Building a Graph of History with The Codex

Visiting Researcher, Digital Academy of the University of Mainz
11 min read

Presentation Summary
The Codex attempts to deeply integrate text and data by building a graph network of people, places, events and concepts embedded in texts.
In this post, Iian Neill, Visiting Researcher at the Digital Academy of the University of Mainz, will go over some of the Codex’s core entities. He will go over how a standoff-property text editor allows the graph meta-model to be built from multidimensional annotation, whereon NLP services are incorporated to drive semantic search. Conclusively, Neill will discuss the various Neo4j-based tools he has employed to advance his technology.
Full Presentation: Building a Graph of History with The Codex
My name is Iian Neill. I am an ASP.NET developer, and have used Neo4j for a few years. I’m also a visiting researcher at The University of Mainz in Germany. I’d like to thank Neo4j for the opportunity to talk about Codex, specifically the Text-as-a-Graph approaches I’ve been exploring.
What is Codex?
Codex is a Text-as-a-Graph solution, whose aim is to achieve the deep integration of text and data. Deep integration sounds a bit grand, but we’re basically trying to leverage the power of the graph to bring insights into entities within a text, and more importantly, between hundreds or thousands of texts.
The approach I take is to manage what I call standoff property documents linked to graph entities. The graphic below is an example of a text I’ve entered within a specially built editor. This enables visualization of complicated annotations and interactions with the graph.
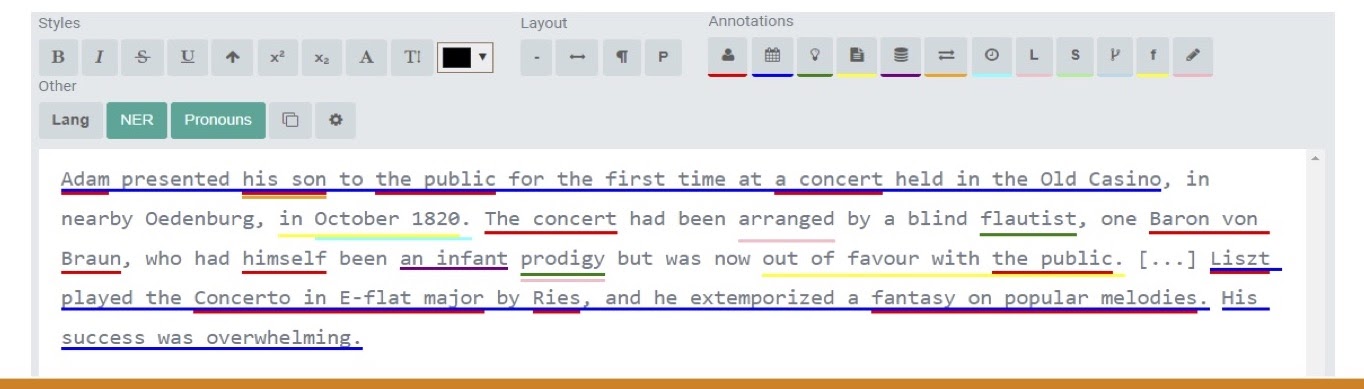
Behind all of this is a graph metamodel, where entities are built up and defined by composition from a collection of statements in meta-relations. The whole system is easily extensible; you can add annotation types to the editor and also build entities separately from the editor. It’s bidirectional.
As we can see in this text example above, text annotations are high-resolution and multidimensional, which means they overlap. This way, you can look for connections between entities that overlap the same region of text – it’s not just in a single dimension.
Obviously, Neo4j is the driving factor in the technology behind this. It’s what enables us to find insights into these documents and entities. On top of that, I use the Neo4j-Client API, which is in .NET. The API was developed by Redify and is maintained by Chris Skardon, a great Neo4j contributor.

On top of that, I’ve built a number of extension and helper methods, which create almost a mini domain-specific language. It helps me deal with some of the more visually complicated Cypher expressions. And this is all connected to ASP.NET MVC. I also need to interface the modals, and forms are drawn by Knockout, as well as a custom standoff property text editor that I’ve created.
These are the main entities in Codex, but for this talk, I’ll only look at the ones highlighted in red below. These are the main properties of the entities. We essentially have our texts, which are text nodes, and we have our standoff properties, which are standoff property nodes. These standoff property nodes are our interface between our text and graph entities.

Text as a Graph
There are various ways of doing the Text-as-a-Graph-Approach, but essentially at this point in time, it usually deals with a text that’s being broken up into tokens. These tokens are then represented as a linked list in the graph, such as annotations or nodes, which link to a single word or to a range of words.
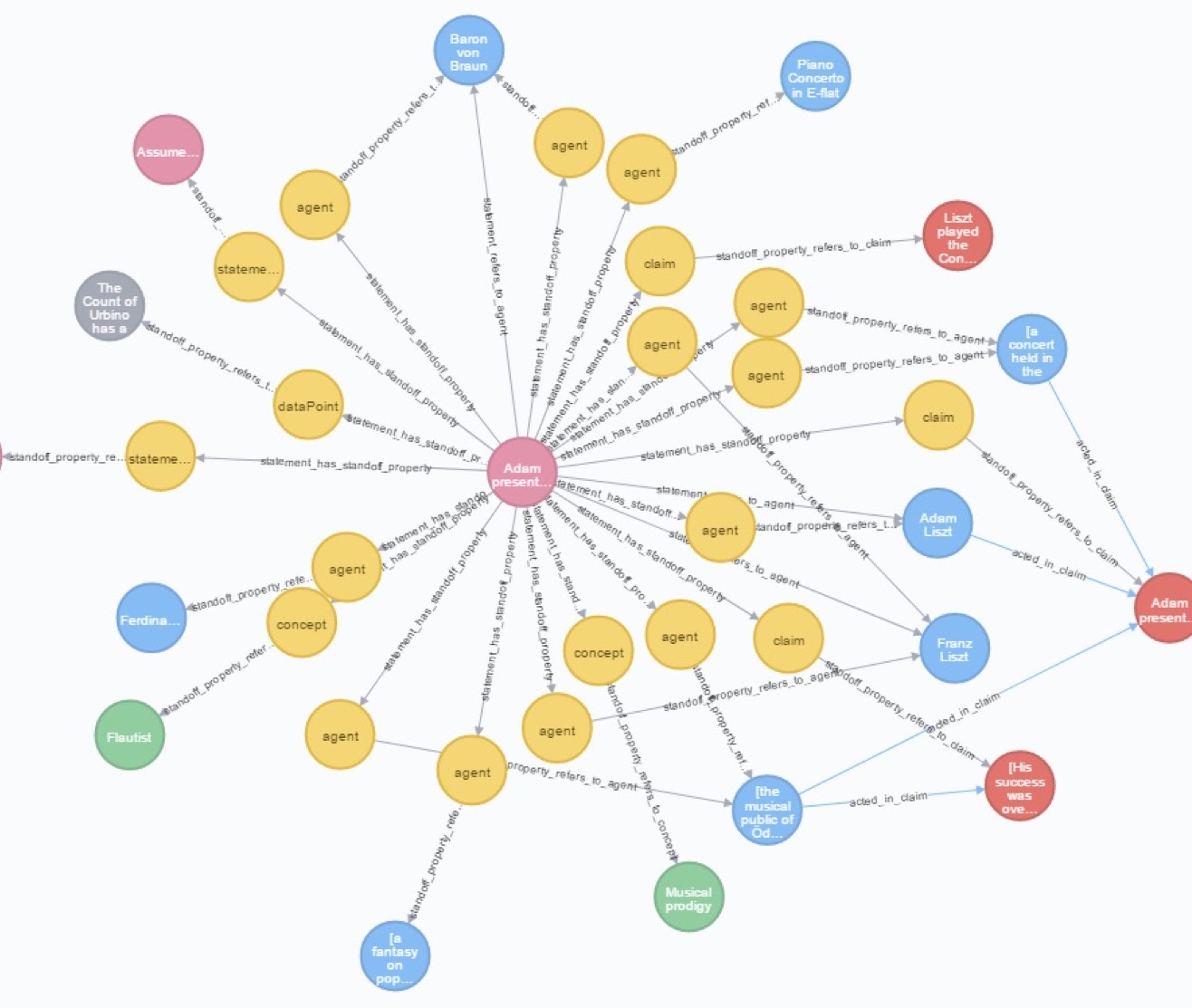
I’ve taken a different approach with standoff properties. Using standoff properties, you can map not to the token, but rather map to between a character. But, you can still represent and have multidimensional overlapping annotations like you would with Text-as-a-Graph.
The point of text to graph is to fully annotate a text. The idea is that the XML – a format used in the humanities for representing manuscript documents and capturing annotations and meanings – is fine for many cases. But, when it comes to annotating the full meaning of a text, you’ll find that texts are hierarchical in the same way that XML is hierarchical, meaning they cross boundaries, lines and paragraphs. Therefore, you need a system that can easily map across these boundaries.
XML Overlap
Here I’ll quickly illustrate what happens when you try and annotate something with XML. In XML and HTML, a range is represented by a node or an element within, for example, a document object model. When you want to cross something, you have to split them.
This is fairly understandable as HTML or XHTML. We’ve got a text and various annotations – a bold annotation, an italics annotation – and we can see that the text lines up in a containment way. This is understandable: there’s no overlap, nothing complicated.
We can annotate within the bold tag here, so within the bold tag, we can make something italicized. Now we’re starting to lose some of the readability of the text stream, but it’s still fairly manageable.

But, when we start to cross our annotations or cross our streams, we get into really broken XML. This XML would require special handling to export it as a readable text stream for further use, say in natural language processing (NLP), text analytics or vector semantics.
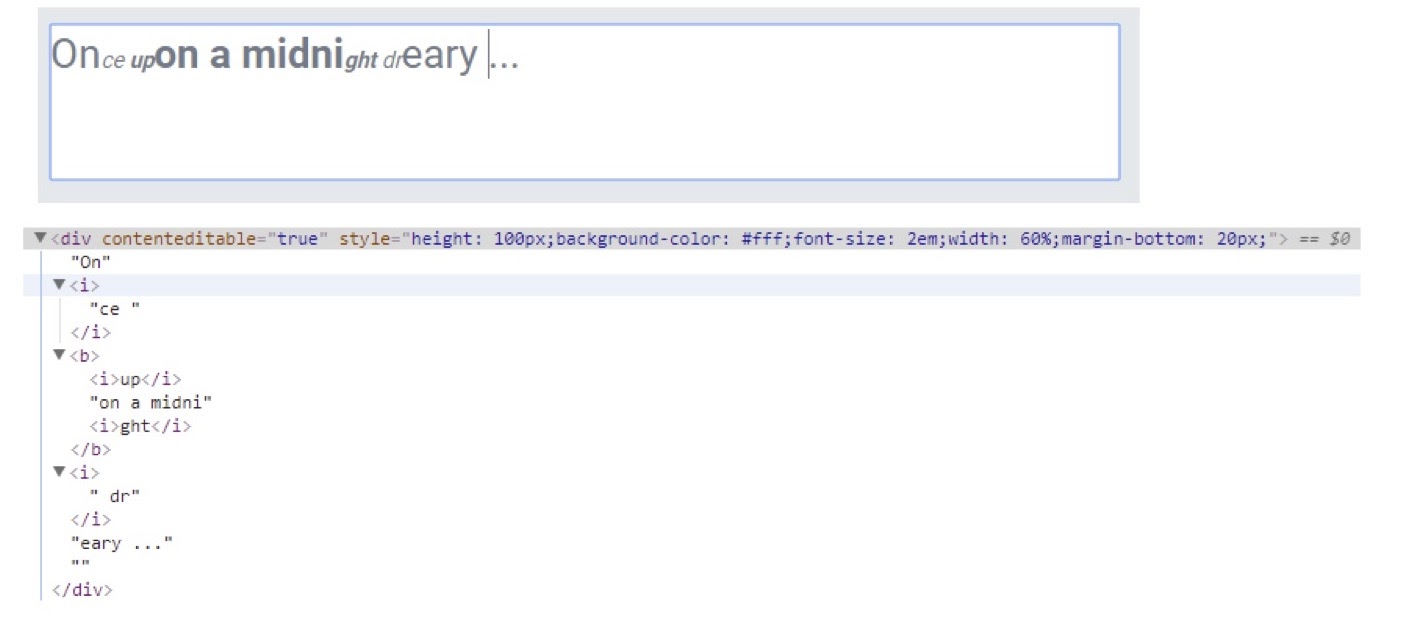
This is also not very manageable within your own system. If you wanted to search within your texts or compare things within a text, you’re now having to write complicated XPath and XML expressions to make sense of this fragmented structure, which has been created by quite a simple use case.
Standoff Properties & Property Graph
I came across the solution to this through a very simple data structure called a standoff property. Essentially, a standoff property contains a start index, an end index and a type. These indices are character positions within the text, and the type is the name of the annotation itself.
Earlier, we saw how we had bold and italics, which are stylistic annotations that would be the annotation type. The beauty of standoff properties is that they’re stored externally from the text stream, which is left in a plain format. Therefore, you have plain text with no markup, no XML, no markdown, absolutely nothing – completely readable by human beings. From here, you can submit it to a natural language service. But, the annotations are represented as an array of standoff properties.
Since you’re dealing with indices and character positions, you can also annotate. Your annotations can be inside a word, which you can’t do with Text-as-a-Graph. As I mentioned before, Text-as-a-Graph is at the level of the word token. You can also annotate a single character, and even annotate between characters to insert a footnote number, for example.
Addressing a text with annotations is quite a powerful ability. The annotation layers themselves can be filtered; you can export a single layer if you’re able to define a layer, say as all italicized text, everything mentioning people, places or syntax information. You can do all of these things using a simple Javascript filter, for example if you were only interested in a particular slice of these annotations. This would be quite difficult in XML.
Of course, standoff properties support multidimensional queries across overlapping annotations and layers. In the graph, we can do graph queries across multidimensional annotations.
Below, we have a bit of Cypher. This is a representation of the scheme of our standoff property graph. I’ve described what a standoff property is, which is the description of an annotation within certain indexes in a text, but we still need to see how this is used in a graph.

On the left, we have a Text node, which for the most part just contains the raw text. Then, we have a Standoff property node, which contains, as I mentioned, a start index, an end index and a type. It has a few other properties, such as attributes and so on, which are essentially optional properties.
We can see a relationship between the text and the standoff property, a simple one of ownership. The text has a standoff property, and we can also see that the standoff property can refer to something else.
In my system, I have a node called an agent, which is the term I use to indicate any kind of entity – a person, place, concept, whatever you like. On the right of the graph, we can see that Standoff can optionally refer to an agent. Once we get into the agent, we’re getting into the graph metamodel.
These other relationships show that you can use standoff properties in a graph way within themselves. For example, you could say that a standoff property is a subset of another standoff property. If you wish to have XML containment, where one element contains another element, you can represent these ideas within standoff properties as well.
Meta-Relations
I’ll briefly cover some of the other chief entities we have in the system because they’re the glue that holds these texts together. One of the concepts is what I call a meta-relation. I call it that because it’s like a standard Neo4j relationship in some ways, but takes a different approach. It’s a bit like the Marvel Comics approach of dynamically creating relationships, but there’s one extra component to it.
A meta-relation is a kind of relationship that the user can create within Codex, which is primarily how relationships are built within Codex. You can create it from within the text document itself.
For example, below we have Michelangelo, who is the dear friend of Giorgio Vasari. This was a relationship I saw mentioned in the text itself. I could create that in-line using a modal window.

When you create a meta-relation, you specify the two sides of it, for example, parent_of or child_of.You do that because you want to dynamically create it, but also because it’s the way it’s represented in the graph model.
Below, we simply have an Agent who’s related to a MetaRelation hypernode.

This means that we can have a parent or a child here; they’re both related to the same thing, but we can retrieve them both at the same time. We don’t have to know what direction the arrow is going. We can simply say that we want to get the parent/child situation.
Because we’re now dealing with a graph here, we’re dealing with an Agent who is_related to a MetaRelation, and this MetaRelation node is related to this MetaRelation type, which is where you define both sides of the relationship.
We could also link this meta-relation type of schema to a concept, which is a hierarchically organized collection of tags in the system. I don’t want to call it an ontology, because that implies a sort of top-down structure, but it’s a very free-floating way of building up hierarchical structures within Codex.
For example, a Java programmer is a subset of a programmer. Both of those nodes would be concepts related by a subset_of. Here, we could say that this meta-relation type is a type of parent/child relationship. We can then go further than that and say this concept – parent/child – is a subset of family relationships, which is a subset of genetic relationships.
The power of this is that you can now query the graph with higher-order relationships. Think about all the different kinds of relationships that are actually grouped. You have parent or child, sibling or marriage, son-in-law, mother-in-law, etc. You can start to think of them as higher-order relationships – a set of family relationships or friendship relationships.
This technique is particularly useful when dealing with, for example, historical documents where you’re looking for all of Michelangelo’s family, all of his professional connections, all of his friends. From there, you can run a query that gets you that information in one go.
Statements
The other important element is statements, which enable you to create relationships between multiple entities within a text.
A simple way of thinking about this is as an event. Say Michelangelo went to Rome with Leonardo, his nephew. You’d have Michelangelo, Leonardo and Rome as Agents that are all related to a central activity, which is arriving at a place. You might have a Time as well, so you can represent that below.

The statement schemer allows you to capture in a simple but quite an ostensible way, we can capture quasi-grammatical relationships. Here, we’ve got a subject and object, but we can also have things like at, with and according-to.
Aspect-Oriented Ontology
We normally represent the ontology or classification of something by a type. For example, Savonarola was a renaissance preacher, which is a type of preacher, which is a man.
But, this leaves out a lot of interesting details we have in historical documents that can be broken down into traits. Below, I’ve reused this statement concept to represent every statement about Savonarola, who is represented as a discreet trait. I call this approach an aspect-oriented ontology. You can think of it in Java or C# as being an aspect on the method or an interface that’s descriptive. Each of these things is an aspect or a trait.

So, we can see here that Savonarola, according to Landucci, is given a trait of a man of holy life and so on.
Neo4j-Client
I wanted to talk a bit about the technology side of all this. Neo4j-Client is a tool I’ve added to the system that has helped me interact fairly quickly. Neo4j-Client is a C# API that sits on top of the Neo4j driver. It allows you to switch between REST and BOLT seamlessly. It also provides a Cypher expression builder, which we can see below. Most of the functions are keywords.
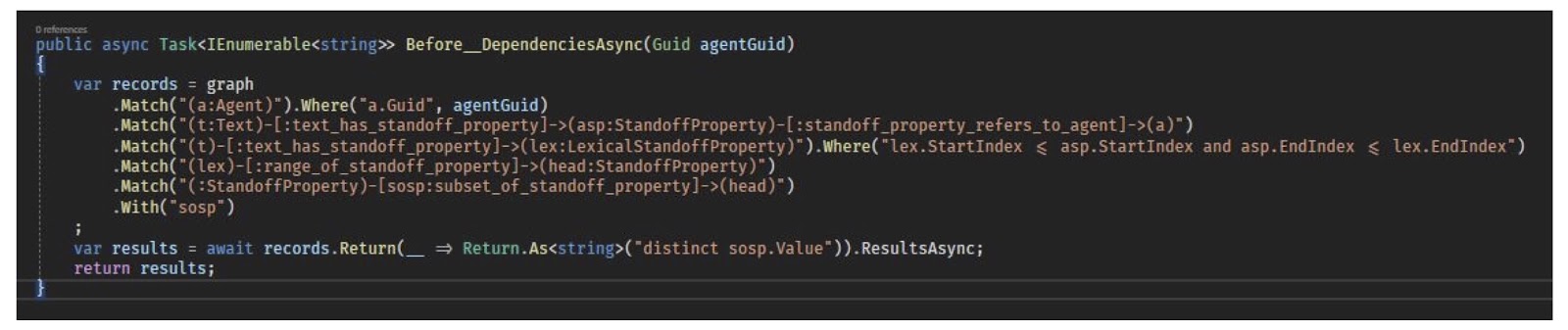
This handles safe parameterization of values and it has a very powerful deserializer that turns the results into complex objects.
Neo4j Client-Vector
This already is quite powerful and useful, but I found that as I was working it, I wanted a little distance from dealing with hard-coded text labels, so I created extension methods, which I call Neo4j Client-Vector and can be found on GitHub.
To do this, I created a vector-generic class, where you can represent a path in the system, such as a start node, an end node and a relationship. Basically, what it does is it generates the naming for you. For example, it generates the Cypher expression with the label names, relationships and so on.
You can see below that you don’t have to worry about what direction the arrow’s going in because that’s all contained within the vector class – it knows the direction of the relationship.

We don’t have to put any labels in here for any text or other relationships. In some cases, where we have a transitive relationship, we can even represent them without any relationships in between because the system understands that you’re focused on the nodes here.
I find that these extension methods have helped me iterate fairly quickly. I can rename relationships and labels, and can do so within the vector class without having to rewrite any Cypher. I find myself dealing simply with the Cypher node patterns, and I don’t have to worry about the visual noise of all the other aspects here.
There’s a couple of other useful, simple editions of this, which have allowed me to build dynamically driven form inputs. Rather than doing a complicated set of IF statements, we can control all of this within these extension methods:

Pagination
On top of that, I built a simple pagination library, which takes the Cypher query, and automatically skips and limits it for you. With a bit of reflection, it can work out the names of nodes and so on.
It also has a way of dealing with the OrderBy statement using these parameters, which – for me – is a more natural way of dealing with it.

In conclusion, with graph technology – specifically Neo4j-based tools – I’ve been able to integrate texts and data with Codex. I hope this post inspired you to utilize similar approaches in your graph solutions.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher


A workbench for teams to query, explore, and visualize graph data

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3

