
Achieve Unrivaled Speed and Scalability With Neo4j

Senior Director of Product Marketing
10 min read

As data volumes continue to grow, applications need to scale up and scale out to handle the increased load. Both approaches have their advantages and disadvantages, and the best approach varies on the specific requirements of the application. However, data integrity and performance must be maintained across all architectures – whether on-premises, hybrid, or cloud-based. With the right approach, data can be managed effectively at scale, providing the foundation for performant applications.
There are challenges that every organization must overcome to attain seamless performance and scale for their applications. Let’s look at a few.
- With expanding datasets – and organizations pushing the boundaries of analytics implementations – the complexity of queries has risen exponentially.
- The agility needed to adapt applications to support modified analytics and queries, new data sets, and scheme changes results in significant change management and heavy lifting.
- The advancements and deployment of AI/ML pipelines – and the flexibility of the data sources that feed them – require a more readily adaptable schema model.
In this blog, we will explore how to reframe the complexity of scalability in a more useful way and look at sources and patterns to demonstrate how it manifests in graphs. Whether it is data volume, read throughput, or write throughput, a graph database like Neo4j can help organizations query data in real-time, at any scale. This approach provides the flexibility and speed needed to make complex decisions quickly.
Scalability is all about managing complexity.
There are three axes that are usually employed with database scalability. The first is data volume, meaning the database system should be able to handle increasing amounts of data without hindering performance. The second axis is read throughput, and the third axis is write throughput. These three axes are not entirely independent and are often combined in database scaling technologies like sharding, where data is split into pieces and spread around multiple machines, dealing with both increasing data volume and hardware utilization.
Read scaling is significantly easier for graphs than scaling writes. The most efficient way to support large numbers of read requests is to replicate servers that store the graph.
When it comes to scaling graph writes you can simply scale up the hardware, choose to distribute parts of the graph across many servers, or opt for cloud deployment to increase write performance.
In-memory graphs significantly outperform those that are not cached, providing faster and more consistent query response times for reads and writes across the entire graph. Offering the best experience for your application may not require all of the graphs to be loaded into memory if variable response times are acceptable, with the fastest response times for the frequently accessed parts of the graph. Neo4j can pre-warm caches, and optimize loading the graph into memory after restarts.
Some graph vendors answer all scalability questions with horizontal, scale-out, or cloud approaches, but few offer vertical scaling options as well. This lack of agility and flexibility leads quickly to costly application deployments.

Neo4j’s clustered architecture provides flexible horizontal and vertical scaling solutions and in-memory graph caching to simplify scaling and performance challenges. Neo4j also offers cloud-based DBaaS that free you from solving those thorny problems on your own. This agile approach enables you to balance performance, cost, and complexity tradeoffs to address the unique requirements of each system development project.
Data volume and horizontal scalability are two obvious aspects of scalability, but what others can we identify and, more importantly, can we find a unifying theme across them?
Josh Marcus, Chief Technology Officer, albelli, said, “At albelli, we regularly deal with petabytes of data, and we are most excited about the new scalability features in Neo4j 4.0. The ability to horizontally scale with the new sharding and federation features, alongside Neo4j’s optimal scale-up architecture, will enable us to grow our graph database without barriers.”
Learn more about the albelli use case here.
If we start thinking about application development and how it’s evolved over time, we start seeing more scalability concerns. One is the sophistication of the queries made against the system. As an application grows, the use cases become more and more complicated. New features are added, the user experience becomes richer, more sophisticated connections between existing pieces of data are required, and overall the queries from the application increase in size, complexity, amount of data they access, and their coverage of the overall database schema.
In this case, scalability takes the form of the system being able to manage increasingly sophisticated queries with the same ease as simpler ones, without performance suffering or putting an undue burden on the query author.
Qualicorp Administradora De Beneficio CIO, Ricardo Antonio Batista said, “Our application and system is responsible for managing a complex ecosystem of all the processes related to more than 2.6M customers, 32K corporate agreements, and over 100K different health insurance options offered by 100 different insurance companies. Well, you can imagine the complexity of data relationships with that requirement and how to operate at scale. In order to provide the best service, Qualicorp needed a cost-effective, highly available, and scalable system to manage millions of relationships in real-time to gain valuable insights within the complex data ecosystem, and we chose Neo4j Aura – A fully-managed cloud service running on Google Cloud Platform (GCP) for building our systems.”
Learn more about the Qualicorp use case here.
Since query complexity is an application concern, we must also recognize a corresponding effect on the database side – schema complexity. As the sources we draw data from get more numerous and complicated, the entities we store in the database become more complex, too. New types get added, entities get new properties, and even indexing structures need to be revisited. The result is that for a given query, the result set gets not only bigger but has more conditions to deal with. Even security concerns evolve over time, because as your operations get more complex, more users and roles need to keep things under control.
Neo4j’s Chief Architect, Chris Gioran, said, “Extraction of knowledge from data is no longer an optional process. It needs to permeate every aspect of an organization, from the moment data arrives and throughout its lifecycle. At the frontline of this transformation are developers, and they expect the tools they use to be scalable from the smallest transaction to the largest analytics job. Neo4j delivers exactly this type of flexibility across the entire spectrum of data operations and with Neo4j as the backend, applications can provide insights in real-time, truly at scale, and with continuous global availability. Not only this, Neo4j’s schema-less data model provides an extremely valuable concept-first approach when working on building and evolving a data model for changing business requirements, enabling developer velocity.”
Neo4j’s unbounded architecture provides blazing-fast graphs, with superior scaling.
Neo4j’s high-performance distributed cluster architecture scales with your data and your business needs in real-world situations, minimizing cost and hardware while maximizing performance across connected datasets. With Neo4j, you can now achieve robust transactional guarantees, performance across billions of nodes, and trillions of relationships with the millisecond response time.
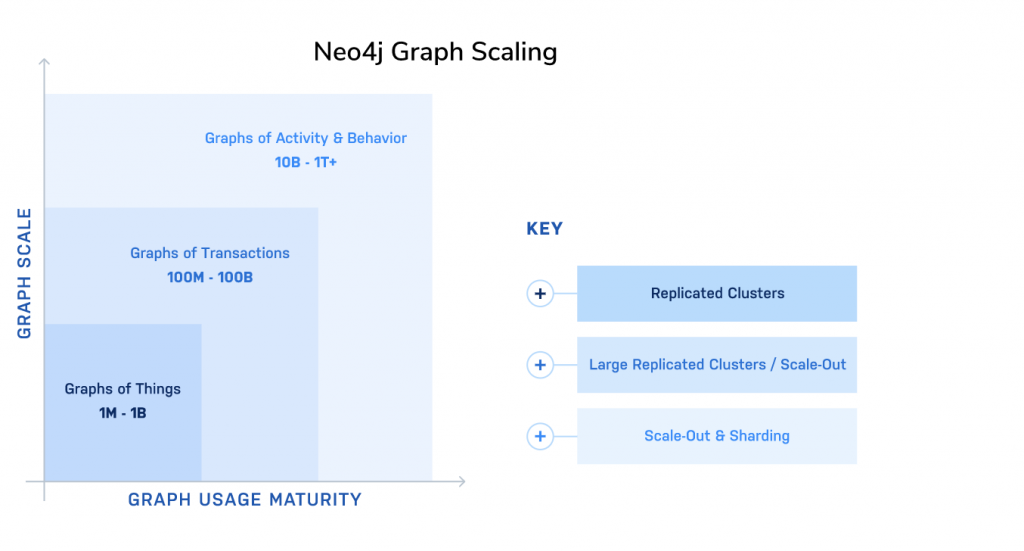
Neo4j’s distributed architecture offers:
- Continuous Availability for OLTP
- Faster failover times
- Guaranteed commit throughout the cluster when there is a majority (consensus commits)
- Core servers dedicated for write operations, and dedicated Read Replicas
- Global Availability
- Geo distributed multi-datacenter deployments
- Large scale hybrid clusters
- Virtually unlimited scale-out for read and write-intensive workloads using Neo4j Fabric
- Fabric provides sharding and federated capabilities both in local and geo-distributed environments.
- A unified view of local and distributed data, accessible via a single client connection and user session
- Increased scalability for read/write operations, data volume, and concurrency
- Predictable response time for queries executed during normal operations, a failover, or other infrastructure changes
- High availability and no single point of failure for large data volume
- Sharding: Operate over a single large graph
- Federation: Query across disjointed graphs
- Isolate data for compliance regulations like GDPR
- Minimize latency of queries in various regions by storing segments closer to users
- Break up very large graphs (tens of billions of nodes) into smaller graphs, so that you can run on smaller-sized hardware while maintaining the performance users want
- Takes milliseconds to execute queries that require minutes or hours on other graph platforms
- Adapts to evolving business models and datasets rapidly and without interruption
- Scales to meet requirements of the largest and most complex enterprise applications
- Often requires 10x less hardware than other databases
- Maximizes developer productivity with 10x less code than SQL
- Taps into the world’s largest community of skilled graph developers
- Is already chosen by an overwhelming majority of global enterprises and industry leaders
Learn more here.
Zack Gow (CTO, Orita) said, “Scale is always top of mind for us because we’re processing data that comes from our customers. We never know just how big a customer’s data set will be and we chose Neo4j because we knew it could handle the scaling of an order of magnitude more than what we were expecting.”
Graph Data Science and Analytic Read Scaling
Neo4j Graph Data Science includes powerful graph analytics, the world’s most extensive library of graph algorithms, and the only in-graph ML workflows. Graph Data Science integrates easily into enterprise data stacks and pipelines and is coupled with a production database. As a result, Graph Data Science enables high-performance graph algorithms and machine learning models at an unmatched scale that support graphs up to hundreds of billions of nodes and relationships. Graph Data Science offers robust graph algorithms that can run on terabytes of data in minutes.
Pritesh Tiwari (Director of Data Science, VYugma, and Founder of DSW) said, “One of the most time consuming and integral stages of any data science project is data exploration – which not only helps to identify the important features for model building but also helps to find the hidden pattern in the data – but this entire process is very cumbersome and there’s no one defined methodology to get the desired results. This is where Neo4j can be leveraged to identify the correlations between the data beforehand which is helping to reduce the turnaround time while building effective and explainable AI models.”
Sharding Graph Data With Neo4j Fabric
Fabric provides unlimited scalability by simplifying the data model to reduce complexity. With Fabric, you can execute queries in parallel on multiple databases, combining or aggregating results. It also allows you to chain queries together from multiple databases for sophisticated, real-time analysis. Broadly, Fabric helps you achieve a number of benefits, such as:

There are two modes of operations in Fabric:
Sharding
Neo4j enables organizations to slice their large-scale graph datasets into separate, smaller, and faster chunks (shards) and store them using our distributed sharding architecture across multiple systems. Though physical storage of a graph dataset is sharded across many servers or clusters, speed, consistency, and data integrity are maintained. Shard a graph to:

Federation
While sharding divides graphs, federation enables queries across disjointed graphs by bringing multiple graphs together. Imagine having graphs across your organization, from IT to finances, operations, sales, HR, marketing, manufacturing, and more. Neo4j leverages the power of Cypher, allowing developers to query across these graphs – even ones with different schemas – as if it was one large graph.
The result: All data stored across an enterprise’s graph database ecosystem are now searchable with a single Cypher query – an entirely new and powerful capability for the graph database world.

Wish to learn more about what our customers have to say on scaling analytics with Neo4j? Tune into Neo4j Connections – Graphs for Real-Time Analytics at Scale recordings here. For more information, check out our case studies here.

Part of the Adobe family, Behance, the leading online platform to showcase and discover creative work, has over 30 million members. It provides a platform where web, graphic, and fashion designers, illustrators, and photographers showcase their work – and the Adobe software used to create it – to millions of monthly visitors. It is also a top online destination for companies looking to hire creative talent on a global scale.
David Fox, Senior Software Engineer at Adobe, said, “At the core of Behance’s business success is its Activity Feed. This de facto homescreen sends out millions of alerts and updates daily, enabling site members to share new work and projects, collaborate, and communicate. Behance introduced the activity feed in 2011, but as it scaled, it began to experience performance problems with slow reads. In 2015, Behance solved the reads issue using a “fan-out” strategy, which enabled Behance to automatically populate every user feed with new activity items. This approach became problematic as Behance’s data and user volumes continued to grow. In particular, due to the read-optimized data model, resource utilization skyrocketed every time those users followed by thousands of people took an action.
“Our infrastructure strategy became more problematic as our app grew and we added more users and more data. Neo4j helped to fix the problem. Behance now powers its entire Activity Feed infrastructure with just three Neo4j instances. Human maintenance hours are down, updates that used to take 12 – 30 minutes now run in 100 milliseconds. Additionally, Neo4j has cut users’ average time from sign-up to initial activity from 1.4 seconds to 400 milliseconds. We’ve seen significant performance improvements, and a great reduction in complexity, storage, and infrastructure costs. Staff now focus on improving the infrastructure, versus spending time frustratingly micro-managing it.”
Summary
By selecting Neo4j, you standardize on an enterprise graph solution that:
Resources
The Total Economic Impact™ of the Neo4j Graph Data Platform
Neo4j Scalability
Share Article



Explore
Related Articles

What Are the Different Types of Graph Algorithms & When to Use Them?


Neo4j Expands AWS Collaboration With New Competencies in Finance, Automotive, GenAI, and ML

GenAI Graph Gathering 2.0: The Evolution of GraphRAG

