


Editor’s Note: This presentation was given by Janos Szendi-Varga at NODES 2019 in October 2019.
Presentation Summary
In the last couple of years, chaos engineering has become very popular, with companies like Google and Netflix widely promoting it.
Chaos engineering allows for fewer surprise breakdowns in production, as well as foreknowledge of how to save the day when bad things happen. In this post, we’ll discuss the history of chaos engineering, how to conduct an experiment, the tools you can use and, ultimately, how to do chaos engineering if Neo4j is part of your application stack.
Full Presentation: Chaos Engineering with Neo4j
Hello everyone, my name is Janos Szendi-Varga. I’m an IT engineer based in Budapest, Hungary, though I just moved back from Abu Dhabi.
I work for Graph Coding, which is currently a one-man show. I wrote a Graph Technology Landscape blog post last year, which discussed market research on graph technologies. I’ve been in the Neo4j community since 2013, and serve as the main organizer of the Neo4j Budapest Meetup Group. You can reach me on Twitter and through email.
What Is Chaos Engineering?
When I was a kid, there was no Tik Tok and Instagram, so I usually broke things in order to explore my toys and see how they worked.
For example, my sister had a toy washing machine and I broke it. She was not happy. I got a plane set and a model train set from my parents. I also broke them. I had a remote-controlled bus with a wired controller. I broke it. Nobody was happy about that.
But through this, I learned a lot about electricity, mechanical engineering and communication. In the end, I managed to fix them all, soldered a longer cable for the bus and put lighting into the train. These toys became more reliable and usable.
Chaos engineering in IT does the same. It’s essentially the art of breaking things on purpose. In IT, we do this because we want to minimize downtime and series outage.
History of Chaos Engineering
First, a little history. There’s a gentleman named Jesse Robbins, a tech entrepreneur who founded the DevOps tool Chef, created a company to produce StarTrek-style Onyx communicators, invested in PagerDuty and started GameDay.
GameDay was a project that aimed to increase reliability by purposefully creating major failures on a regular basis. Basically, this guy was a practicing firefighter, and he brought this same concept into IT.
Later, this was adopted by many organizations, mainly the big ones: Google, Netflix, Facebook, Nokia and many others. Netflix was the one who started to promote it on the internet. Now, there are lots of articles and blog posts about chaos engineering.
In 2016, a Principles of Chaos Engineering website was created, which is the manifesto of chaos engineering. Later, O’Reilly published a book in this field, which is recommended if you’re interested in the chaos engineering business. Netflix also provided business cases on how to sell chaos engineering to your managers and convince them why it’s worth it to deal with it, and how it won’t actually cost more failures in production.
Chaos Engineering Experiment Steps
If you conduct a chaos engineering experiment, you should do one experiment at a time with the following steps:
- Define a steady state. This is the normal behavior of your system.
- Utilize both a control and an experimental group.
- Inject failures into the experimental group.
- Try to disprove the hypothesis that your system is resilient.
This might sound easy, but sometimes it’s not.
Execution Order
The Execution Order is how you’ll start your chaos engineering experiment.
First, one important distinction: What is the difference between testing and Chaos Engineering? When we test, we have a set of inputs and a set of outputs and try to verify the behavior of the system. However, in chaos engineering, most of the time we don’t know the output or behavior of our system. That’s the main difference.

Known Knowns are what you’re aware of and understand. But, the latter three in the list above can be really different. For example, if you set the time of the system of nodes differently or configure the header size, you’ll learn a lot and see unexpected behaviors.
In this way, Known Unknowns, Unknown Knowns, and Unknown Unknowns represent the scope of chaos engineering. The last category – Unknown Unknowns – are the most interesting and dangerous ones.
Define a “Steady State”
The first step is to have observability. This means that you should have metrics about your systems. Typical Neo4j use cases include recommendation engines, fraud detection, identity management and master data management (MDM). For these cases, you need to define these metrics. One metric that matters (OMTM) is some kind of startup word phrase, but it’s useful when you want to define your steady state, or normal behavior.
For example, if you have a webshop where most of the traffic is coming from Google, you’ll still be fine if the recommendation system is down; your business will still run. But at Netflix, where 80 to 90 percent of the traffic comes from the recommendation system, it’s business-critical that your recommendation system remain functional at all times. In the same way, you need to define metrics that you’ll consider as normal behavior.
Fraud detection is the same. If your fraud detection system is down, maybe your business is still going but you’re losing a lot of money, so it’s better to test all of your systems with chaos engineering in order to glean the weaknesses of your system, which is the goal of chaos engineering.
In practice, how do we do this with Neo4j? Earlier this year, I worked on a blog post with my friend Miro Marchi at Grafana discussing how to put Neo4j Graph Prometheus and Grafana together. With enterprise edition, you can publish the metrics of your Neo4j, define your custom metrics and display it in a Grafana dashboard. This is a good way to start obtaining observations of your Neo4j cluster, or of your applications and Neo4j cluster together on the same dashboard.

Breaking Things
The second step is to break things, which is where things get exciting. Below is just a general list of what could be wrong during your daily operation, but if you spend enough time in IT then you will have ideas of what could go wrong in a production system.

For example, you can simulate failure in your datacenter or switch down some Kafka topic. All these experiments are about trying to inject failure.
However, the most important advice is that you should always have a big red button to stop this experiment at any time. It’s not a funny story, but in 1996, Chernobyl was a resiliency test on what would happen if we cut the power source of the coolants, and we know what resulted there. Though most of us work in less critical or dangerous environments, we should still experiment carefully and stop if there’s a big problem.
Tools
Here are some tools you can use. Particularly, the Chaos Monkey tool from Netflix is an interesting one. If you have a localized environment, then I’d recommend using this. It will randomly kill an instance, after which you can check if your system is still operational or not.
There’s also this Mangle tool from VMware. The Chaos Monkey for Spring Boot tool from Codecentric is very useful as well. In most cases, if you have Neo4j then your application is likely a Spring Boot application. You can then put them into the main run, and based on your code, it will inject Latency Assault, Exception Assault, AppKiller Assault, Memory Assault, allowing you to control your chaos engineering experience. Here’s also a conference talk on how to use Grafana.
Chaos in Neo4j
What about chaos in your Neo4j environment? When you monitor Known Known elements, you should monitor your applications as well; if you put something in Neo4j, the result might lie in your applications or end-users, so you should monitor it all carefully.
Below is a list of ideas of what you should try when you try to break your Neo4j system:

Earlier, we mentioned how you can kill one instance from the cluster, which is a typical simulation. Moreover, if you use a Kafta connector or something similar, you can experiment with what’ll happen if you break the ingestion system, thereby testing whether it’s actually resilient.
Injecting some latency between services is also possible with the aforementioned tools, and might create a few surprises as well.
Last, Failure Injection Testing (FIT) is my favorite. It randomly causes faults in your Neo4j transactions or applications.
If you use Neo4j on bare metal – not in Docker containers – then you should manually handcraft solutions because you can’t use Chaos Monkey, but for failure injection, you can do the following things:
For example, I tried randomly causing faults with the APOC trigger function. It wasn’t the best because it’s hard to implement exceptions or errors, but you can still try using it for delay.
If you use the GraphAware Framework, then you can use the Improved Transaction Event API. But, if you don’t have the GraphAware Framework, you can use the Neo4j low-level API, create an image extension and catch all your transactions. You can use the beforeCommit method and inject some exception or failure in your system.
Below is some code, but I’m not sure it is fully usable. This is the MyTransactionEventHandler class, which you can register as an unmanaged extension, use in the beforeCommit method and control exceptions based on your settings.
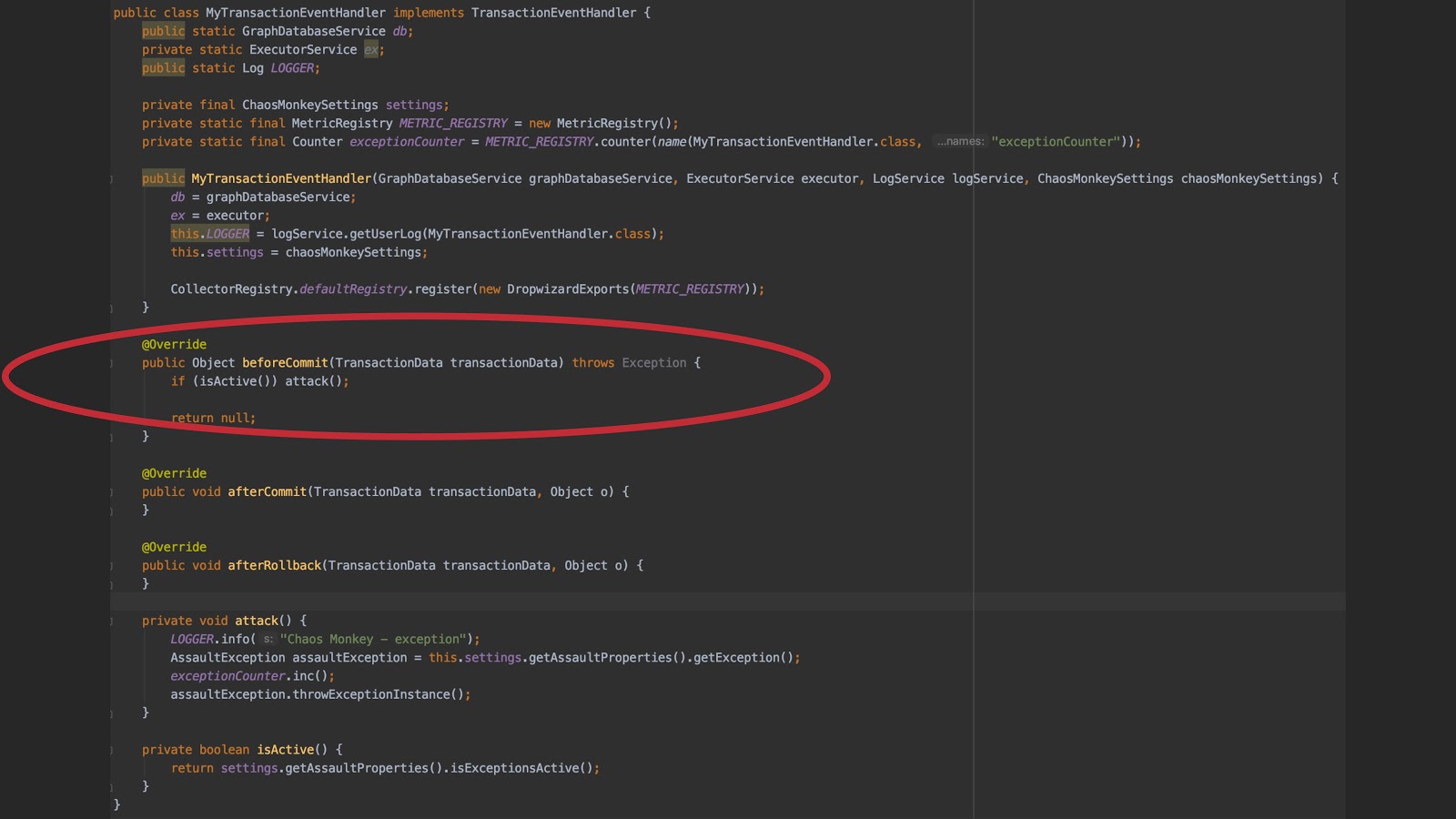
This is my experiment to inject faults into the system. After this step, you can see what happens in your application and obtain interesting results.
A best practice here is to use a metric registry. You can increase your exception counter for the injected exceptions, then see them on the Grafana Dashboard. You can stop it as well.
Below is the Dashboard I created. I got the idea from the blog post and Spring Boot Chaos Monkey tool.
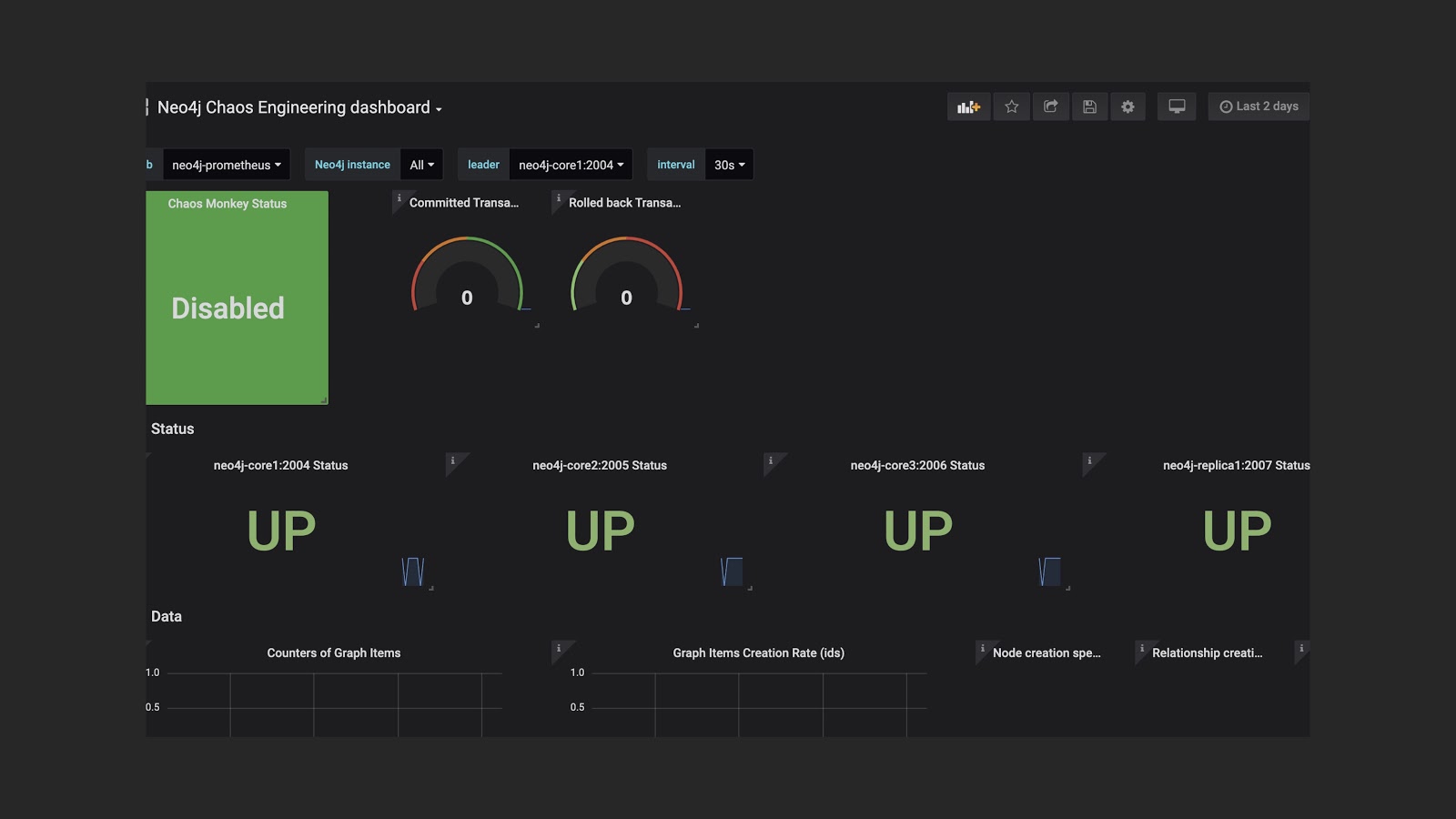
Here, I was able to start a Chaos Monkey experiment one at a time with simple steps, which allowed me to monitor the number of failures and the status of my cluster.
In conclusion, we hear about how much effort is put into making Neo4j resilient. Now, I think it’s time for us to play with it, try to break it and learn from it. This is the essence of what I wanted to share with you.
Share Article



Explore
Related Articles




10 Inspiring Projects to Spark Your NODES 2024 Presentation

