







Introducing Neo4j Virtual Graph: Graph reasoning on the data you already have


9 min read
Over the past few quarters, we’ve seen tremendous growth in enterprise adoption of agentic workflows. Large enterprises are realizing that GraphRAG delivers more accurate results than traditional RAG, multi-hop reasoning is essential for many high-value use cases, and memory and context graphs are critical for accurate decision-making. However, enterprises want a zero-copy architecture; they do not want to move or duplicate data from their data warehouses, lakehouses, and operational databases into Neo4j just to unlock the benefits of graph intelligence. Today, we are unlocking the power of graph intelligence on all your enterprise data.
We are announcing Neo4j Virtual Graph, available now in private preview. Virtual Graph lets you run Cypher queries and graph algorithms directly against the data you already have in Snowflake, Databricks, and other databases and lakehouses. Our zero-copy architecture means your data stays where it is, governed by your existing controls, while you still get the power of Neo4j’s AI-powered Graph Tools. No new system of record to manage.
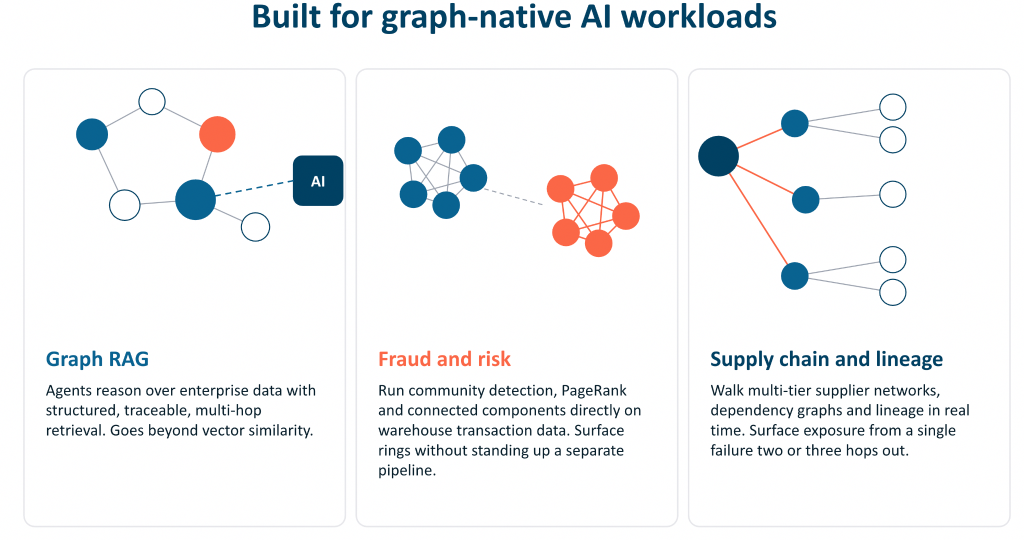
Virtual Graph surfaces the relationships your tables have always implied but never exposed, ready for graph queries, graph algorithms, and the AI agents that need to reason over them.
Why Virtual Graph?
Every team building with AI hits the same wall. Language models are powerful reasoners, but the data systems they access were never built to serve connected data in graph form. When an agent needs to answer “show me every customer downstream of this supplier disruption” or “which accounts share a beneficial owner three hops out,” a flat table query and a vector search are not enough. The agent needs a graph.
We have heard the same questions from data and AI teams everywhere:
- How do I bring graph reasoning to data that already lives in my warehouse, alongside the graphs I already run in Neo4j?
- How do I apply Neo4j’s AI-powered Graph Tools to datasets that are too large, too governed, or too operational to move?
- How do I test the value of GraphRAG on my warehouse data without standing up an ETL pipeline?
- How do I keep a single source of truth in my lakehouse and still get graph reasoning over it?
- For batch and analytical agentic workloads where seconds-to-minutes latency is fine, how do I avoid building a parallel graph stack?
Virtual Graph is built to answer all five.
Meet Virtual Graph
Imagine pointing a graph database at your existing warehouse and getting started in minutes, with no data movement, no schema rewrites, and no new pipelines to maintain. That is Virtual Graph.
It runs natively in Neo4j Aura, behind the same surface you already use for AuraDB. You connect to your data source, let it automatically generate a graph data model from your tables, and start querying. Behind the scenes, your Cypher query is compiled and executed against your data in place, so the heavy lifting happens on the compute you already pay for, in the system that already governs the data. You get the expressive power of a graph and the scale of your lakehouse, without choosing between them.
Here is what that looks like in practice.
1. Cypher and graph algorithms directly on your warehouse data
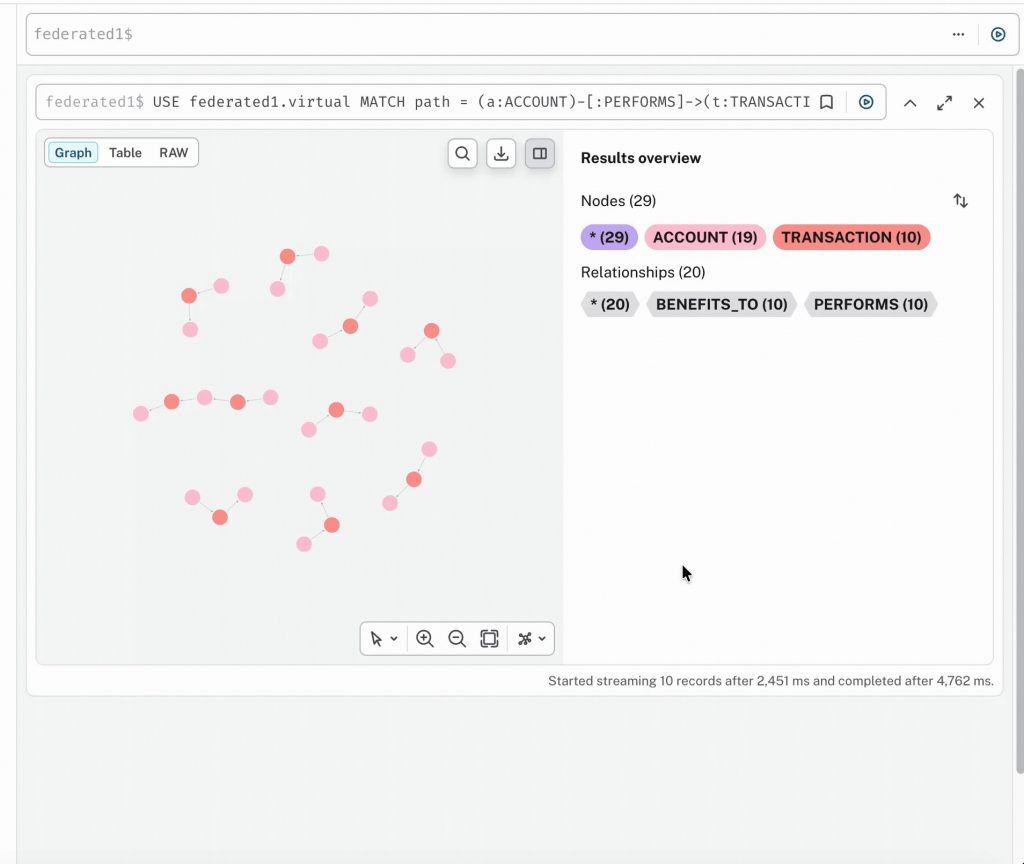
Connect Virtual Graph to a Snowflake or Databricks workspace, and within minutes, you have a working virtual graph over tables you already trust. No copy job, no overnight load, no pipeline to maintain. Run Cypher patterns, graph traversals, and pathfinding directly against the latest version of your data.
For example:
“Find circular payments within my transaction data and return the path that connects them.”
The Cypher you write is compiled into the SQL your warehouse already understands, the work runs in place, and the answer comes back as a graph result. No data has moved. Because the compilation is deterministic and not LLM-driven, you get the same SQL every time, with predictable performance and cost.
2. AI-generated data model from your existing tables
Modeling a graph used to be a workshop. Now it takes just a click. Point Virtual Graph at your tables and the built-in AI proposes a graph model: which entities should become nodes, which foreign keys should become relationships (and it infers relationships in warehouses that don’t even declare foreign keys), and which columns become properties. You review, you adjust if you want, and you ship.
Try it with something like:
“Generate a graph model from the customers, transactions , and accounts tables in my banking schema.”
Virtual Graph inspects the existing schema, infers the entities and relationships, and presents a model you can edit visually before you commit.
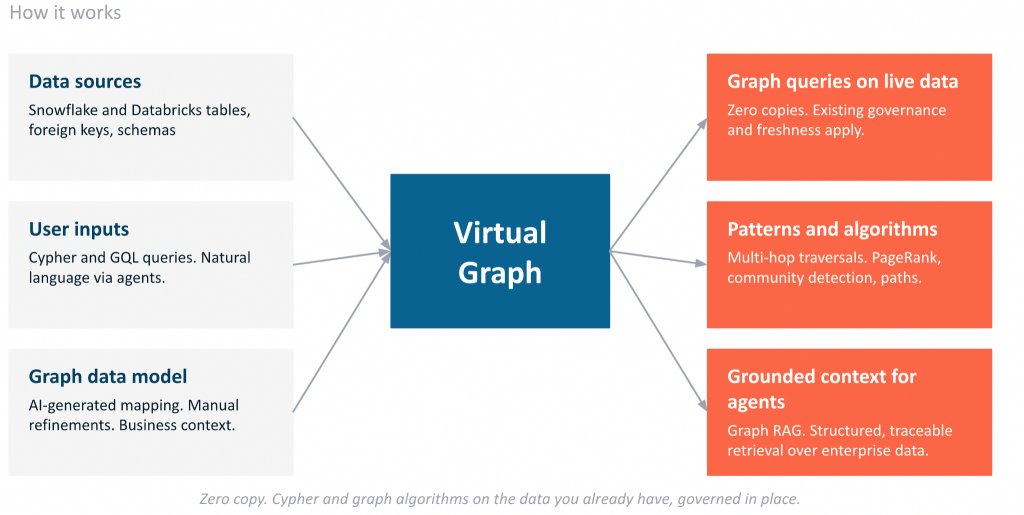
How it works
Virtual Graph sits between your applications and your existing data, with three pieces working together.
- The data model is generated automatically by AI from your source schema and stored on the engine instance. You own it, you can edit it, and it stays in sync with your tables.
- The query translator compiles Cypher patterns into optimized SQL and pushes the work down to your warehouse engine. Your data never leaves your governance perimeter.
- The graph compute layer handles graph-specific operations like pattern matching, traversals, and algorithms that SQL alone cannot express efficiently.
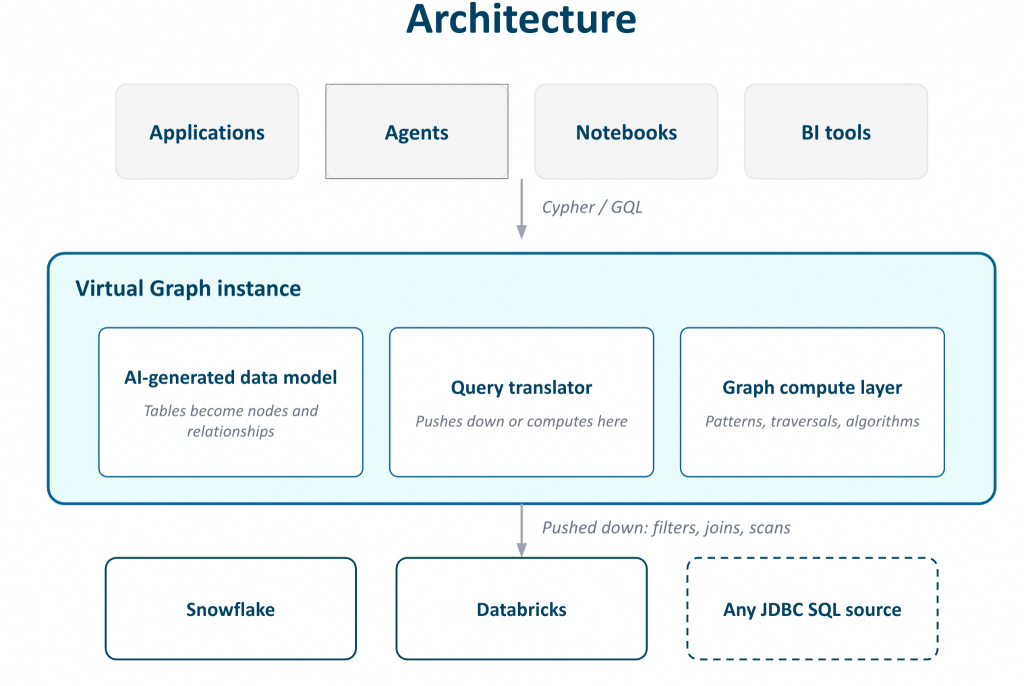
The result is that you get graph reasoning at the same place where your relational analytics already runs, with your existing security, governance, and data freshness.
When should I use Virtual Graph vs a Neo4j-stored graph?
Virtual Graph and a graph stored in Neo4j are not substitutes. They solve different problems, and the most graph-mature enterprises will use both.
What warehouses are good at. Snowflake, Databricks, and similar engines are built for aggregations over very large datasets, batch processing, and analytical workloads where data freshness matters more than millisecond latency. They are extraordinary at columnar scans, joins across large fact tables, and at serving the analytical layer of the business. They are not built for hot, latency-sensitive traversal.
What Neo4j-stored graphs are good at. A graph stored natively in Neo4j is built for low-latency, high-throughput traversal. Deep multi-hop patterns, pathfinding over a hot working set, real-time pattern matching, ACID writes, and the always-on graph workloads that an agent calls thousands of times an hour. Native storage also unlocks the full surface of Neo4j Graph Tools, including AI-powered modeling, semantic search, and the production-grade operational tooling our customers have built knowledge graphs on for years.
Where Virtual Graph fits. Reach for Virtual Graph when:
- You want graph reasoning on data that already lives in your warehouse, without standing up a parallel pipeline.
- Your workload tolerates warehouse-grade latency: GraphRAG over reference data, batch enrichment, analyst-driven exploration, agentic workflows where seconds-to-minutes is acceptable.
- You want to test the value of graph patterns over existing data before deciding what to graph natively.
- Governance, scale, or politics require the data to stay where it is.
Where a Neo4j-stored graph fits. Reach for AuraDB or self-managed Neo4j when:
- The workload needs millisecond traversal latency: real-time agentic decisioning, online fraud scoring, in-session recommendations, live identity resolution.
- The graph is updated continuously and writes need ACID guarantees.
- The data is naturally graph-shaped from origin: knowledge graphs built from unstructured documents, customer 360 with high relationship density, supply chains, memory graphs for agents.
- You want the full Cypher, graph algorithm, and AI-powered Graph Tools surface in one place.
A common pattern. Many of our customers run both. Reference data in the warehouse (transactions, accounts, product catalogs) is reached through Virtual Graph. Operational graphs (knowledge graphs, memory graphs, real-time customer graphs) live in AuraDB where latency matters. When composite queries land in Aura, you will be able to span both in a single statement.
The simplest rule: if you describe the workload as agents that need to think in seconds, Virtual Graph is a fit. If you describe it as agents that need to act in milliseconds, you want the graph stored natively.
What’s next: from virtualization to acceleration
Virtual Graph launches today as a virtualization layer. That is intentional. We want every team to be able to try graphs on their existing data with zero commitment and zero migration. But we are not stopping there.
Here is what is on the roadmap:
- More sources. Any system with a JDBC or SQL interface is in scope. Wherever your data lives, you can put a graph over it.
- Adaptive caching. A capability that materializes hot subgraphs to deliver dramatically lower latency for repeated agent workloads, and you cut the external compute spend that comes from running the same traversal a thousand times. This is where Virtual Graph moves from cost-neutral to cost-saving.
- Composite queries across Aura and Virtual Graph. Write a single Cypher statement that spans, say, a knowledge graph in AuraDB and an order history virtual graph over Snowflake. Available today on self-managed Neo4j, coming to Aura.
- Deeper agent integration. Native graph-RAG primitives, semantic layer hooks, and tool definitions designed for the way agents actually call graphs through the Neo4j Graph Tools surface.Cypher and GQL parity. Full coverage so the queries you already write for AuraDB work unchanged on Virtual Graph.
The knowledge layer for the agentic enterprise
Agents are only as good as the context they can reason over. For workloads that demand real-time decisions, native Neo4j storage remains the right home for your most valuable graph data, with AI-powered Graph Tools, full Cypher, and the performance our customers have built production graph systems on for years. For the rest of your enterprise data, the data sitting in warehouses and lakehouses with relationships your queries could never reach, Virtual Graph opens it up to graph reasoning with zero copies and zero new systems of record.
Use both. That is how the most graph-mature enterprises will build.
We cannot wait to see what you build.
Ready to get started?
Neo4j Virtual Graph is available now in private preview. Snowflake and Databricks are supported at launch, with more sources arriving over the coming quarters.
- Join the preview: Tell us about your use case here, and our team will be in touch.
- Watch the demo: A three-minute walkthrough of connecting, modeling, and querying a virtual graph over a Snowflake workspace.
Share Article



Explore
Related Articles
