 min read
Agentic RAG is a form of retrieval-augmented generation where an AI agent controls the retrieval process. Instead of following standard RAG’s fixed, one-shot retrieve-then-generate pipeline, the agent decides when to retrieve, which tools or sources to query, and whether the results are sufficient to answer. It iterates until it has enough grounded context or reaches a defined stopping point.
Standard RAG works well for straightforward prompts over a scoped corpus, but it breaks down when the answer depends on multiple steps, spans several sources, or requires validating evidence before responding. The result: answers that are incomplete, unverifiable, or simply wrong. This is where agentic RAG is the better choice, filling the gaps to provide better answers.
In this blog post, we’ll cover how agentic RAG works, where it fits best, and which architecture patterns apply. We’ll also go over what you gain and trade off, how to implement and evaluate it, and why GraphRAG gives you a strong retrieval foundation.
More in this guide:
How does agentic RAG work?
Agentic RAG starts with an AI agent understanding the user query and reasoning how to answer it. Unlike standard RAG, agentic RAG involves planning, tool selection, and multiple rounds of retrieval and evaluation before generation. It goes through this agentic workflow in a loop until it has enough context to provide a good answer.
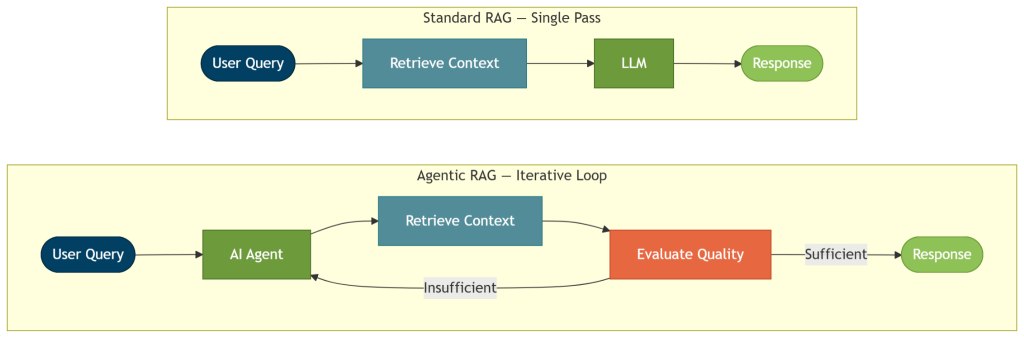
The answer is more reliable because the agent takes the time to inspect the evidence and correct course if needed before responding. You can also expose the retrieval path, tool usage, and supporting context, making answers easier to audit and explain.
Traditional RAG vs. agentic RAG: when to use which?
You don’t need an agentic loop for every task. Start with standard RAG if the questions are simple and one retrieval pass can answer them. Move to agentic RAG to answer complex questions that require multi-step reasoning, routing, or validation before answering.
Agentic RAG comes with real costs, though. Token use goes up. Latency grows with each loop, retrieval step, and validation pass. Failures can surface at any stage, from planning and retrieval to tool use, orchestration, or stopping logic. Reflection and iteration only improve results when they target a specific gap; otherwise, they just add costs.
The following table provides a snapshot of the basics of standard RAG versus agentic RAG.
| Dimension | Standard RAG | Agentic RAG |
| What it works best for | Simple grounded information search over a scoped corpus | Multi-step reasoning, cross-source synthesis, and validation-heavy tasks |
| Workflow | One-shot retrieve-then-generate flow, sometimes improved with reranking or query rewriting | Adaptive loop with planning, retrieving, evaluation, and stopping rules |
| Speed and cost | Lower token use and lower latency | Higher token use and more latency per query |
| Reliability and failure surface | Easier to debug; failures can only occur in retrieval or generation. | Failures can happen across multiple steps of planning, retrieval, tool use, validation, orchestration or generation. |
| Retrieval strategy | Often one primary retrieval path | Can route across tools, retrievers, graph queries, and multiple sources |
Common agentic RAG design patterns
The most common agentic RAG design patterns span a simple reasoning loop to multi-agent coordination. Start with the simplest pattern that solves the specific retrieval or quality problem in front of you. Complexity is only worth adding when you can clearly name the failure it fixes. Better architecture decisions usually matter more than longer agent loops.
ReAct RAG
When to use it: ReAct (Reasoning + Acting) is the most foundational agentic RAG pattern. It’s the right starting point for most implementations — before you decide to layer in routers, validators, or additional agents — as it solves most standard RAG issues.
How it works: The agent cycles through three steps: It produces a “Thought” (reasoning about what information it still needs), takes an “Action” (calling a retrieval tool: vector search, a keyword search, a document lookup), and receives an “Observation” (the retrieval result) that feeds the next reasoning step. The loop continues until the agent has enough grounded context to provide a sufficient answer or reaches a defined stopping point.

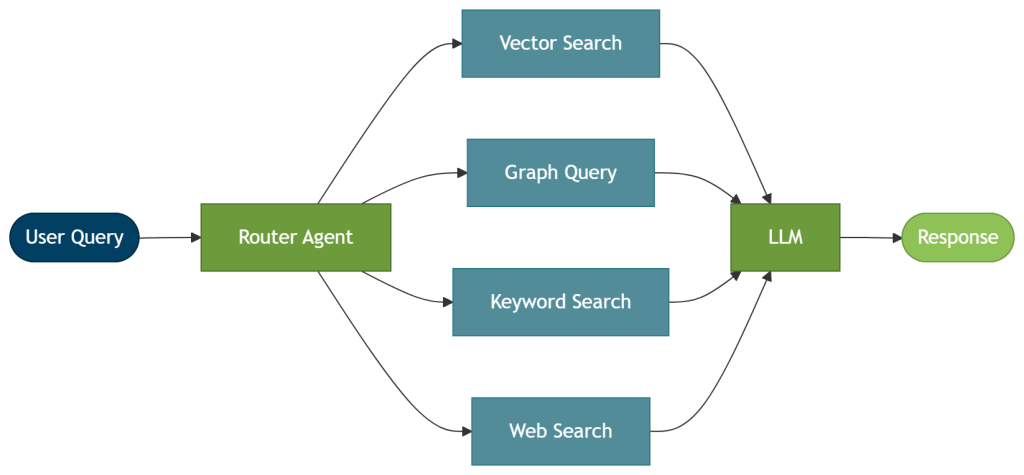
Router RAG
When to use it: Use this router setup when queries vary enough that a single retrieval method won’t serve all of them well. It prevents the system from querying every source for every request.
How it works: A routing step directs each query to the most relevant retrieval method or data source before generation begins — for example, vector RAG for semantic similarity, GraphRAG for connected entity context, or keyword, database, or web search for simpler lookups. The routing decision is typically made by a router agent. For example, Neo4j’s GraphRAG for Python package includes ToolsRetriever, which selects and runs the retrieval tools that match the query.
Corrective RAG
When to use it: Use this corrective setup when your primary index has coverage gaps, and you need a reliable fallback path.
How it works: An evaluation step runs immediately after retrieval. If the retrieved context is relevant, generation proceeds. If it is irrelevant or ambiguous, the agent falls back to an alternative source — typically a web search — before passing context to the LLM. The key difference from ReAct is where correction happens: Corrective RAG switches sources when retrieval falls short, rather than re-querying the same one.

Adaptive RAG
When to use it: Use the adaptive RAG pattern for mixed query traffic (spanning simple lookups to those that require the full agent pipeline) to avoid the full latency and costs of agentic loops for every request.
How it works: Adaptive RAG adds a query complexity classifier before retrieval begins. For example, simple questions – those that can be answered accurately using the model’s internal knowledge – skip the agent loop and head straight to the LLM. Moderate questions — those with a single factual answer — go through a single retrieval pass. Complex questions – where the answer requires multiple steps of reasoning or cross-source evidence – are routed to a full agentic loop with evaluation and re-retrieval.

Multi-agent RAG
When to use it: Use the multi-agent RAG pattern only when a single agent demonstrably can’t handle the scope — for example, when a task spans multiple domains or benefits from parallel retrieval. Splitting the work can improve quality or throughput, but latency, cost, and coordination overhead grow quickly, and failures are harder to trace across agent boundaries.
How it works: A multi-agent setup splits the work across specialized agents. One agent handles planning, while others focus on retrieving context, validating results, or preparing the final response.
A common multi-agent RAG pattern has an orchestrator agent that receives the query and delegates to a planning agent, which then dispatches parallel retrieval agents. A synthesis agent combines the results, a validation agent checks whether the combined context meets quality criteria, and a generation agent produces the final response. If the validation step fails, control returns to the orchestrator rather than terminating the loop.

What are the use cases of agentic RAG?
Here’s how agentic RAG can work in industries where a single retrieval pass consistently falls short.
Enterprise knowledge
Enterprise questions often cut across policies, ticket history, internal documentation, and system data, and conflicts show up quickly. The hard part is knowing which source to trust when they disagree. A policy document says one thing, last month’s all-hands presentation says another, and the internal wiki hasn’t been updated in over a year. A retrieval pipeline returns all of it. An agent resolves the conflict by comparing sources, reasoning, deciding which takes precedence, and explicitly flagging the disagreement when there’s no clear winner.
Finance
Fraud investigation doesn’t follow a deterministic retrieval path. Say a flagged transaction surfaces an unfamiliar counterparty. Before you can judge whether the transaction itself is suspicious, you need to know who’s on the other side, so the next pull is the counterparty’s KYC file rather than more transaction history. If that file ties them to a sanctioned entity, the question shifts from fraud to sanctions, and policy documents move ahead of exposure analysis in the queue. A standard RAG cannot express this chain of reasoning, but an agentic setup can. It can decide what to do next based on what it just found and stop when the evidence is strong enough to support or rule out the case.
Legal
Contract review is a good example of where sequential retrieval and evaluation matter. Finding every agreement with unlimited liability clauses and no matching insurance provisions isn’t a one-pass problem. One retrieval pass returns contracts with similar language. That doesn’t mean it found the right contracts, verified the right clauses, or confirmed both conditions together. An agent works through the problem sequentially: It identifies the relevant contracts, retrieves clause-level content, and verifies the insurance condition. Another agent evaluates the findings and generates a response only when all three checks pass. That same sequential dependency shows up across compliance work, due diligence, and regulatory review.
Healthcare
Clinical decisions are interdependent. You can’t recommend which medications the patient should be on without evaluating the patient’s medical history or drug interactions. Each retrieval step depends on the results of the previous step. A standard RAG often misses the big picture. An agentic RAG first retrieves patient context and uses it to decide what to look up next. In a high-stakes environment like healthcare, the validation loop becomes crucial for catching errors before the agent provides an output.
Customer support
Customer support requires data from different sources, including product docs, account data, order history, and open tickets. But which ones, and in what order, depends on the question. A billing issue needs a different retrieval than a technical one. A router agent routes requests to the appropriate sources without querying every source for every request.
How to implement agentic RAG
Treat agentic RAG as an upgrade to standard RAG. Start with a standard baseline, then add agentic RAG patterns or make incremental optimizations where the current pipeline falls short. Small changes make it easier to evaluate each gain and cut complexity that doesn’t earn its place.
1. Establish a standard RAG baseline
Begin with a straightforward RAG pipeline: a data store, a retriever, and an LLM. Use vector retrieval as your baseline and measure answer quality, latency, and empty-context rate before adding agent loops. Those numbers are what you’ll measure every subsequent change against.
2. Identify the failure mode first
What’s going wrong? Name the specific failure before changing the architecture. Poor routing across sources, missing multi-hop context, weak explainability, and answers that need verification all call for different fixes. Trying to solve them all at once makes each one harder to trace.
3. Introduce agentic patterns where they help
Once you name the failure, consider which pattern can close the gap. Add a review step at the stage that fails most often. The ReAct loop is a common starting point. Define explicit pass/fail criteria upfront (for example, a minimum faithfulness score or a required entity match). If it still doesn’t provide the answers you need, consider adding layers to your agentic loop — such as router, corrective, or adaptive patterns — or specialized agents for jobs that require a heavy workload or consume a lot of context.
4. Set a maximum limit for loop iterations
Put a hard cap on loop iterations as a stop criterion to prevent the system from spiraling into expensive, hard-to-trace retries. This is one of the harder tuning problems in agentic RAG. If you’re too strict, the loop exits before it has enough context; if you’re too loose, it adds cost without improving answers.
5. Optimize context
Once the loop is running, the next lever is context engineering — deciding which facts to retrieve, structure, and pass to the agent at each step. This can improve answer quality more than adding another loop iteration. Three areas matter most:
- Context management: Not everything retrieved deserves to go into the context window. Filter retrieved chunks by relevance score and rerank before passing them to the LLM. Irrelevant or redundant context degrades answer quality even when the right information was retrieved. Most retrieval libraries return relevance scores alongside results; use them.
- Short-term memory: Track what the agent has already retrieved within a session so it doesn’t re-query the same source on the next loop iteration. Store retrieved facts, tool call results, and intermediate conclusions between steps.
- Reasoning memory: Store the agent’s intermediate reasoning, tool calls, and conclusions between loop iterations. When the agent re-enters the loop, it should pick up where it left off rather than start reasoning from scratch. This prevents redundant steps and makes the agent’s path to an answer traceable.
6. Instrument before you scale
Return retrieved context alongside each answer during development so you can inspect exactly what was retrieved for each query. Define a fallback for empty-context cases so the system fails gracefully rather than silently. Trace tool calls, loop depth, retry counts, stop reasons, and stage-level latency. A final answer score tells you whether the system got it right; those traces tell you why it didn’t when it fails.
How to evaluate your agentic RAG system
Agentic RAG needs a broader scorecard than standard RAG because the system can take several paths before reaching an answer. A single end-to-end score tells you if the answer was right. But if the answer is wrong, it won’t tell you where things broke or why.
Start by developing a set of evaluation questions that represent your use case, along with the expected retrieval sources and the expected response for each question. The question set should mirror real usage. Include clean and noisy questions, single-hop and multi-hop tasks, and inputs with typos, vague prompts, and under-specified intent. Production traffic will include all these, so your benchmark should too.
Run these questions through your agent and compare the actual retrieved sources and responses to the expected ones. Use LLM-as-a-judge to score them across a set of key metrics that you care about.
When you make changes to your agent, the evaluation tells you how much it improved or catches when it’s regressing.
Retrieval metrics
Track context precision (what fraction of retrieved chunks were actually relevant) and context recall (what fraction of the needed evidence was retrieved). A high re-retrieval rate, where the agent loops back frequently, usually points to routing logic, chunk size, or query formulation. Answer generation is rarely the bottleneck.
Answer quality metrics
Measure faithfulness (does the answer contradict the retrieved context?), answer relevance (does it address the question?), and hallucination rate. An LLM-as-judge setup works well here: Multiple valid retrieval paths can lead to the same correct answer, and rigid string matching will undercount accuracy. Tools like Ragas provide ready-made metrics you can wire into a test suite with a few lines of Python.
System-level metrics
Track loop depth per query, tool call success rate, stop reasons, and stage-level latency. These tell you whether the system is genuinely improving answers or just spending more tokens to reach the same result. If average loop depth keeps climbing without a corresponding gain in faithfulness, tighten your stopping criteria.
Evaluation tools
Several tools cover different parts of the stack:
- Ragas provides a comprehensive framework for RAG evaluation, including retrieval and answer metrics (faithfulness, context precision, context recall) that map directly to RAG-specific failure modes.
- LangSmith provides request-level tracing and is useful when you need to see which tool was called, what it returned, and why the agent stopped.
- TruLens instruments across retrieved context, tool calls, plans, and broader agent execution, which is useful when you want a single dashboard across the full loop.
Knowledge graphs for agentic GraphRAG
Retrieval sets the ceiling for answer quality. Vector-only RAG can return chunks that look similar while missing the relationship that makes the answer useful. That’s where GraphRAG comes in.
GraphRAG improves retrieval by incorporating structured domain knowledge from a knowledge graph, returning connected context instead of isolated passages. Knowledge graphs preserve relationships between entities, so agents can traverse these connections at query time rather than reconstructing them from flat text chunks. That connected context improves relevance, supports multi-hop reasoning, and makes answers easier to trace back to the source.
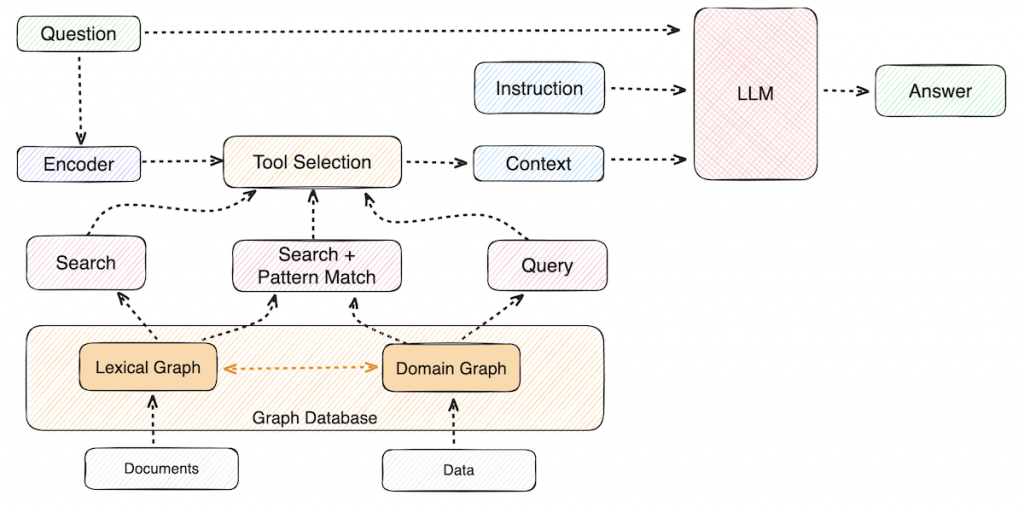
Neo4j provides knowledge graphs to store enterprise-grade AI-ready data. Agents can use a hybrid of GraphRAG and vector RAG to query the knowledge graph, equipping them with a deep, contextual understanding of your data.
Get started with agentic GraphRAG
Agentic RAG adds a reasoning loop over retrieval. When flat retrieval misses something, the agent just loops back to retrieve more information. But it also shifts where failures hide. With a chain of reasoning and actions, the failure becomes harder to identify.
GraphRAG is the fix. A knowledge graph gives the agent context that reflects how entities relate in your domain, making agent reasoning more contextual and traceable.
The Essential GraphRAG guide walks through building that retrieval foundation — from graph data modeling to grounding your agents in connected context.
Essentials of GraphRAG
Pair a knowledge graph with RAG for accurate, explainable AI. Get the authoritative guide from Manning.
Agentic RAG FAQs
Agentic RAG is a form of retrieval-augmented generation where an AI agent controls the retrieval process. Instead of a fixed retrieve-then-generate pipeline, the agent decides when to retrieve, which tools to query, and whether the results are good enough. It iterates until it has sufficient grounded context or reaches a stopping point.
Standard RAG usually retrieves context once and generates an answer. Agentic RAG can create a plan, break a task into multiple steps, choose appropriate tools, reason over the results, re-query when the first pass falls short, and validate the evidence before it answers. Think of the difference as a fixed one-shot workflow versus an adaptive multi-step workflow.
Like standard RAG, agentic RAG starts with a user query, but then the system decides whether it can answer directly or needs to retrieve more information. If it needs more context, it can plan the next step, choose a retriever or tool, inspect the result, and decide whether to stop, revise, or continue. The loop ends when the system has enough grounded evidence to answer or reaches a safe stopping point.
Agentic RAG is worth it when your hardest questions depend on multi-step reasoning, cross-source synthesis, or validation before generation. It’s usually not the best starting point for simple question-answering with a single well-scoped source. A simpler RAG pipeline is often faster, cheaper, and easier to debug. Add agentic behavior when the accuracy gain is worth the extra cost and complexity.
The main benefits are better handling of multi-hop questions, more flexible retrieval across tools and sources, and higher quality answers.
The tradeoffs are higher latency, higher token cost, more moving parts, and a larger failure surface. Planning, routing, reflection, and orchestration can improve accuracy, but they also make the system harder to evaluate and maintain.
Start with a standard RAG baseline first. Then identify the exact failure modes you need to fix, such as weak routing, missing multi-hop context, or poor answer validation. From there, add agentic RAG patterns to solve these failures. You might introduce a routing step, add a corrective loop around the step that fails most often, or move from vector RAG to GraphRAG. Instrument the system early so you can measure retrieval quality, answer quality, loop depth, tool use, and latency before you scale.
Share Article



Explore
Related Articles
Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

1 of 3: The difference between a graph, a knowledge graph, and a context graph

2 of 3: Why graphs, knowledge graphs, and context graphs matter to customers

3 of 3: The graph ecosystem: Bringing connected context to enterprise AI

Digital twins that learn: connected asset intelligence with Neo4j and Databricks
