

Useful AI Agent Case Studies: What Actually Works in Production

Field CTO, Neo4j
10 min read

AI agents go beyond “ask a model, get text back.” They pursue goals over time: planning steps, retrieving information, calling tools, observing results, and adapting as new context appears. That execution loop is what separates agents from generative AI and chatbots.
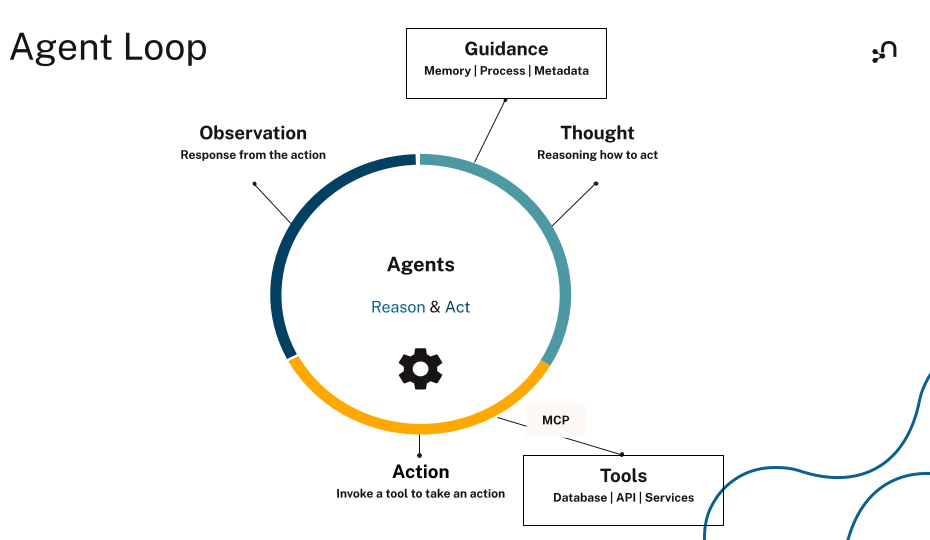
An agent operates in the real world, coordinating across systems, maintaining state across multiple steps, and making decisions under uncertainty. This is also where many agents break down. In production environments, agents hallucinate when context is missing, lose track of state in long workflows, misuse tools, or get stuck in unproductive loops. The issue is rarely the model itself — it’s whether the agent has access to the right context at the right time.
In this article, we examine real-world AI agent case studies, including what problems these agents were built to solve, how they were designed, how context was engineered, and what teams learned as they moved from promising demos to useful AI agents in production.
What Makes an AI Agent Useful (and Why Many Fail)
AI agents are not general-purpose solutions. They create value in specific use cases, industries, or domains, but tend to break down when applied outside those bounds. Understanding where agents work — and where they fail — is essential if you want systems that hold up in production.
Where AI Agents Create Value
Agents are most effective when work unfolds over time, each step depends on what happened before, and tool use is necessary. These are problems where a single prompt-response interaction isn’t enough because state, dependencies, and constraints matter.
Agents tend to perform well when they need to:
- Follow a nonlinear path toward a goal rather than a fixed path
- Retrieve and reconcile information from sources and memory dynamically
- Interact with external systems through tools
- Adjust and adapt as new information becomes available during execution
In these scenarios, the flexibility of agents provides more value than a simple chatbot or a fixed workflow.
Why Many Agents Fail in Production
When agents fail, it’s usually not because the model is incapable — it’s because the agent is operating without enough structure in how context, state, and tools are organized.
Common failure patterns include:
- Hallucinations when domain knowledge is incomplete or outdated
- Lost state in long-running or evolving workflows
- Brittle prompts that break under real-world variability
- Tool misuse, such as calling the wrong tool, passing incorrect parameters, or ignoring results
In each case, the agent isn’t reasoning incorrectly — it’s reasoning with insufficient or poorly organized context.
Why Structured Context Changes the Outcome
Reliability improves when you engineer context deliberately. Structured context enables agents to retrieve the right entities and relationships, maintain memory across long workflows, and operate within explicit constraints. It also makes agent behavior traceable, which is critical for governance, debugging, and trust.
This is where GraphRAG becomes crucial for agentic systems. Vector RAG finds similar text, but GraphRAG reasons across connected concepts, dependencies, and constraints. When context is modeled as a knowledge graph, agents can traverse its structure rather than rely solely on similarity. They can reason across multiple steps and make decisions grounded in how the domain actually works.
The case studies that follow illustrate how teams applied these principles in practice, designing agentic systems with the context, constraints, and execution models needed to succeed in real-world environments.

Knowledge Graph Fundamentals
Stop missing hidden patterns in your connected data. Learn graph data modeling, querying techniques, and proven use cases to build more resilient and intelligent applications.
Real-World AI Agent Case Studies
AI agents often look impressive in demos, but their real value emerges when deployed against messy, constrained, real-world systems. The case studies below are meant to be read with a consistent lens: the problem the agent was built to solve, how context was structured, and what that design enabled in practice.
Metadata to Knowledge Conversion Agent
Quollio Technologies
Large enterprises rarely struggle to access data. The harder problem is understanding how fragmented data assets relate to one another across systems, teams, and regulatory requirements. Quollio Technologies addressed this challenge by building AI agents designed to answer questions about enterprise data lineage, ownership, and compliance using metadata rather than raw records.
Instead of exposing sensitive datasets, Quollio’s agents operate over a Neo4j knowledge graph that models enterprise metadata as a connected semantic layer. Business users can ask governance and compliance questions while the agent navigates relationships and dependencies across systems rather than accessing underlying data. This approach reduces the effort required to answer lineage and compliance questions, improves traceability across data estates, and enables insight without expanding access to sensitive information.
AI Voice Agent for Real-Time Conversations
Simply AI
Voice agents operate under tight constraints: low latency, high accuracy, and uninterrupted conversational flow. Simply AI encountered these constraints when building voice agents for customer-facing calls, where relying on static prompts or naive RAG led to inconsistent answers and degraded trust.
Simply AI addressed this issue by building voice agents that retrieve factual information dynamically at runtime using a Neo4j knowledge graph as the grounding layer. Instead of embedding large amounts of information directly into prompts, the agents retrieve only the relevant context needed for each conversation turn.
Customer documents such as menus, policies, and operational content are ingested into Neo4j through an AWS pipeline. While documents are chunked and vectorized, their structure and relationships are preserved to support multi-tenant environments.
During live calls, agents use GraphRAG to retrieve connected context, relevant nodes, and their immediate relationships, providing enough information to respond accurately without increasing latency. This approach improves response consistency, reduces hallucinations, and makes voice agents viable in real-time environments where accuracy and trust are critical.
Air Traffic Control Training Agent
Floorboard AI
Training pilots to communicate effectively with air traffic control requires simulations that behave like real airport operations. Generic language models struggle with physical layouts, procedural constraints, and changing environmental conditions, making them unsuitable for serious pilot training.
Floorboard AI overcame this challenge by building an agent that reasons over an explicit graph model of airport layouts rather than relying on free-form text generation. Airports are modeled as knowledge graphs in Neo4j with nodes and relationships representing terminals, taxiways, runways, and endpoints, allowing the agent to compute exact taxi routes.
The agent integrates external tools that provide real-time weather data and determine active runways based on wind conditions. Its execution loop retrieves current conditions, selects the appropriate runway, queries the airport graph, and responds using standard air traffic control phrasing. This design enables a training agent that follows real airport layouts, procedures, and conditions consistently, allowing pilots to practice realistic air traffic control interactions across repeatable scenarios.
Digital Twin Agentic Platform
Syntes AI
Syntes AI set out to build agents that work directly with dynamic data in live enterprise systems rather than relying on static data extracts or reports. Traditional analytics and LLM-based interfaces struggled to explain how operational data related across systems or to support governed action.
Syntes built a digital twin platform where operational data is modeled as a knowledge graph of enterprise systems. Data from sources such as Snowflake and Shopify is ingested into Neo4j using ELT-based connectors, preserving relationships, lineage, and operational structure.
Agents translate natural language requests into Cypher queries that operate over this live graph. Results are validated and normalized before being returned, and governance is enforced through tenant isolation, detailed logging, and human approvals for sensitive actions. This architecture allows agents to explain their reasoning, operate within defined constraints, and interact safely with live enterprise data, making explainability and control built-in rather than retrofitted.
Conversational Career Recommendation Agent
Walmart Global Tech
At Walmart’s scale, conversational career recommendation systems must balance intelligence with responsiveness. Applying full agentic reasoning to every request introduced unnecessary latency, while simpler approaches struggled with more complex queries.
Walmart Global Tech built AdaptJobRec to apply agentic reasoning selectively. Incoming queries are first classified by complexity. Simple requests are routed directly to tools, while more complex queries trigger task decomposition and memory-based reasoning.
Career recommendations are powered by a large-scale knowledge graph modeling roles, skills, and career pathways. By limiting agentic reasoning to cases where it adds value, this approach reduced response latency by up to 53.3 percent while improving recommendation quality. The result demonstrates that effective agent systems often require orchestration and restraint, not maximum autonomy.
Production-Ready Agents With Long-Term Memory
Mem0
As agents operate over longer interactions, short-term context windows become a limiting factor. Replaying entire conversation histories increases cost and latency while failing to preserve what actually matters.
Mem0 addresses this by providing a selective memory layer that extracts and stores salient facts from interactions as structured updates. At runtime, agents retrieve only the memories relevant to the current task instead of reprocessing full histories.
For domains where relationships matter, Mem0 extends this approach with knowledge graph-based memory that supports multi-hop and temporal reasoning. This reduces token usage, improves consistency across long-running workflows, and makes agent behavior more predictable by separating reasoning context from long-term memory.
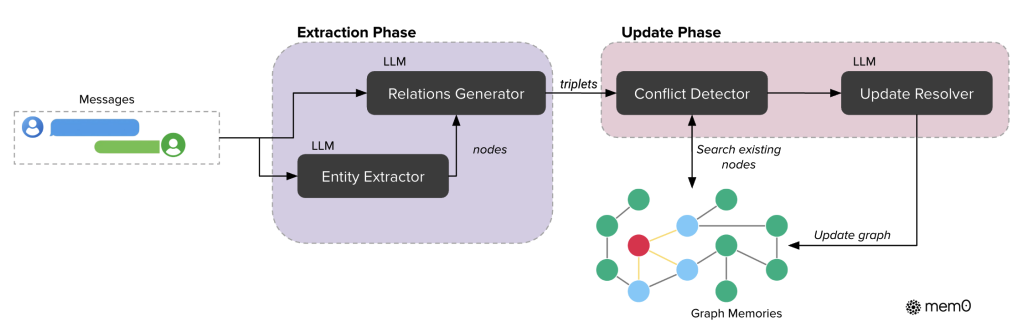
Technical Debt Detection Agent for Vibe Coding
Technical debt is difficult to identify by reading code in isolation. Kambui Nurse took a different approach: modeling entire codebases as knowledge graphs and allowing agents to reason over structural relationships.
Within a Dagger-powered CI/CD pipeline, Neo4j runs as an ephemeral service. Source code is parsed using Tree-sitter and ingested as a code graph. Deterministic Cypher queries identify code smells and structural issues without relying on LLM inference.
Agents can then query the graph, generate tests, or expose insights through MCP endpoints. This approach improves reliability by grounding analysis in structure rather than interpretation, and it generalizes beyond software engineering to any domain where systems can be modeled as connected graphs.
What Successful AI Agent Case Studies Have in Common
Across domains, these case studies converge on a simple truth: Agent reliability depends on the context quality.
What distinguishes the successful agents in the examples above isn’t autonomy for its own sake but deliberate system design. In practice, these teams shared several architectural patterns:
- Context was modeled explicitly, often as a structured knowledge graph that reflects how the domain actually works rather than as disconnected text chunks.
- GraphRAG was used for retrieval, allowing agents to traverse relationships and assemble the specific context needed for each step.
- Execution loops were explicit and constrained, reducing the risk of unbounded behavior or tool misuse.
- Tools were designed with clear responsibilities, so agents knew when and how to act rather than improvising actions.
- Governance and explainability were built in, with decision paths that could be traced back to underlying data and relationships.
Across these systems, reliability emerged from architecture. Knowledge graphs served as a stable context layer, enabling reasoning, memory, and control. Explainability and governance naturally followed from this design.
From Prototype to Production-Ready AI Agents
Most AI agents start as promising demos. What separates those demos from production-ready systems is the architecture. Teams that succeed narrow the problem they’re solving, model domain context explicitly, and design retrieval so agents access only the information they need at each step.
In practice, this means modeling domain context as a knowledge graph, using GraphRAG to retrieve connected context at runtime, and designing tools and execution loops with clear constraints. Successful teams define guardrails early, compare agent-driven workflows against baseline systems, and iterate on context quality and system behavior rather than endlessly tuning prompts.
Neo4j offers production-grade knowledge graphs for agent context. Graph-based reasoning, memory, and tool use help teams move from experimental agents to systems that can operate reliably at scale.
Essential GraphRAG
Unlock the full potential of RAG with knowledge graphs. Get the definitive guide from Manning, free for a limited time.

Share Article



Explore
Related Articles

Graph-Driven AI for All: Neo4j Aura Agent Enters General Availability


Agentic AI vs. Generative AI: Why Agents Need Memory, Context, and Guardrails
Empowering Microsoft Agent Framework with Neo4j Knowledge Graphs
