
Building the Enterprise Knowledge Graph

Solutions Engineer, Neo4j
11 min read
Retainment and reuse of institutional expertise is the holy grail of knowledge management.
Over the years, enterprises have leveraged many generations of knowledge management products in order to retain and reuse knowledge across the enterprise, prevent re-inventing the wheel and improve productivity.
Why Build an Enterprise Knowledge Graph
Enterprise knowledge graph, coupled with AI/ML-based predictive capabilities, is the future of knowledge management technology.
This is a vast improvement over current knowledge management implementations. Graph technology helps connect discrete pieces of information together with the right context, providing extremely fast and flexible querying capabilities.
Coupling graphs with AI/ML-based recommendations or predictive capabilities ensures searches not only bring back specific information but also provide a rich set of highly relevant alternate suggestions and answers to complex questions in real time.
The Hidden Wealth of Data Collected by Enterprise Apps
Modern businesses use tons of different apps to streamline their operations and capture enterprise data. These probably include Google Drive, Slack, Salesforce and Zendesk, to name just a few.
We all know how helpful these are in boosting our day-to-day productivity, but you might not have considered the data as a treasure trove representing your enterprise.
For example, document metadata pulled from Google Drive and ingested into Neo4j can tell you what document topics are currently popular, which projects are getting lots of attention and who the Google Drive super users (i.e. people who review/edit lots of documents) of your organization are. The possibilities here are endless, and the power of your analysis is limited only by the amount/quality of your data.
Additional business insights include similarity of documents, identification of reusable content, skills inventory of employees, customer projects, technologies used, skills required and much more.
Implementation of a Knowledge Graph
Let’s look at the implementation of a knowledge graph from the ground up using the Google Drive API and Neo4j Python driver.
This is only a piece of a larger end-to-end knowledge management solution, which would include*:
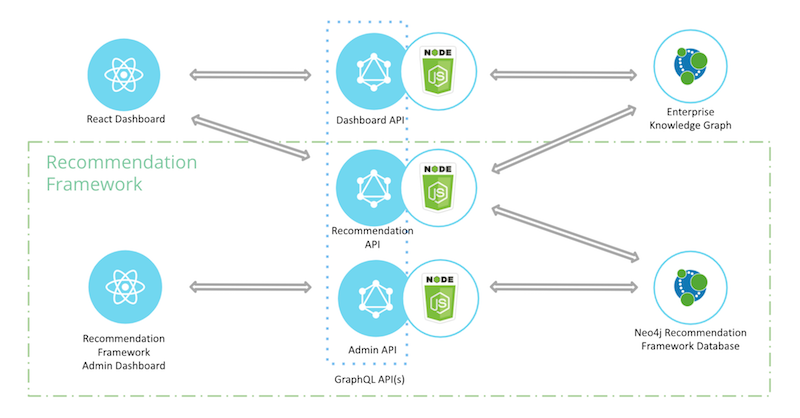
- Enterprise Knowledge Graph: the repository of enterprise knowledge (this is what we will cover in this post)
- GraphQL API: to sit on top of the knowledge graph
- React App: for non technical end users to explore the graph
- Recommendation Engines: to leverage graph patterns/algorithms and serve up relevant content to be displayed within the React app
Here’s an architecture diagram containing the above components:
*Note: some prior experience with Neo4j and/or Python will be helpful as you follow along, but definitely isn’t required!
Connecting to the Google Drive API
Thankfully, when working with Drive documents, Google provides a robust set of APIs to extract document metadata.
In order to access documents through the Google Drive API, you will need either an API key, Google service account or OAuth integration. For our purposes, leveraging a service account makes the most sense. A service account is a special Google account, kind of like an email, but is primarily used to facilitate communication between a non-human entity (i.e. piece of code) and Google Drive APIs.
Basically, you just share documents or folders with your service account, connect to the Google Drive API using your service account credentials, and then access the documents via your API connection. Pretty simple!
Here is a diagram showing the basic architecture of what we’ll be building and where the service account fits in.

As you can see, the connection between the “Python Script” and the “Google Drive API” is facilitated by the Google service account.
To create a service account visit https://console.cloud.google.com and navigate to “APIs & Services” → “Credentials” and click “Create Credentials” at the top of the page. Once you create your service account you can download the “credentials.json” file.
This will live in your project directory and allow you to connect to the drive API via your newly created service account.
Time to start coding!
Document Extraction
First, you’ll need to install the Neo4j driver for Python and some Google libraries using pip3.
pip3 install neo4j pip3 install google-api-python-client google-auth-httplib2 google-auth-oauthlib
Once these are installed, create a Python file and name it something like “neo4j-google-drive.py”. Inside this file, import the libraries you just installed and set up your Drive API connection as shown below.
from apiclient import discovery
from google.oauth2 import service_account
from neo4j import GraphDatabase, basic_auth
SCOPES = "https://www.googleapis.com/auth/drive,https://www.googleapis.com/auth/drive.file".split(",")
credentials = service_account.Credentials.from_service_account_file(
"./credentials.json", scopes=SCOPES
)
service = discovery.build("drive", "v3", credentials=credentials)
Now that is all set up, we can start calling some Google Drive API methods.
Let’s set up an extraction function. This function will take as arguments the API connection (aka “service”) and the ID of a Google Drive shared drive. We’re interested in shared drives for a few reasons.
First of all, shared drives often contain lots of documents and these documents are usually of interest to broad groups of people within the organization. Second, we’re not looking to invade people’s personal drives. Therefore, focusing on larger shared drives (usually owned by a team, aka marketing team, engineering team etc.) that many people already have access to ensures we’re only grabbing public content.
Note: this means that the below code will need to be modified if you want to extract documents from normal Google Drive folders.
Here’s the stub of the file extraction function:
# retrieve all files in specified shared drive
def get_all_files_from_shared_drive(service, driveId):
# init function variables
all_files = []
page_token = None
while True:
if not page_token:
break
print("extracted ", len(all_files), " files")
return all_files
The flow here will look like this:
- Initialize an empty list called ‘all_files’. This will later be populated with Python dictionary objects representing drive files.
- Initialize a “page_token” variable. Each time we ask for files we’ll get a page token if there is another page of results. We then supply that page token to the next API call to tell it that we want the next page of files. If there are no more results (i.e. no page token), we break the loop and return the list of files.
Now lets update our function skeleton with the actual Drive API call as shown below:
# retrieve all files in specified shared drive
def get_all_files_from_shared_drive(service, driveId):
# init function variables
all_files = []
page_token = None
while True:
# init query params
params = {}
params[
"fields"
] = "nextPageToken, files(id, name, mimeType, fileExtension, webViewLink, webContentLink, iconLink, createdTime, modifiedTime, driveId, parents, trashed)"
params["spaces"] = "drive"
params["corpora"] = "drive"
params["driveId"] = driveId
params["supportsAllDrives"] = True
params["includeItemsFromAllDrives"] = True
params["q"] = "trashed = false"
if page_token:
params["pageToken"] = page_token
# call drive api
page = service.files().list(**params).execute()
files = page.get("files")
page_token = page.get("nextPageToken")
all_files.extend(files)
if not page_token:
break
print("extracted ", len(all_files), " files")
return all_files
And set up a main function to be invoked when we run the script:
if __name__ == "__main__": all_files = get_all_files_from_shared_drive(service, "YOUR SHARED DRIVE ID")
You can run the script by typing python3 neo4j-google-drive.py in the terminal. Now we have a list of objects containing the fields specified by the “fields” value in the params object of our query.
It should look something like this:
[{id: "12345", name: "document1", mimeType: "application/json", ...}, {id: "23456", name: "document2", mimeType: "text/javascript", ...}, ...]
Next, let’s populate the graph!
Document Ingestion
Once you have a list of Drive files, there are a few ways to get them into Neo4j.
One way is to write them to a CSV file and then parse the CSV file to load the data. This seems kind of roundabout – and it is – but it also provides the added flexibility of being able to export the CSV files later, if needed.
For the sake of simplicity, I won’t go into the whole CSV writing/parsing process here and just assume you have a list of Google Drive documents (like the one above) ready to ingest into Neo4j.
Obviously, you’ll also need an empty instance of Neo4j running either on your local machine or on a server somewhere. If you need some help getting set up you can refer to the documentation.
Before we start writing Cypher to load our documents, let’s define a generic utility function to abstract away our interaction with the Neo4j driver. This handles authenticating with the database, opening and closing the driver and running the provided function.
def ingest_data(func, data):
driver = GraphDatabase.driver(
"YOUR_NEO4J_URI",
auth=basic_auth("YOUR_NEO4J_USERNAME", "YOUR_NEO4J_PASSWORD"),
)
with driver.session() as session:
session.write_transaction(func, data)
driver.close()
Next, let’s write our ingestion function. This contains a block of Cypher, which loops through the list of documents provided and creates nodes in the database.
def write_files(tx, files):
return tx.run(
"""
UNWIND {files} AS file
WITH file.id AS id, file.name AS name, file.fileExtension AS fileExtension,
file.mimeType AS mimeType, datetime(file.createdTime) AS dateCreated,
datetime(file.modifiedTime) AS dateLastModified, file.webContentLink AS webContentLink,
file.webViewLink AS webViewLink, file.iconLink AS iconLink, file.trashed AS trashed,
file.parents AS parents, file.driveId AS driveId
MERGE (f:DriveFile {id: id})
SET f.name = name, f.fileExtension = fileExtension, f.type = mimeType,
f.dateCreated = dateCreated, f.dateLastModified = dateLastModified, f.parents = parents,
f.iconLink = iconLink, f.driveId = driveId, f.trashed = trashed, f.source = 'drive', f.webViewLink = webViewLink
""",
files=files,
)
Next, let’s define a function to connect the drive document nodes together, creating a parent-child hierarchy. In other words, if we have a hierarchy that looks like this:
folder1 > folder2 > document
Inside Google Drive, we’ll get this:
(folder1)<-[:HAS_PARENT]-(folder2)<-[:HAS_PARENT]-(document)
Inside Neo4j.
Here’s the function:
def write_parent_rels(tx, files):
return tx.run(
"""
UNWIND {files} AS file
WITH file.id AS id, file.parents AS parentIds
UNWIND parentIds AS parentId
WITH id, parentId
MATCH (f:DriveFile {id: id})
MATCH (p:DriveFile {id: parentId})
MERGE (f)-[:HAS_PARENT]->(p)
""",
files=files,
)
Finally, we put it all together by adding to our main function:
if __name__ == "__main__": all_files = get_all_files_from_shared_drive(service, "YOUR SHARED DRIVE ID") ingest_data(write_files, all_files) ingest_data(write_parent_rels, all_files)
Voila! You should now have a graph of the shared drive you extracted in the previous section.
Your data model should now look something like this:

Extending the Data Model
While the above data model is interesting and quite accurately depicts the structure of a Google Drive shared drive, it isn’t as useful as it could be. In order to derive more utility from our graph let’s add another entity, n-grams.
N-grams are groupings of words, typically used in natural language processing (NLP) scenarios. They exclude indefinite articles, punctuation, numbers, low relevancy terms and are an alternative to manual tagging.
Used in a knowledge graph, n-grams are a good way of quickly scoring document similarity and identifying key terms. For our purposes here, we will calculate unigrams (single words) and bigrams (two words) based on document titles. There are obviously more sophisticated ways to do this, but this is a quick and dirty way of getting n-grams into the graph and connecting up our document nodes.
First, let’s install NLTK. Run the following commands in your terminal:
pip3 install nltk python3 -m nltk.downloader stopwords
NLTK stands for “Natural Language ToolKit” and contains functions we’ll need to create n-grams.
Import the following at the top of the Python script:
import re import nltk import string from nltk.corpus import stopwords from nltk.tokenize import sent_tokenize, word_tokenize
Next, let’s define a function to clean up the raw text we get from Google Drive. This function will take a string as an argument (in this case ,a document title) and lowercase it, remove punctuation, remove stopwords (things like “a”, “an”, and “to”), remove file extensions, etc.
def normalize_and_tokenize_text(str):
lower_case = str.lower()
tokens = re.findall(r"[^W_]+|[.,!?;]", lower_case)
tokens = list(filter(lambda token: token not in string.punctuation, tokens))
stop_words = list(stopwords.words("english"))
file_extensions = ["docx", "txt", "xlsx", "pdf", "zip", "tar", "mp4", "pptx", "gz"]
low_relevancy_terms = ["any terms you think don't hold much meaning in your corpora"]
stop_words = stop_words + file_extensions + low_relevancy_terms
tokens = [t for t in tokens if not t in stop_words]
tokens = [t for t in tokens if len(t) > 1]
return tokens
Next, let’s define the functions to actually calculate the n-grams.
def get_unigrams_from_dict_list_column(dict_list, col, primary_key):
unigram_list = []
for d in dict_list:
tokens = normalize_and_tokenize_text(d[col])
unigram_list.append({"id": d[primary_key], "type": "unigram", "ngrams": tokens})
return unigram_list
def get_bigrams_from_dict_list_column(dict_list, col, primary_key):
bigram_list = []
for d in dict_list:
tokens = normalize_and_tokenize_text(d[col])
bigrams = list(nltk.bigrams(tokens))
bigrams = list(" ".join(b) for b in bigrams)
bigram_list.append({"id": d[primary_key], "type": "bigram", "ngrams": bigrams})
return bigram_list
These will take as input our list of Drive documents from before, the key for the column we want to process and the key for the primary key/ID of the document record.
Putting it all together, we can calculate our n-gram lists by running the following:
unigrams = get_unigrams_from_dict_list_column(list_of_drive_documents, "name", "id") bigrams = get_bigrams_from_dict_list_column(list_of_drive_documents, "name", "id")
Now that we have our lists of unigrams and bigrams, all we need to do is ingest them into Neo4j:
def write_ngrams(tx, ngrams):
return tx.run(
"""
UNWIND {ngrams} AS ng
WITH ng.id AS id, ng.type AS type, ng.ngrams AS ngrams
UNWIND ngrams AS ngram
WITH ngram, id, type
MATCH (f:DriveFile {id: id})
MERGE (n:NGram {ngram: ngram})
ON CREATE SET n.type = type
MERGE (f)-[:HAS_NGRAM]->(n)
""",
ngrams=ngrams,
)
Finally, write to your graph by updating your main function to resemble the following:
if __name__ == "__main__": all_files = get_all_files_from_shared_drive(service, "0ALB-g6xFmljEUk9PVA") ingest_data(write_files, all_files) ingest_data(write_parent_rels, all_files) unigrams = get_unigrams_from_dict_list_column(all_files, "name", "id") bigrams = get_bigrams_from_dict_list_column(all_files, "name", "id") ingest_data(write_ngrams, unigrams) ingest_data(write_ngrams, bigrams)
Your data model should now look like this:
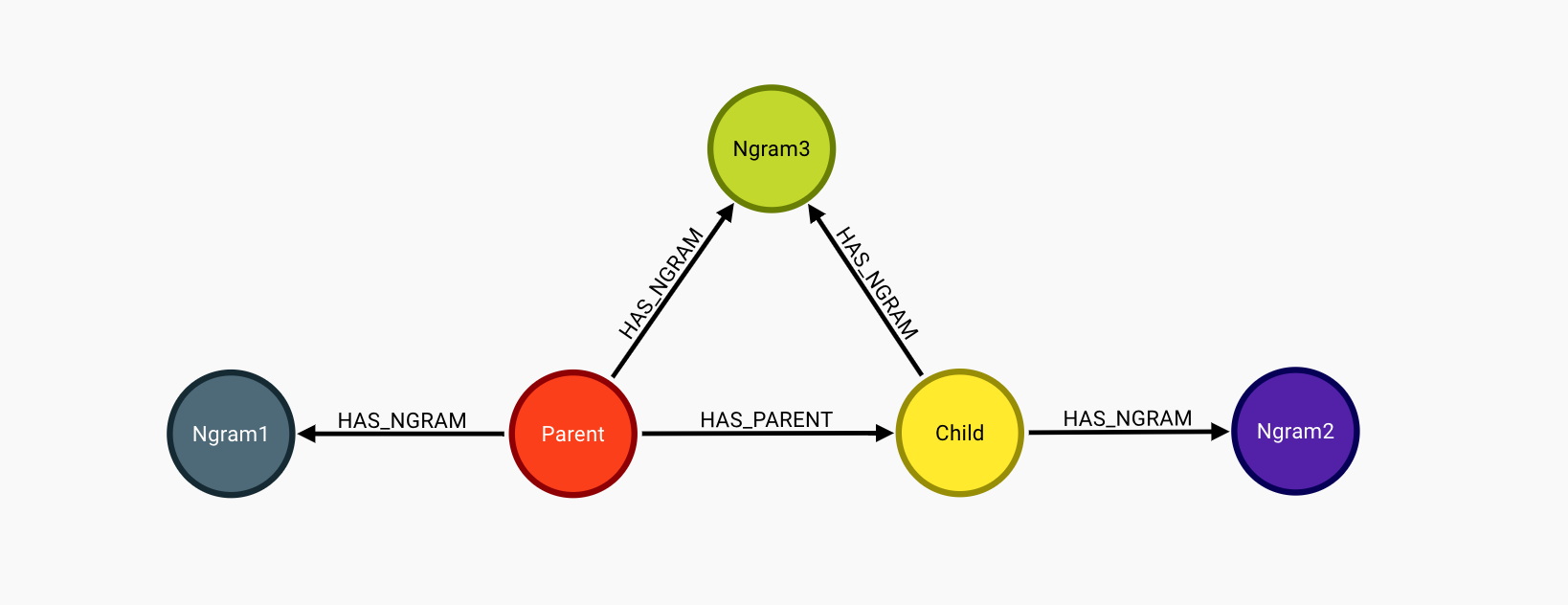
With the addition of n-grams, we can now analyze the connectedness of documents, discern the popularity/importance of certain key words/phrases, and even calculate the similarity of different documents based on the number of n-grams they share and their position in the document hierarchy (remember the :HAS_PARENT relationship).
We could even extend the data model further by including user revision history. The Google Drive API provides an endpoint that returns a list of users who have modified a particular document.
Hopefully, this gets you thinking about what kind of insights a knowledge graph might uncover for your organization.
We’re actually currently utilizing a system similar to the one outlined in the “Implementation of a Knowledge Graph” section internally at Neo4j, which we also make available to customers.
Here are a couple of screenshots of the completed application:
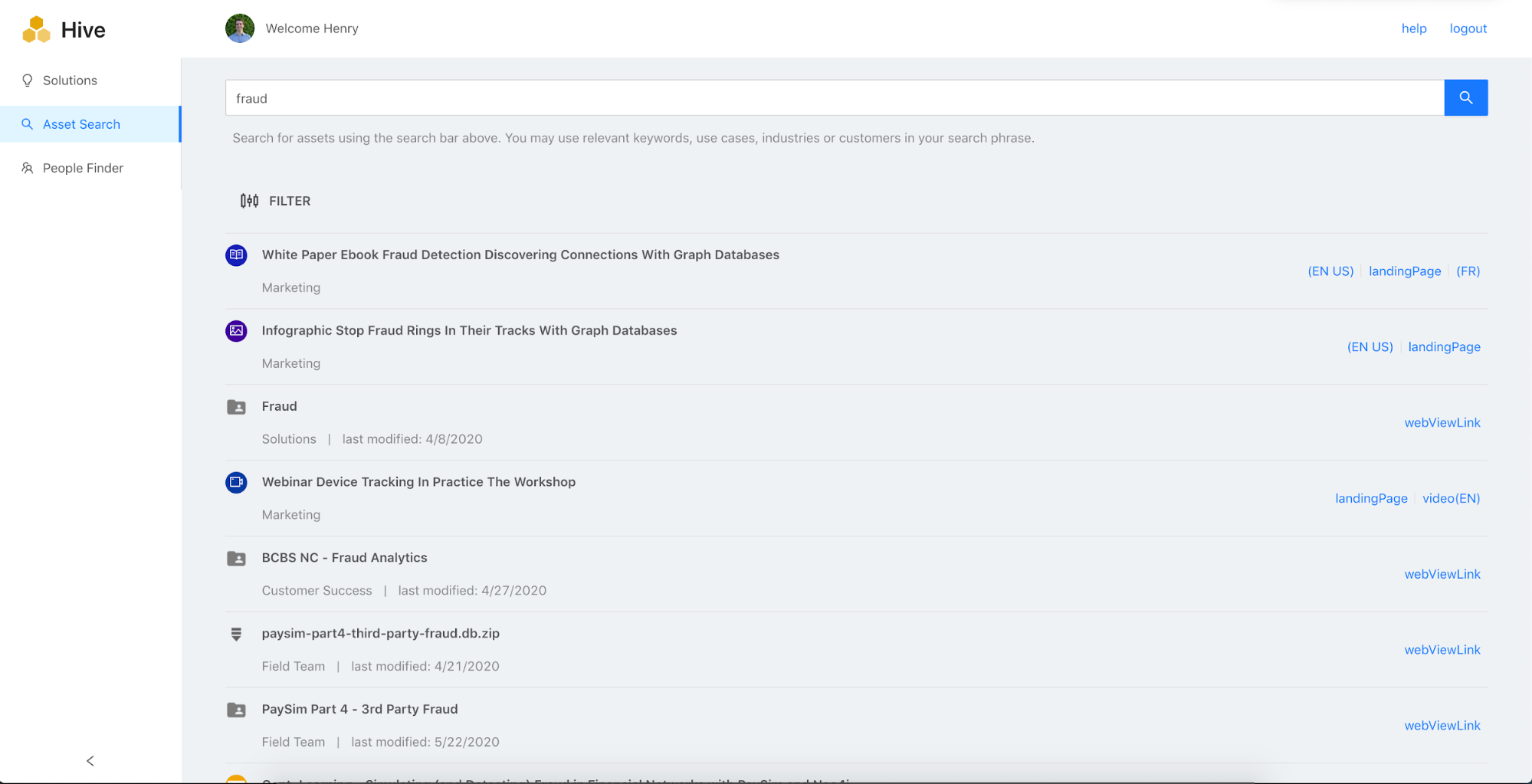

Feel free to reach out to solutions@neo4j.com for a demo of the complete solution!
Look out for additional data sources and/or other pieces of the complete solution to be covered in future blog posts!
Share Article



Explore
Related Articles




How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs

